 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023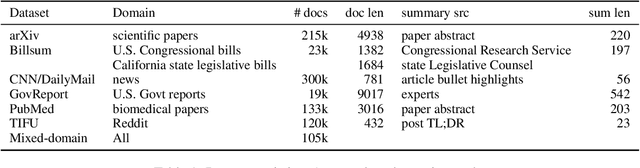

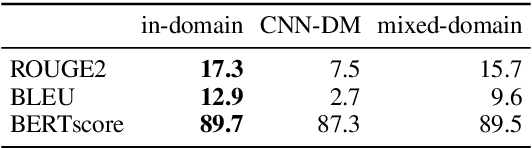
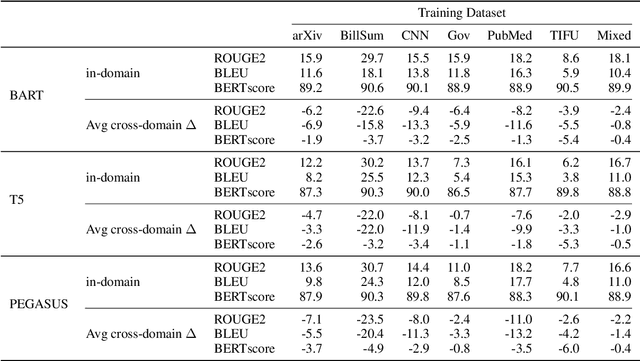
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.
Temporal Effects on Pre-trained Models for Language Processing Tasks
Nov 24, 2021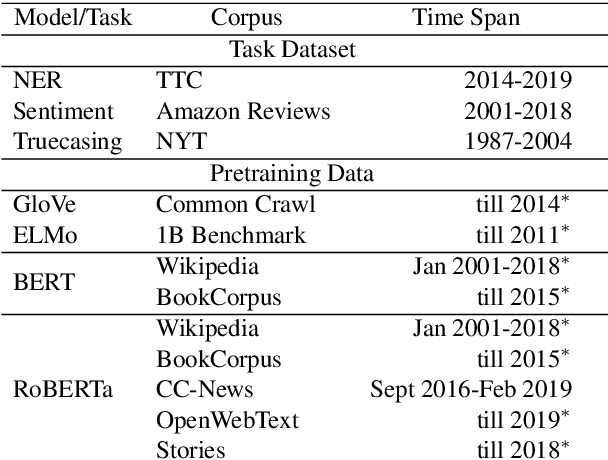

