 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Universal Sentence Encoder for Semantic Retrieval
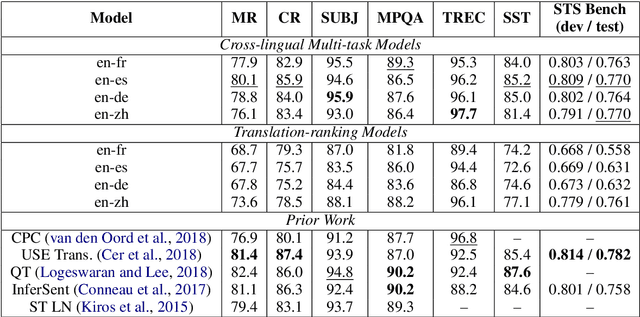
Jul 09, 2019We introduce two pre-trained retrieval focused multilingual sentence encoding models, respectively based on the Transformer and CNN model architectures. The models embed text from 16 languages into a single semantic space using a multi-task trained dual-encoder that learns tied representations using translation based bridge tasks (Chidambaram al., 2018). The models provide performance that is competitive with the state-of-the-art on: semantic retrieval (SR), translation pair bitext retrieval (BR) and retrieval question answering (ReQA). On English transfer learning tasks, our sentence-level embeddings approach, and in some cases exceed, the performance of monolingual, English only, sentence embedding models. Our models are made available for download on TensorFlow Hub.
Hierarchical Document Encoder for Parallel Corpus Mining
Jun 30, 2019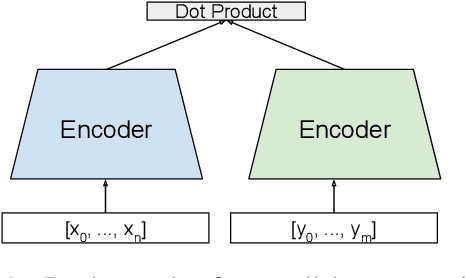
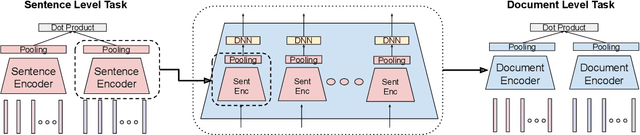
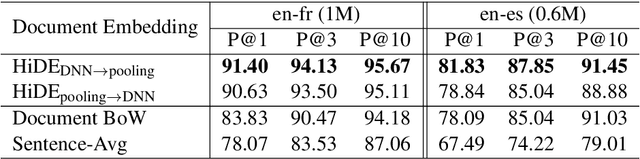
We explore using multilingual document embeddings for nearest neighbor mining of parallel data. Three document-level representations are investigated: (i) document embeddings generated by simply averaging multilingual sentence embeddings; (ii) a neural bag-of-words (BoW) document encoding model; (iii) a hierarchical multilingual document encoder (HiDE) that builds on our sentence-level model. The results show document embeddings derived from sentence-level averaging are surprisingly effective for clean datasets, but suggest models trained hierarchically at the document-level are more effective on noisy data. Analysis experiments demonstrate our hierarchical models are very robust to variations in the underlying sentence embedding quality. Using document embeddings trained with HiDE achieves state-of-the-art performance on United Nations (UN) parallel document mining, 94.9% P@1 for en-fr and 97.3% P@1 for en-es.
Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax
Feb 22, 2019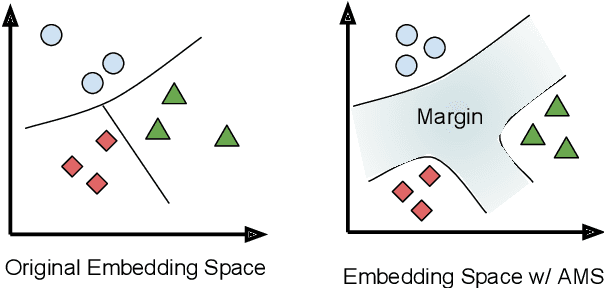


In this paper, we present an approach to learn multilingual sentence embeddings using a bi-directional dual-encoder with additive margin softmax. The embeddings are able to achieve state-of-the-art results on the United Nations (UN) parallel corpus retrieval task. In all the languages tested, the system achieves P@1 of 86% or higher. We use pairs retrieved by our approach to train NMT models that achieve similar performance to models trained on gold pairs. We explore simple document-level embeddings constructed by averaging our sentence embeddings. On the UN document-level retrieval task, document embeddings achieve around 97% on P@1 for all experimented language pairs. Lastly, we evaluate the proposed model on the BUCC mining task. The learned embeddings with raw cosine similarity scores achieve competitive results compared to current state-of-the-art models, and with a second-stage scorer we achieve a new state-of-the-art level on this task.
