 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023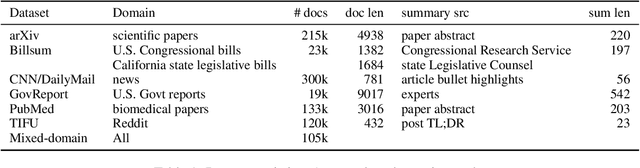

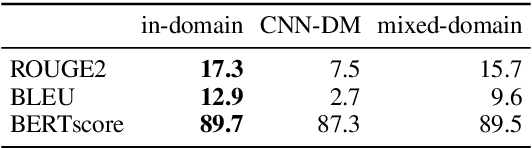
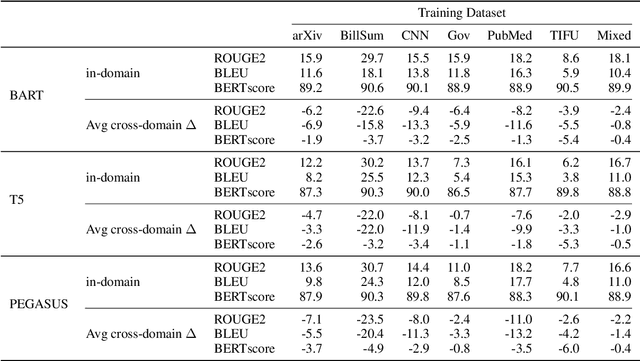
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.