 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
Oct 23, 2020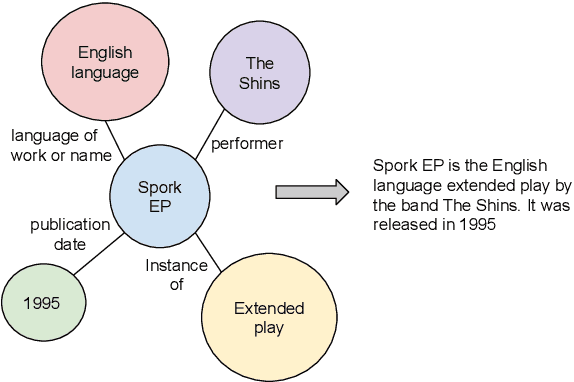

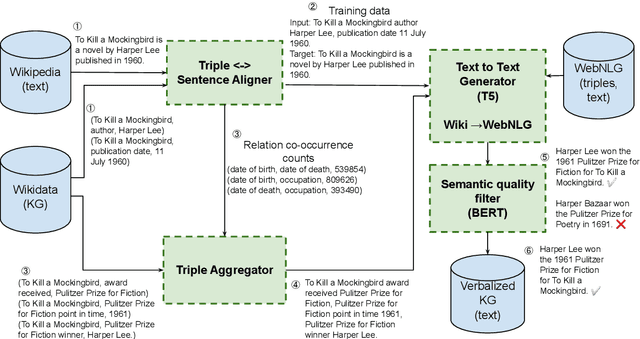
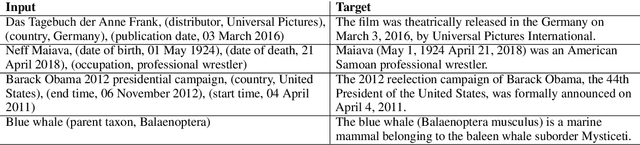
Generating natural sentences from Knowledge Graph (KG) triples, known as Data-To-Text Generation, is a task with many datasets for which numerous complex systems have been developed. However, no prior work has attempted to perform this generation at scale by converting an entire KG into natural text. In this paper, we verbalize the entire Wikidata KG, and create a KG-Text aligned corpus in the training process. We discuss the challenges in verbalizing an entire KG versus verbalizing smaller datasets. We further show that verbalizing an entire KG can be used to integrate structured and natural language data. In contrast to the many architectures that have been developed to integrate the structural differences between these two sources, our approach converts the KG into the same format as natural text allowing it to be seamlessly plugged into existing natural language systems. We evaluate this approach by augmenting the retrieval corpus in REALM and showing improvements, both on the LAMA knowledge probe and open domain QA.
Hierarchical Document Encoder for Parallel Corpus Mining
Jun 30, 2019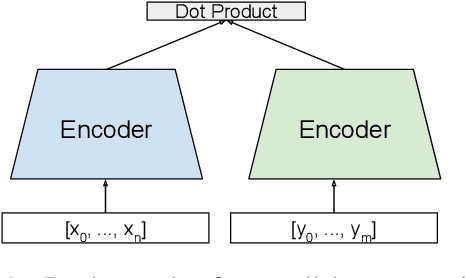
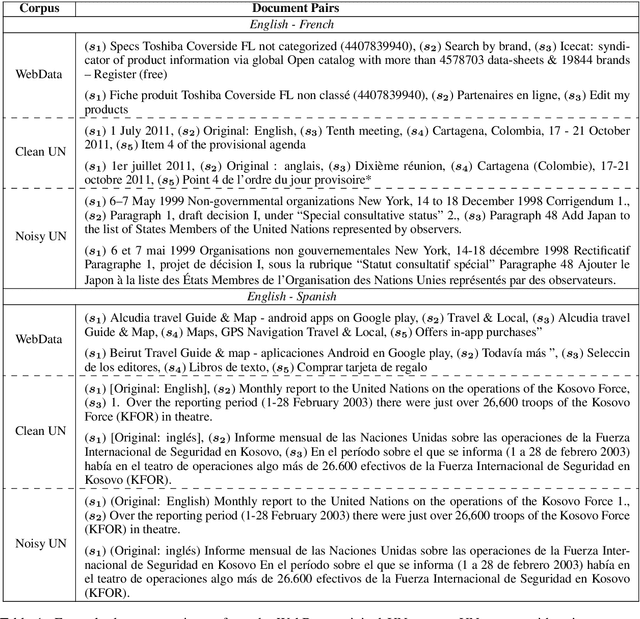
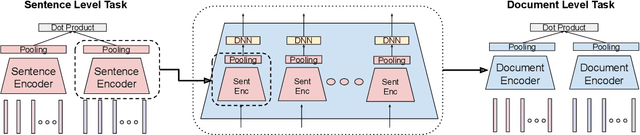
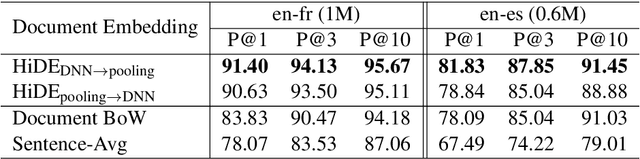
We explore using multilingual document embeddings for nearest neighbor mining of parallel data. Three document-level representations are investigated: (i) document embeddings generated by simply averaging multilingual sentence embeddings; (ii) a neural bag-of-words (BoW) document encoding model; (iii) a hierarchical multilingual document encoder (HiDE) that builds on our sentence-level model. The results show document embeddings derived from sentence-level averaging are surprisingly effective for clean datasets, but suggest models trained hierarchically at the document-level are more effective on noisy data. Analysis experiments demonstrate our hierarchical models are very robust to variations in the underlying sentence embedding quality. Using document embeddings trained with HiDE achieves state-of-the-art performance on United Nations (UN) parallel document mining, 94.9% P@1 for en-fr and 97.3% P@1 for en-es.