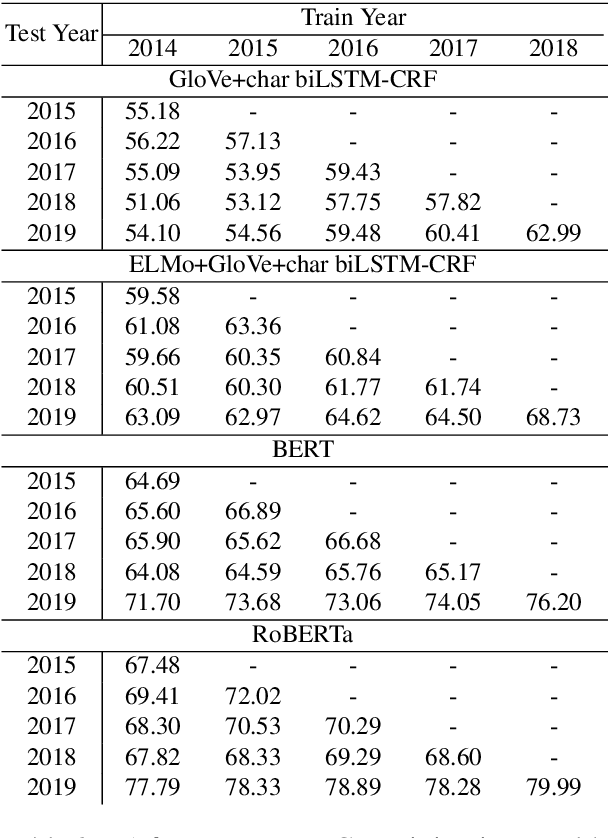

Keeping the performance of language technologies optimal as time passes is of great practical interest. Here we survey prior work concerned with the effect of time on system performance, establishing more nuanced terminology for discussing the topic and proper experimental design to support solid conclusions about the observed phenomena. We present a set of experiments with systems powered by large neural pretrained representations for English to demonstrate that {\em temporal model deterioration} is not as big a concern, with some models in fact improving when tested on data drawn from a later time period. It is however the case that {\em temporal domain adaptation} is beneficial, with better performance for a given time period possible when the system is trained on temporally more recent data. Our experiments reveal that the distinctions between temporal model deterioration and temporal domain adaptation becomes salient for systems built upon pretrained representations. Finally we examine the efficacy of two approaches for temporal domain adaptation without human annotations on new data, with self-labeling proving to be superior to continual pre-training. Notably, for named entity recognition, self-labeling leads to better temporal adaptation than human annotation.
From Toxicity in Online Comments to Incivility in American News: Proceed with Caution
Feb 06, 2021



The ability to quantify incivility online, in news and in congressional debates, is of great interest to political scientists. Computational tools for detecting online incivility for English are now fairly accessible and potentially could be applied more broadly. We test the Jigsaw Perspective API for its ability to detect the degree of incivility on a corpus that we developed, consisting of manual annotations of civility in American news. We demonstrate that toxicity models, as exemplified by Perspective, are inadequate for the analysis of incivility in news. We carry out error analysis that points to the need to develop methods to remove spurious correlations between words often mentioned in the news, especially identity descriptors and incivility. Without such improvements, applying Perspective or similar models on news is likely to lead to wrong conclusions, that are not aligned with the human perception of incivility.
Large Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
Oct 23, 2020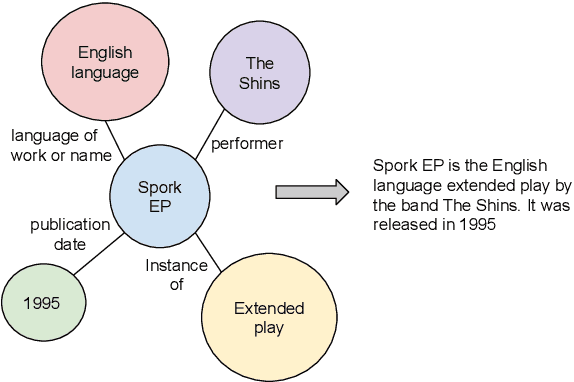

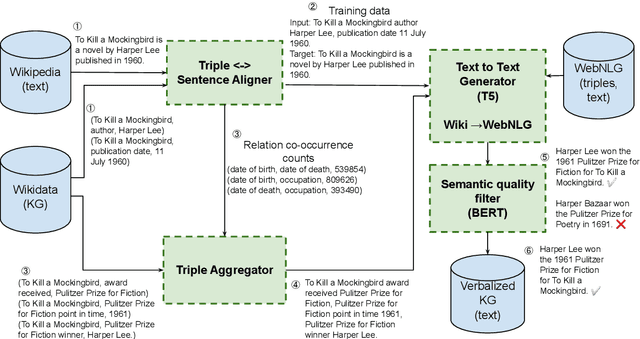
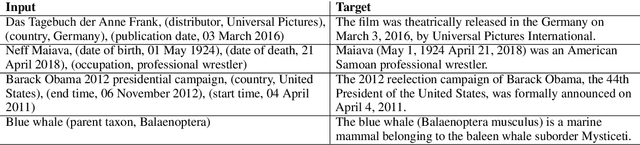
Generating natural sentences from Knowledge Graph (KG) triples, known as Data-To-Text Generation, is a task with many datasets for which numerous complex systems have been developed. However, no prior work has attempted to perform this generation at scale by converting an entire KG into natural text. In this paper, we verbalize the entire Wikidata KG, and create a KG-Text aligned corpus in the training process. We discuss the challenges in verbalizing an entire KG versus verbalizing smaller datasets. We further show that verbalizing an entire KG can be used to integrate structured and natural language data. In contrast to the many architectures that have been developed to integrate the structural differences between these two sources, our approach converts the KG into the same format as natural text allowing it to be seamlessly plugged into existing natural language systems. We evaluate this approach by augmenting the retrieval corpus in REALM and showing improvements, both on the LAMA knowledge probe and open domain QA.
Interpretability Analysis for Named Entity Recognition to Understand System Predictions and How They Can Improve
Apr 09, 2020



