 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatyrn: A Platform for Analytics Augmented Generation
Jun 17, 2024Large language models (LLMs) are capable of producing documents, and retrieval augmented generation (RAG) has shown itself to be a powerful method for improving accuracy without sacrificing fluency. However, not all information can be retrieved from text. We propose an approach that uses the analysis of structured data to generate fact sets that are used to guide generation in much the same way that retrieved documents are used in RAG. This analytics augmented generation (AAG) approach supports the ability to utilize standard analytic techniques to generate facts that are then converted to text and passed to an LLM. We present a neurosymbolic platform, Satyrn that leverages AAG to produce accurate, fluent, and coherent reports grounded in large scale databases. In our experiments, we find that Satyrn generates reports in which over 86% accurate claims while maintaining high levels of fluency and coherence, even when using smaller language models such as Mistral-7B, as compared to GPT-4 Code Interpreter in which just 57% of claims are accurate.
Summarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023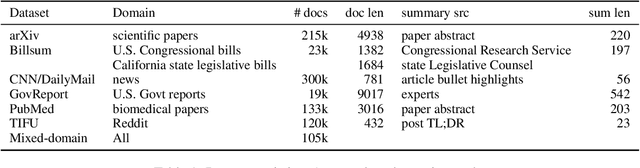

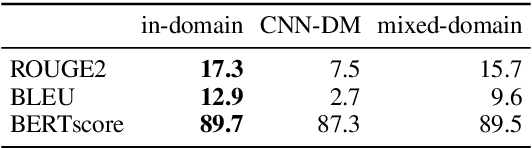
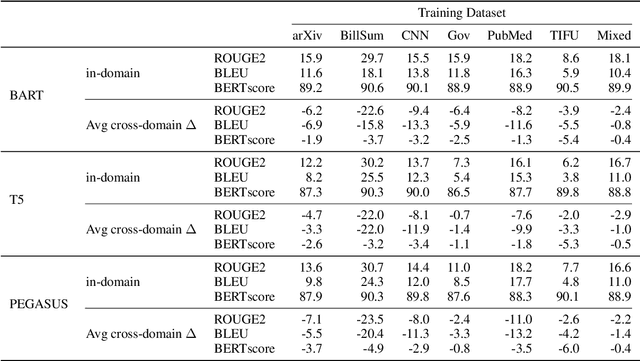
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.
Requirements for Open Political Information: Transparency Beyond Open Data
Dec 06, 2021A politically informed citizenry is imperative for a welldeveloped democracy. While the US government has pursued policies for open data, these efforts have been insufficient in achieving an open government because only people with technical and domain knowledge can access information in the data. In this work, we conduct user interviews to identify wants and needs among stakeholders. We further use this information to sketch out the foundational requirements for a functional political information technical system.