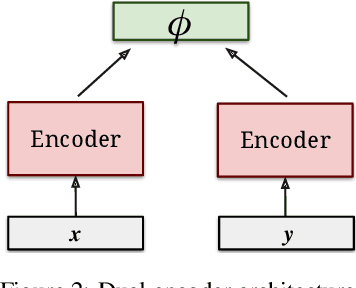
Learning Cross-Lingual Sentence Representations via a Multi-task Dual-Encoder Model
Oct 30, 2018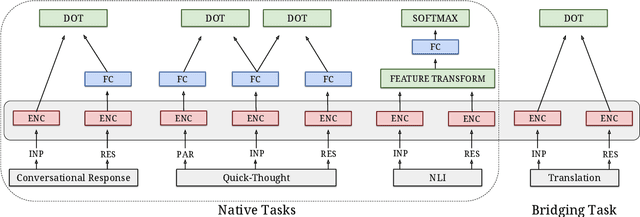
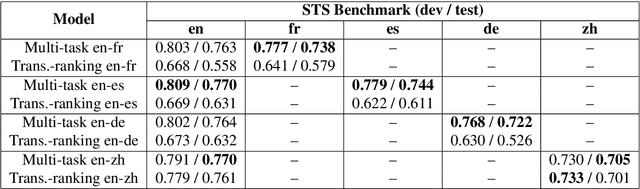
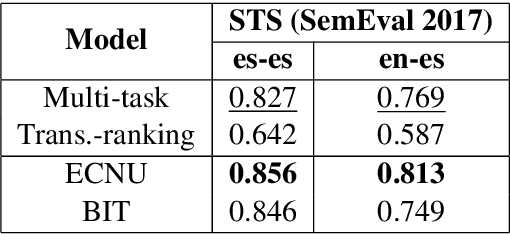
Neural language models have been shown to achieve an impressive level of performance on a number of language processing tasks. The majority of these models, however, are limited to producing predictions for only English texts due to limited amounts of labeled data available in other languages. One potential method for overcoming this issue is learning cross-lingual text representations that can be used to transfer the performance from training on English tasks to non-English tasks, despite little to no task-specific non-English data. In this paper, we explore a natural setup for learning cross-lingual sentence representations: the dual-encoder. We provide a comprehensive evaluation of our cross-lingual representations on a number of monolingual, cross-lingual, and zero-shot/few-shot learning tasks, and also give an analysis of different learned cross-lingual embedding spaces.
