 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Textual Similarity from Conversations
Paper and Code

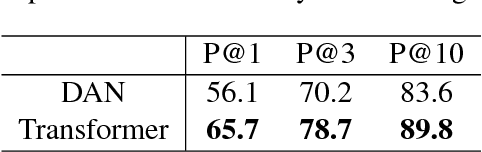
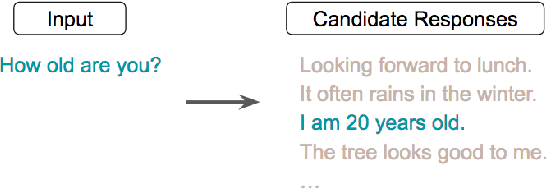
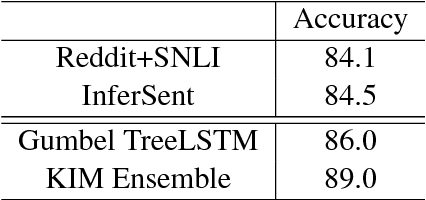
We present a novel approach to learn representations for sentence-level semantic similarity using conversational data. Our method trains an unsupervised model to predict conversational input-response pairs. The resulting sentence embeddings perform well on the semantic textual similarity (STS) benchmark and SemEval 2017's Community Question Answering (CQA) question similarity subtask. Performance is further improved by introducing multitask training combining the conversational input-response prediction task and a natural language inference task. Extensive experiments show the proposed model achieves the best performance among all neural models on the STS benchmark and is competitive with the state-of-the-art feature engineered and mixed systems in both tasks.