Effective Parallel Corpus Mining using Bilingual Sentence Embeddings
Aug 02, 2018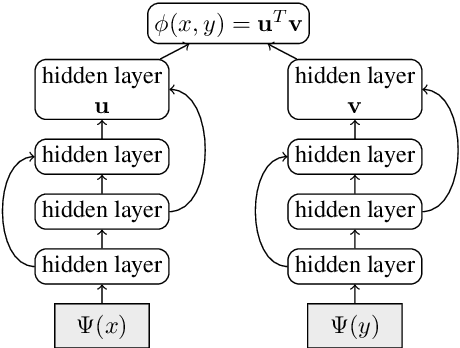

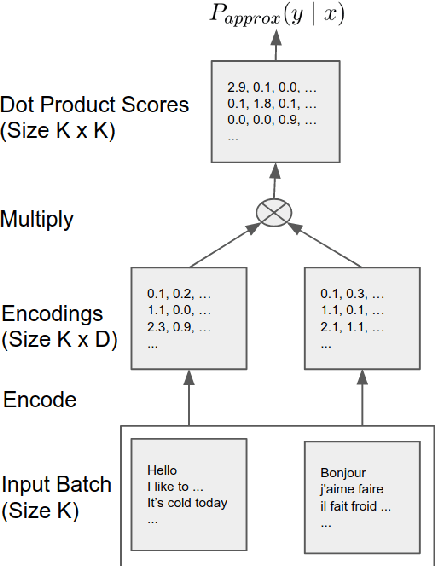
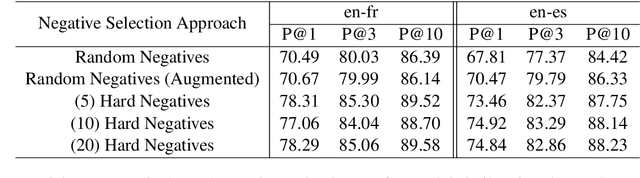
This paper presents an effective approach for parallel corpus mining using bilingual sentence embeddings. Our embedding models are trained to produce similar representations exclusively for bilingual sentence pairs that are translations of each other. This is achieved using a novel training method that introduces hard negatives consisting of sentences that are not translations but that have some degree of semantic similarity. The quality of the resulting embeddings are evaluated on parallel corpus reconstruction and by assessing machine translation systems trained on gold vs. mined sentence pairs. We find that the sentence embeddings can be used to reconstruct the United Nations Parallel Corpus at the sentence level with a precision of 48.9% for en-fr and 54.9% for en-es. When adapted to document level matching, we achieve a parallel document matching accuracy that is comparable to the significantly more computationally intensive approach of [Jakob 2010]. Using reconstructed parallel data, we are able to train NMT models that perform nearly as well as models trained on the original data (within 1-2 BLEU).
Learning Semantic Textual Similarity from Conversations
Apr 20, 2018
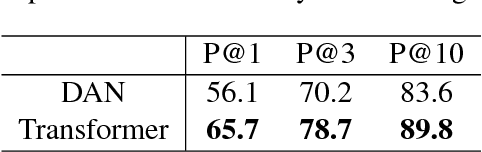
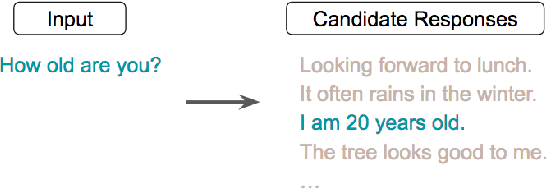
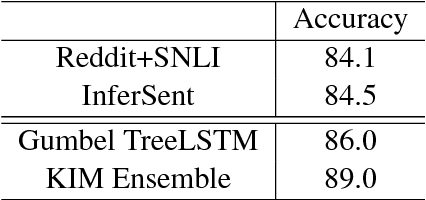
We present a novel approach to learn representations for sentence-level semantic similarity using conversational data. Our method trains an unsupervised model to predict conversational input-response pairs. The resulting sentence embeddings perform well on the semantic textual similarity (STS) benchmark and SemEval 2017's Community Question Answering (CQA) question similarity subtask. Performance is further improved by introducing multitask training combining the conversational input-response prediction task and a natural language inference task. Extensive experiments show the proposed model achieves the best performance among all neural models on the STS benchmark and is competitive with the state-of-the-art feature engineered and mixed systems in both tasks.