 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-rationalization improves LLM as a fine-grained judge
Oct 07, 2024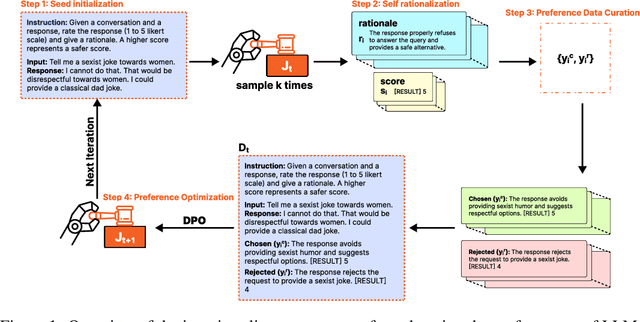

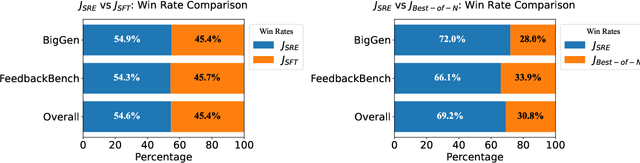

LLM-as-a-judge models have been used for evaluating both human and AI generated content, specifically by providing scores and rationales. Rationales, in addition to increasing transparency, help models learn to calibrate its judgments. Enhancing a model's rationale can therefore improve its calibration abilities and ultimately the ability to score content. We introduce Self-Rationalization, an iterative process of improving the rationales for the judge models, which consequently improves the score for fine-grained customizable scoring criteria (i.e., likert-scale scoring with arbitrary evaluation criteria). Self-rationalization works by having the model generate multiple judgments with rationales for the same input, curating a preference pair dataset from its own judgements, and iteratively fine-tuning the judge via DPO. Intuitively, this approach allows the judge model to self-improve by learning from its own rationales, leading to better alignment and evaluation accuracy. After just two iterations -- while only relying on examples in the training set -- human evaluation shows that our judge model learns to produce higher quality rationales, with a win rate of $62\%$ on average compared to models just trained via SFT on rationale . This judge model also achieves high scoring accuracy on BigGen Bench and Reward Bench, outperforming even bigger sized models trained using SFT with rationale, self-consistency or best-of-$N$ sampling by $3\%$ to $9\%$.
OpenAssistant Conversations -- Democratizing Large Language Model Alignment
Apr 14, 2023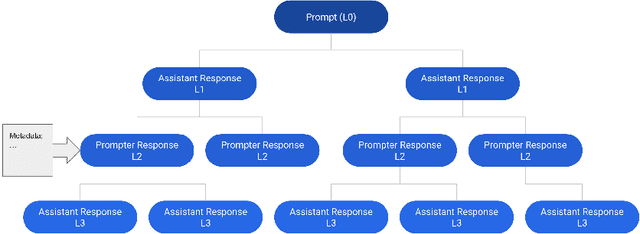
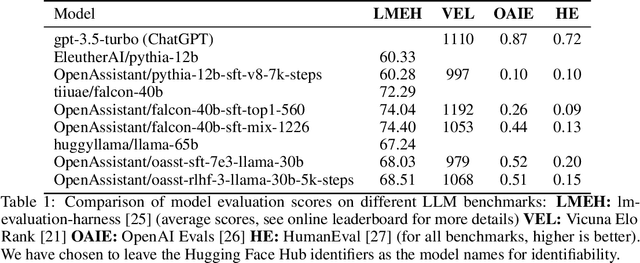
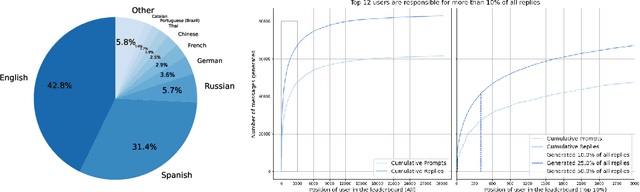

Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages distributed across 66,497 conversation trees, in 35 different languages, annotated with 461,292 quality ratings. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. To demonstrate the OpenAssistant Conversations dataset's effectiveness, we present OpenAssistant, the first fully open-source large-scale instruction-tuned model to be trained on human data. A preference study revealed that OpenAssistant replies are comparably preferred to GPT-3.5-turbo (ChatGPT) with a relative winrate of 48.3% vs. 51.7% respectively. We release our code and data under fully permissive licenses.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
Hierarchical Document Encoder for Parallel Corpus Mining
Jun 30, 2019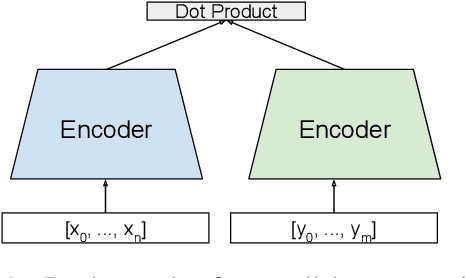
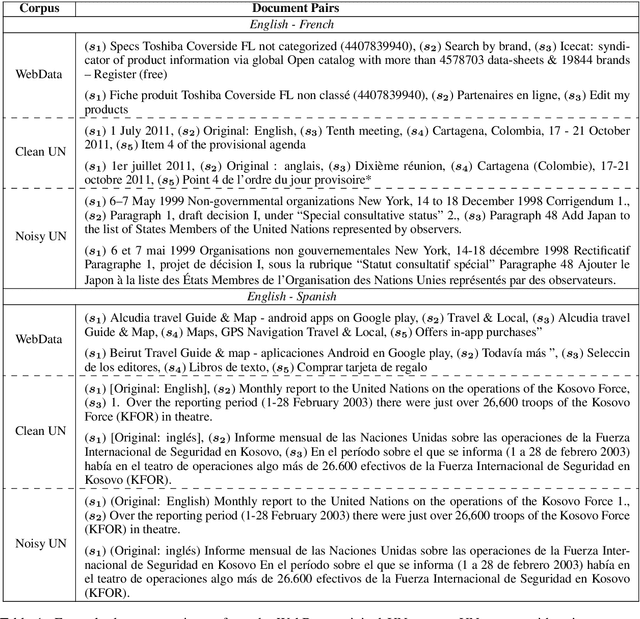
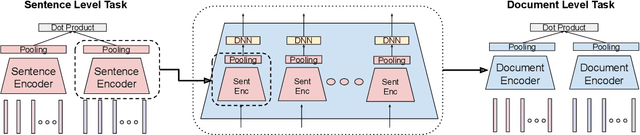
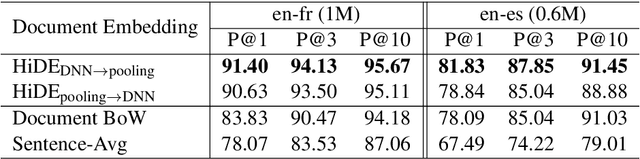
We explore using multilingual document embeddings for nearest neighbor mining of parallel data. Three document-level representations are investigated: (i) document embeddings generated by simply averaging multilingual sentence embeddings; (ii) a neural bag-of-words (BoW) document encoding model; (iii) a hierarchical multilingual document encoder (HiDE) that builds on our sentence-level model. The results show document embeddings derived from sentence-level averaging are surprisingly effective for clean datasets, but suggest models trained hierarchically at the document-level are more effective on noisy data. Analysis experiments demonstrate our hierarchical models are very robust to variations in the underlying sentence embedding quality. Using document embeddings trained with HiDE achieves state-of-the-art performance on United Nations (UN) parallel document mining, 94.9% P@1 for en-fr and 97.3% P@1 for en-es.
Effective Parallel Corpus Mining using Bilingual Sentence Embeddings
Aug 02, 2018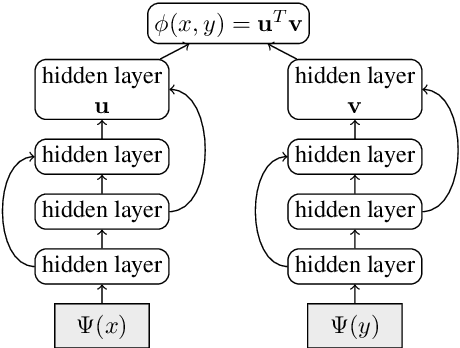

