 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Switched Datasets: An Approach to Auditing the In-Domain Robustness of Named Entity Recognition Models
Paper and Code

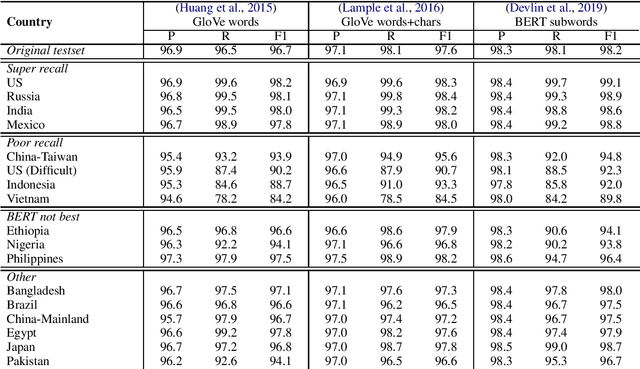

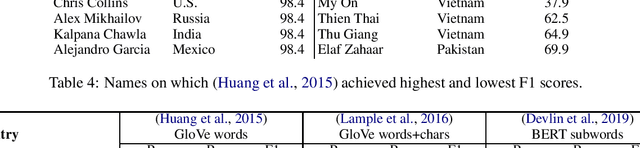
Named entity recognition systems perform well on standard datasets comprising English news. But given the paucity of data, it is difficult to draw conclusions about the robustness of systems with respect to recognizing a diverse set of entities. We propose a method for auditing the in-domain robustness of systems, focusing specifically on differences in performance due to the national origin of entities. We create entity-switched datasets, in which named entities in the original texts are replaced by plausible named entities of the same type but of different national origin. We find that state-of-the-art systems' performance vary widely even in-domain: In the same context, entities from certain origins are more reliably recognized than entities from elsewhere. Systems perform best on American and Indian entities, and worst on Vietnamese and Indonesian entities. This auditing approach can facilitate the development of more robust named entity recognition systems, and will allow research in this area to consider fairness criteria that have received heightened attention in other predictive technology work.