Effective Parallel Corpus Mining using Bilingual Sentence Embeddings
Aug 02, 2018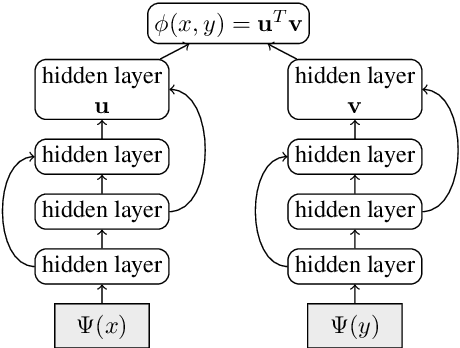

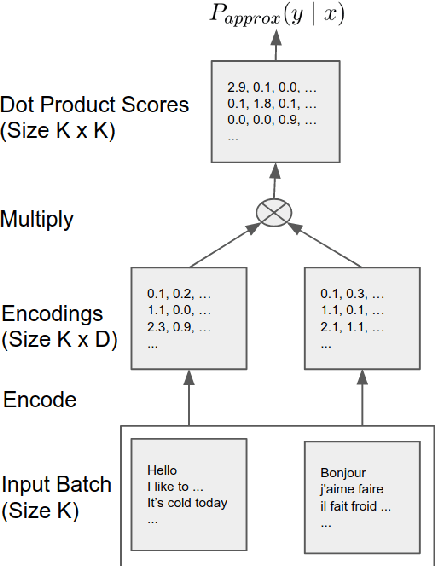
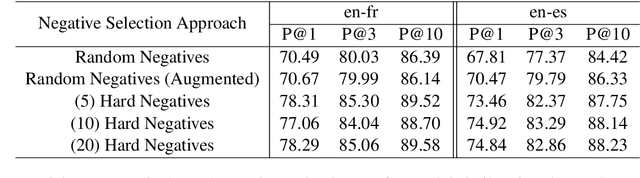
This paper presents an effective approach for parallel corpus mining using bilingual sentence embeddings. Our embedding models are trained to produce similar representations exclusively for bilingual sentence pairs that are translations of each other. This is achieved using a novel training method that introduces hard negatives consisting of sentences that are not translations but that have some degree of semantic similarity. The quality of the resulting embeddings are evaluated on parallel corpus reconstruction and by assessing machine translation systems trained on gold vs. mined sentence pairs. We find that the sentence embeddings can be used to reconstruct the United Nations Parallel Corpus at the sentence level with a precision of 48.9% for en-fr and 54.9% for en-es. When adapted to document level matching, we achieve a parallel document matching accuracy that is comparable to the significantly more computationally intensive approach of [Jakob 2010]. Using reconstructed parallel data, we are able to train NMT models that perform nearly as well as models trained on the original data (within 1-2 BLEU).
Learning Semantic Textual Similarity from Conversations
Apr 20, 2018
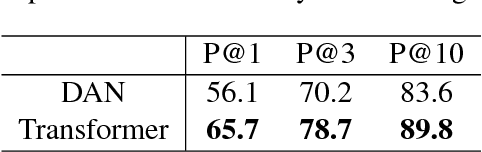
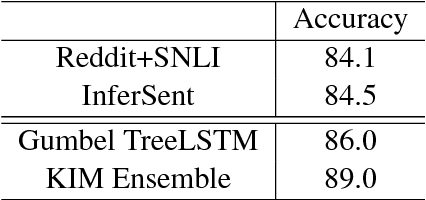
We present a novel approach to learn representations for sentence-level semantic similarity using conversational data. Our method trains an unsupervised model to predict conversational input-response pairs. The resulting sentence embeddings perform well on the semantic textual similarity (STS) benchmark and SemEval 2017's Community Question Answering (CQA) question similarity subtask. Performance is further improved by introducing multitask training combining the conversational input-response prediction task and a natural language inference task. Extensive experiments show the proposed model achieves the best performance among all neural models on the STS benchmark and is competitive with the state-of-the-art feature engineered and mixed systems in both tasks.