Named Entity Recognition systems achieve remarkable performance on domains such as English news. It is natural to ask: What are these models actually learning to achieve this? Are they merely memorizing the names themselves? Or are they capable of interpreting the text and inferring the correct entity type from the linguistic context? We examine these questions by contrasting the performance of several variants of LSTM-CRF architectures for named entity recognition, with some provided only representations of the context as features. We also perform similar experiments for BERT. We find that context representations do contribute to system performance, but that the main factor driving high performance is learning the name tokens themselves. We enlist human annotators to evaluate the feasibility of inferring entity types from the context alone and find that, while people are not able to infer the entity type either for the majority of the errors made by the context-only system, there is some room for improvement. A system should be able to recognize any name in a predictive context correctly and our experiments indicate that current systems may be further improved by such capability.
Entity-Switched Datasets: An Approach to Auditing the In-Domain Robustness of Named Entity Recognition Models
Apr 08, 2020
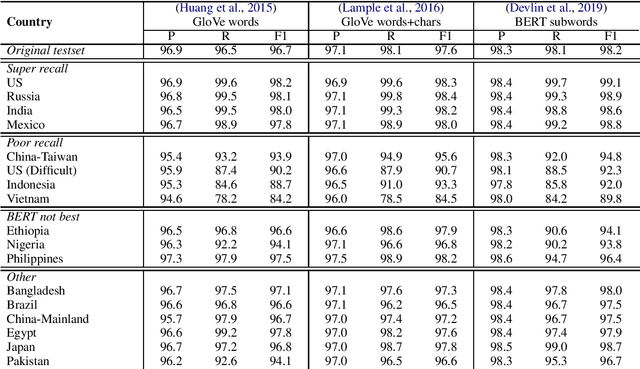

Named entity recognition systems perform well on standard datasets comprising English news. But given the paucity of data, it is difficult to draw conclusions about the robustness of systems with respect to recognizing a diverse set of entities. We propose a method for auditing the in-domain robustness of systems, focusing specifically on differences in performance due to the national origin of entities. We create entity-switched datasets, in which named entities in the original texts are replaced by plausible named entities of the same type but of different national origin. We find that state-of-the-art systems' performance vary widely even in-domain: In the same context, entities from certain origins are more reliably recognized than entities from elsewhere. Systems perform best on American and Indian entities, and worst on Vietnamese and Indonesian entities. This auditing approach can facilitate the development of more robust named entity recognition systems, and will allow research in this area to consider fairness criteria that have received heightened attention in other predictive technology work.
Entity Linking via Dual and Cross-Attention Encoders
Apr 07, 2020

