 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023

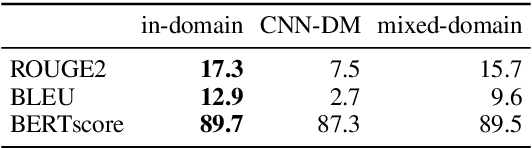
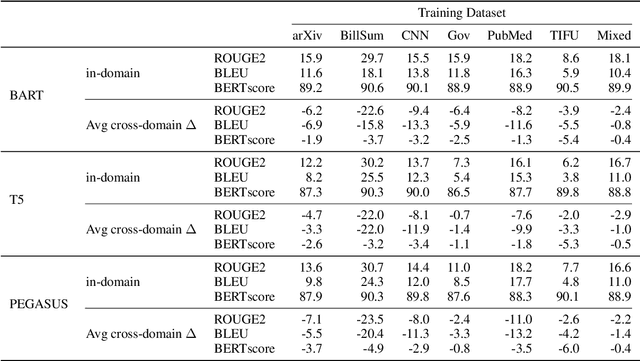
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.
Two to Five Truths in Non-Negative Matrix Factorization
May 06, 2023In this paper, we explore the role of matrix scaling on a matrix of counts when building a topic model using non-negative matrix factorization. We present a scaling inspired by the normalized Laplacian (NL) for graphs that can greatly improve the quality of a non-negative matrix factorization. The results parallel those in the spectral graph clustering work of \cite{Priebe:2019}, where the authors proved adjacency spectral embedding (ASE) spectral clustering was more likely to discover core-periphery partitions and Laplacian Spectral Embedding (LSE) was more likely to discover affinity partitions. In text analysis non-negative matrix factorization (NMF) is typically used on a matrix of co-occurrence ``contexts'' and ``terms" counts. The matrix scaling inspired by LSE gives significant improvement for text topic models in a variety of datasets. We illustrate the dramatic difference a matrix scalings in NMF can greatly improve the quality of a topic model on three datasets where human annotation is available. Using the adjusted Rand index (ARI), a measure cluster similarity we see an increase of 50\% for Twitter data and over 200\% for a newsgroup dataset versus using counts, which is the analogue of ASE. For clean data, such as those from the Document Understanding Conference, NL gives over 40\% improvement over ASE. We conclude with some analysis of this phenomenon and some connections of this scaling with other matrix scaling methods.
On a 'Two Truths' Phenomenon in Spectral Graph Clustering
Sep 07, 2018
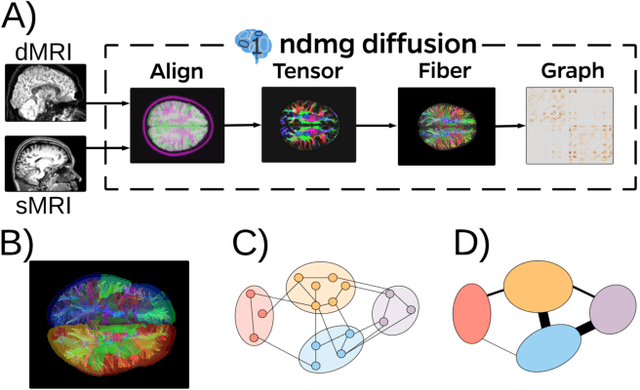
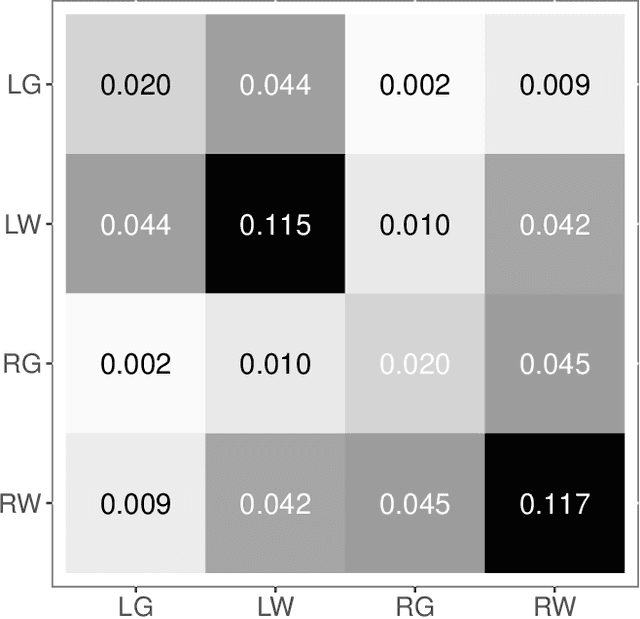
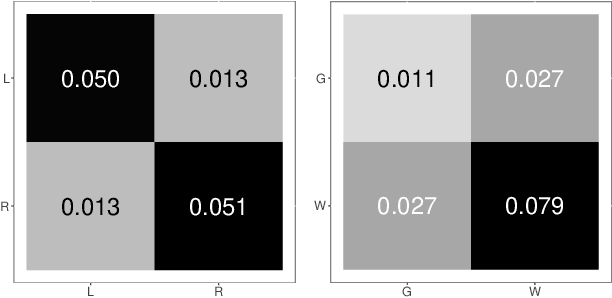
Clustering is concerned with coherently grouping observations without any explicit concept of true groupings. Spectral graph clustering - clustering the vertices of a graph based on their spectral embedding - is commonly approached via K-means (or, more generally, Gaussian mixture model) clustering composed with either Laplacian or Adjacency spectral embedding (LSE or ASE). Recent theoretical results provide new understanding of the problem and solutions, and lead us to a 'Two Truths' LSE vs. ASE spectral graph clustering phenomenon convincingly illustrated here via a diffusion MRI connectome data set: the different embedding methods yield different clustering results, with LSE capturing left hemisphere/right hemisphere affinity structure and ASE capturing gray matter/white matter core-periphery structure.