Universal Sentence Encoder
Apr 12, 2018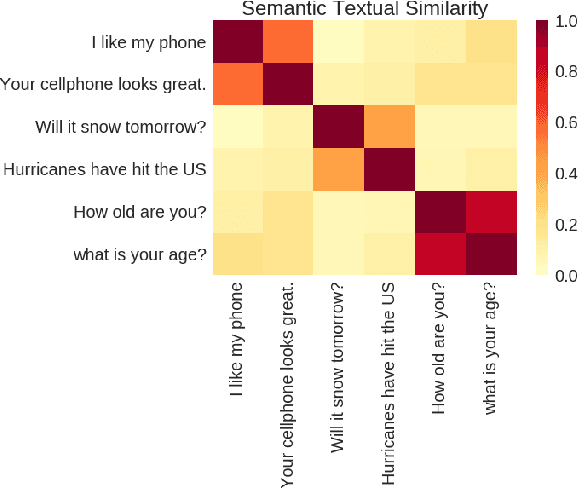
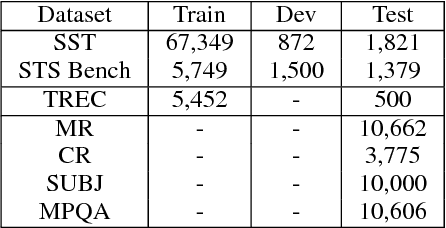
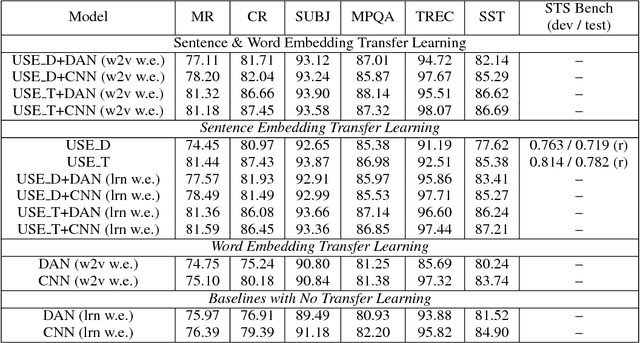
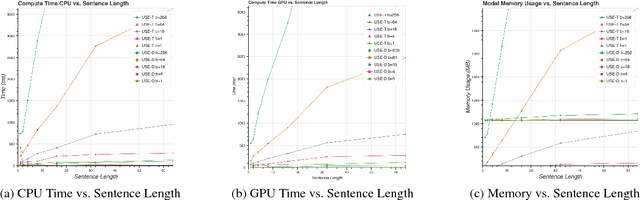
We present models for encoding sentences into embedding vectors that specifically target transfer learning to other NLP tasks. The models are efficient and result in accurate performance on diverse transfer tasks. Two variants of the encoding models allow for trade-offs between accuracy and compute resources. For both variants, we investigate and report the relationship between model complexity, resource consumption, the availability of transfer task training data, and task performance. Comparisons are made with baselines that use word level transfer learning via pretrained word embeddings as well as baselines do not use any transfer learning. We find that transfer learning using sentence embeddings tends to outperform word level transfer. With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task. We obtain encouraging results on Word Embedding Association Tests (WEAT) targeted at detecting model bias. Our pre-trained sentence encoding models are made freely available for download and on TF Hub.
Generating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models
Jul 31, 2017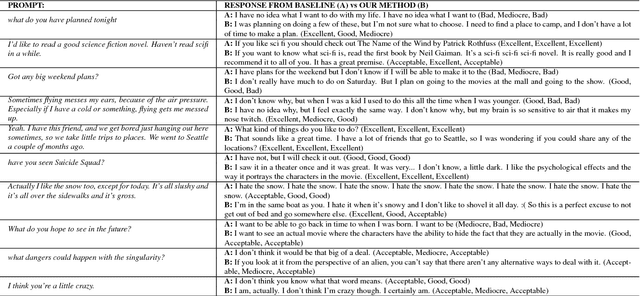

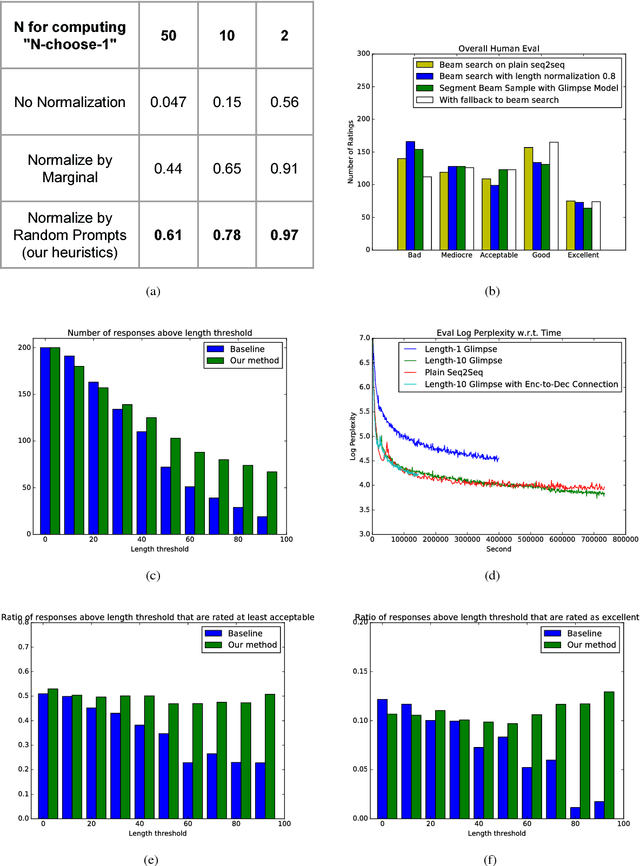
Sequence-to-sequence models have been applied to the conversation response generation problem where the source sequence is the conversation history and the target sequence is the response. Unlike translation, conversation responding is inherently creative. The