 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models
Jul 31, 2017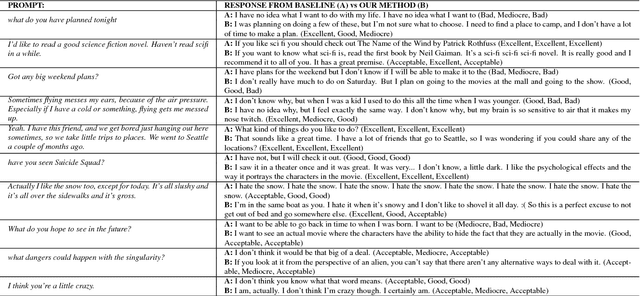

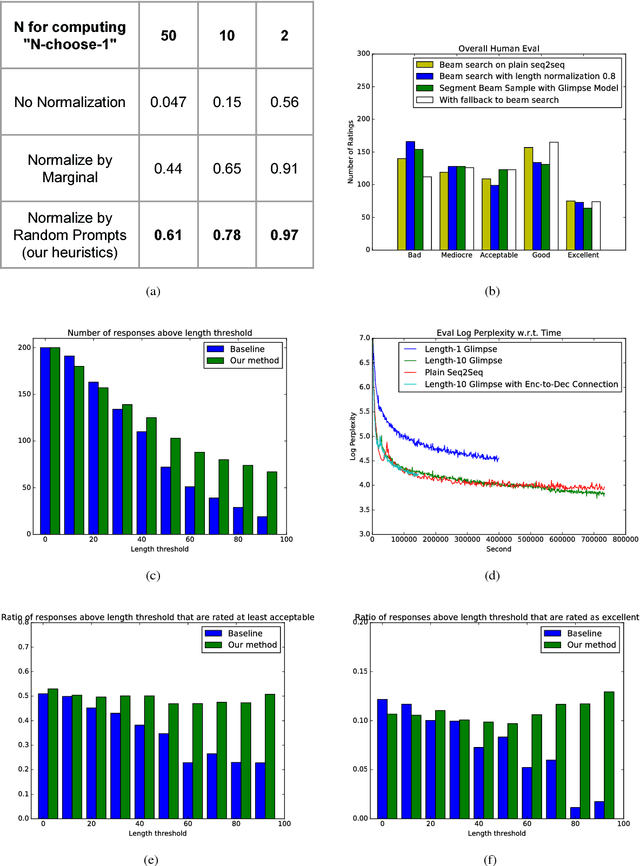
Sequence-to-sequence models have been applied to the conversation response generation problem where the source sequence is the conversation history and the target sequence is the response. Unlike translation, conversation responding is inherently creative. The generation of long, informative, coherent, and diverse responses remains a hard task. In this work, we focus on the single turn setting. We add self-attention to the decoder to maintain coherence in longer responses, and we propose a practical approach, called the glimpse-model, for scaling to large datasets. We introduce a stochastic beam-search algorithm with segment-by-segment reranking which lets us inject diversity earlier in the generation process. We trained on a combined data set of over 2.3B conversation messages mined from the web. In human evaluation studies, our method produces longer responses overall, with a higher proportion rated as acceptable and excellent as length increases, compared to baseline sequence-to-sequence models with explicit length-promotion. A back-off strategy produces better responses overall, in the full spectrum of lengths.
A Growing Long-term Episodic & Semantic Memory
Oct 20, 2016
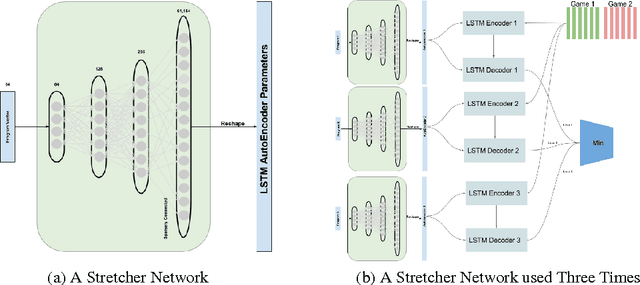
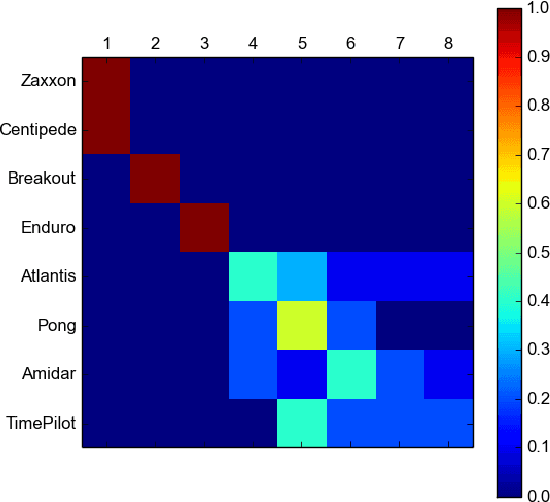
The long-term memory of most connectionist systems lies entirely in the weights of the system. Since the number of weights is typically fixed, this bounds the total amount of knowledge that can be learned and stored. Though this is not normally a problem for a neural network designed for a specific task, such a bound is undesirable for a system that continually learns over an open range of domains. To address this, we describe a lifelong learning system that leverages a fast, though non-differentiable, content-addressable memory which can be exploited to encode both a long history of sequential episodic knowledge and semantic knowledge over many episodes for an unbounded number of domains. This opens the door for investigation into transfer learning, and leveraging prior knowledge that has been learned over a lifetime of experiences to new domains.