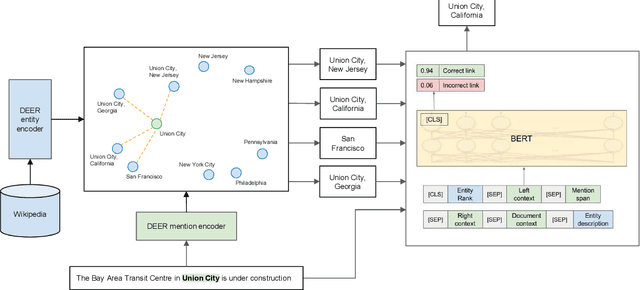

Entity Linking has two main open areas of research: 1) generate candidate entities without using alias tables and 2) generate more contextual representations for both mentions and entities. Recently, a solution has been proposed for the former as a dual-encoder entity retrieval system (Gillick et al., 2019) that learns mention and entity representations in the same space, and performs linking by selecting the nearest entity to the mention in this space. In this work, we use this retrieval system solely for generating candidate entities. We then rerank the entities by using a cross-attention encoder over the target mention and each of the candidate entities. Whereas a dual encoder approach forces all information to be contained in the small, fixed set of vector dimensions used to represent mentions and entities, a crossattention model allows for the use of detailed information (read: features) from the entirety of each <mention, context, candidate entity> tuple. We experiment with features used in the reranker including different ways of incorporating document-level context. We achieve state-of-the-art results on TACKBP-2010 dataset, with 92.05% accuracy. Furthermore, we show how the rescoring model generalizes well when trained on the larger CoNLL-2003 dataset and evaluated on TACKBP-2010.
Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
May 19, 2019
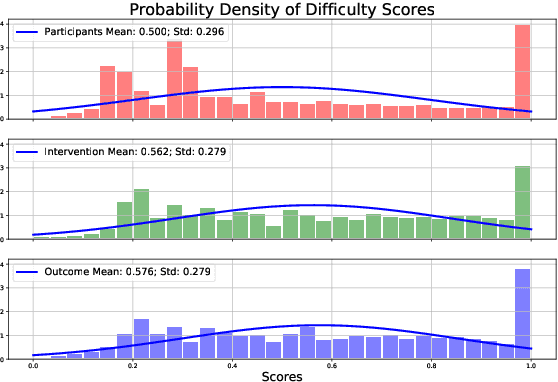
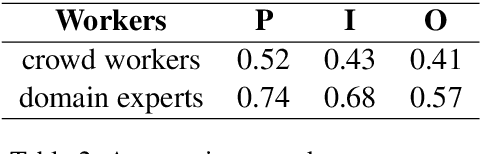

Modern NLP systems require high-quality annotated data. In specialized domains, expert annotations may be prohibitively expensive. An alternative is to rely on crowdsourcing to reduce costs at the risk of introducing noise. In this paper we demonstrate that directly modeling instance difficulty can be used to improve model performance, and to route instances to appropriate annotators. Our difficulty prediction model combines two learned representations: a `universal' encoder trained on out-of-domain data, and a task-specific encoder. Experiments on a complex biomedical information extraction task using expert and lay annotators show that: (i) simply excluding from the training data instances predicted to be difficult yields a small boost in performance; (ii) using difficulty scores to weight instances during training provides further, consistent gains; (iii) assigning instances predicted to be difficult to domain experts is an effective strategy for task routing. Our experiments confirm the expectation that for specialized tasks expert annotations are higher quality than crowd labels, and hence preferable to obtain if practical. Moreover, augmenting small amounts of expert data with a larger set of lay annotations leads to further improvements in model performance.
Named Person Coreference in English News
Oct 26, 2018



People are often entities of interest in tasks such as search and information extraction. In these tasks, the goal is to find as much information as possible about people specified by their name. However in text, some of the references to people are by pronouns (she, his) or generic descriptions (the professor, the German chancellor). It is therefore important that coreference resolution systems are able to link these different types of mentions to the correct person name. Here, we evaluate two state of the art coreference resolution systems on the subtask of Named Person Coreference, in which we are interested in identifying a person mentioned by name, along with all other mentions of the person, by pronoun or generic noun phrase. Our analysis reveals that standard coreference metrics do not reflect adequately the requirements in this task: they do not penalize systems for not identifying any mentions by name and they reward systems even if systems find correctly mentions to the same entity but fail to link these to a proper name (she--the student---no name). We introduce new metrics for evaluating named person coreference that address these discrepancies. We present a simple rule-based named entity recognition driven system, which outperforms the current state-of-the-art systems on these task-specific metrics and performs on par with them on traditional coreference evaluations. Finally, we present similar evaluation for coreference resolution of other named entities and show that the rule-based approach is effective only for person named coreference, not other named entity types.