generation of long, informative, coherent, and diverse responses remains a hard task. In this work, we focus on the single turn setting. We add self-attention to the decoder to maintain coherence in longer responses, and we propose a practical approach, called the glimpse-model, for scaling to large datasets. We introduce a stochastic beam-search algorithm with segment-by-segment reranking which lets us inject diversity earlier in the generation process. We trained on a combined data set of over 2.3B conversation messages mined from the web. In human evaluation studies, our method produces longer responses overall, with a higher proportion rated as acceptable and excellent as length increases, compared to baseline sequence-to-sequence models with explicit length-promotion. A back-off strategy produces better responses overall, in the full spectrum of lengths.
Efficient Natural Language Response Suggestion for Smart Reply
May 01, 2017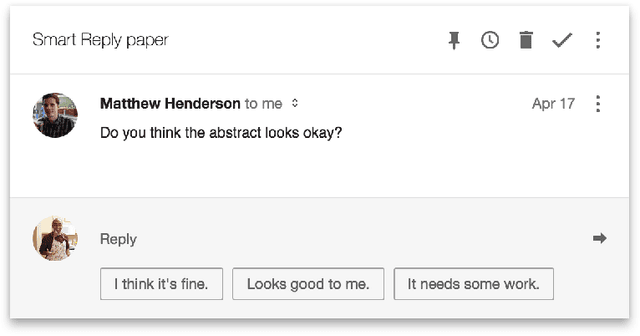

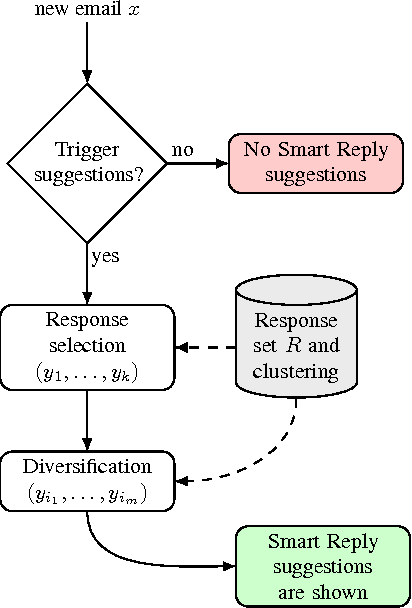
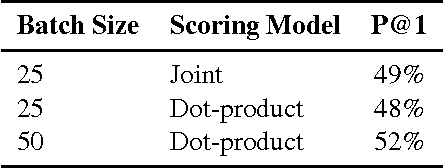
This paper presents a computationally efficient machine-learned method for natural language response suggestion. Feed-forward neural networks using n-gram embedding features encode messages into vectors which are optimized to give message-response pairs a high dot-product value. An optimized search finds response suggestions. The method is evaluated in a large-scale commercial e-mail application, Inbox by Gmail. Compared to a sequence-to-sequence approach, the new system achieves the same quality at a small fraction of the computational requirements and latency.
Conversational Contextual Cues: The Case of Personalization and History for Response Ranking
Jun 01, 2016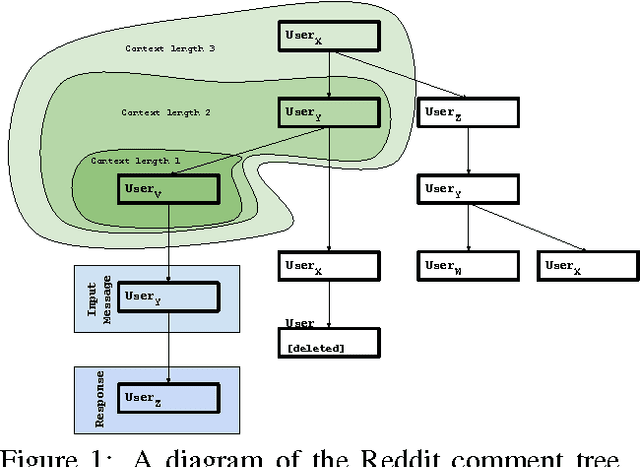
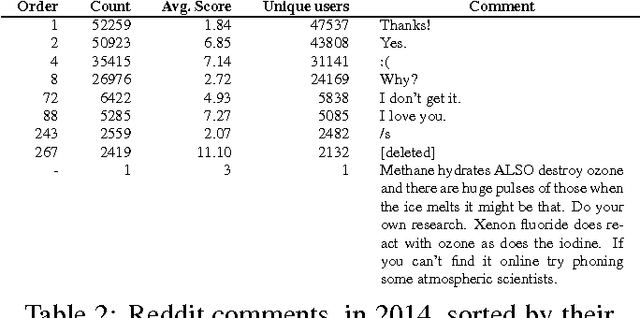
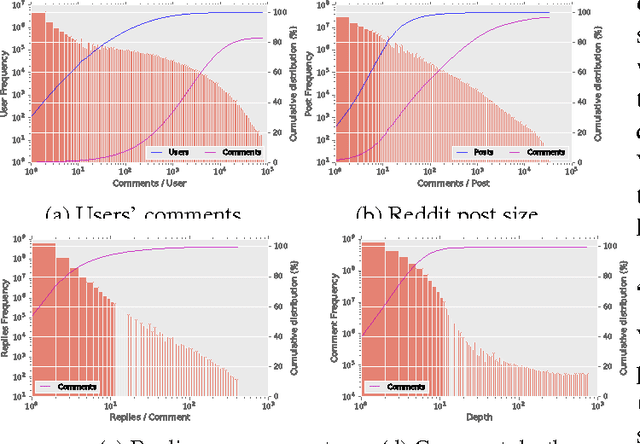
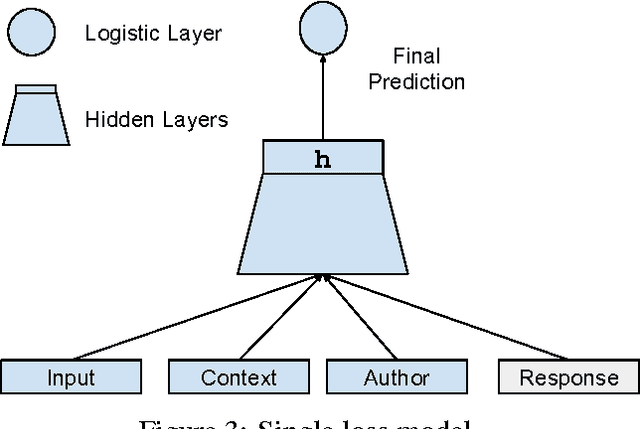
We investigate the task of modeling open-domain, multi-turn, unstructured, multi-participant, conversational dialogue. We specifically study the effect of incorporating different elements of the conversation. Unlike previous efforts, which focused on modeling messages and responses, we extend the modeling to long context and participant's history. Our system does not rely on handwritten rules or engineered features; instead, we train deep neural networks on a large conversational dataset. In particular, we exploit the structure of Reddit comments and posts to extract 2.1 billion messages and 133 million conversations. We evaluate our models on the task of predicting the next response in a conversation, and we find that modeling both context and participants improves prediction accuracy.