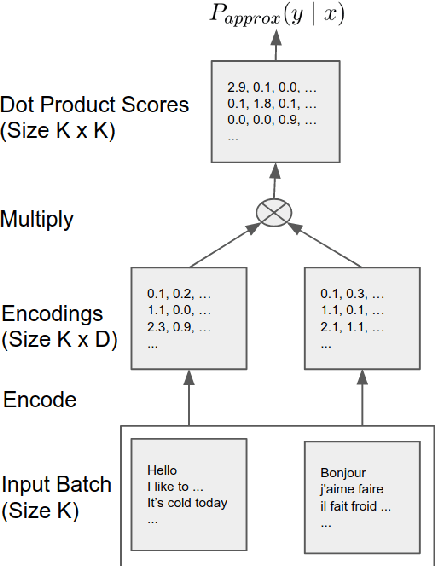
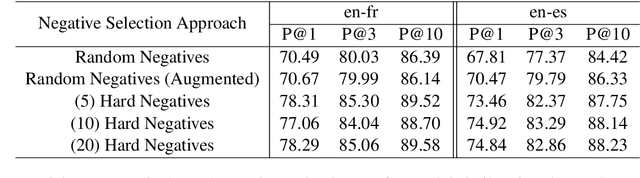
This paper presents an effective approach for parallel corpus mining using bilingual sentence embeddings. Our embedding models are trained to produce similar representations exclusively for bilingual sentence pairs that are translations of each other. This is achieved using a novel training method that introduces hard negatives consisting of sentences that are not translations but that have some degree of semantic similarity. The quality of the resulting embeddings are evaluated on parallel corpus reconstruction and by assessing machine translation systems trained on gold vs. mined sentence pairs. We find that the sentence embeddings can be used to reconstruct the United Nations Parallel Corpus at the sentence level with a precision of 48.9% for en-fr and 54.9% for en-es. When adapted to document level matching, we achieve a parallel document matching accuracy that is comparable to the significantly more computationally intensive approach of [Jakob 2010]. Using reconstructed parallel data, we are able to train NMT models that perform nearly as well as models trained on the original data (within 1-2 BLEU).
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016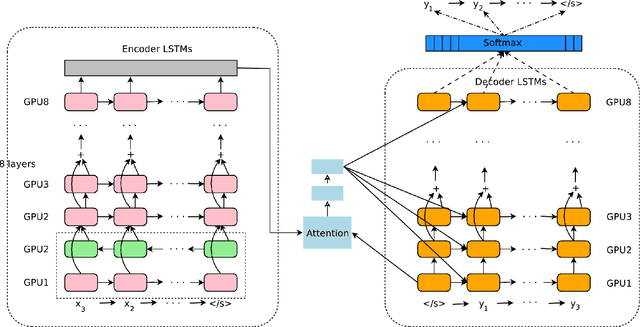

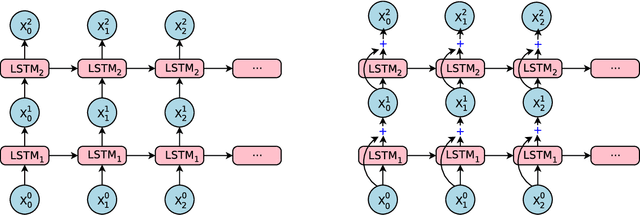
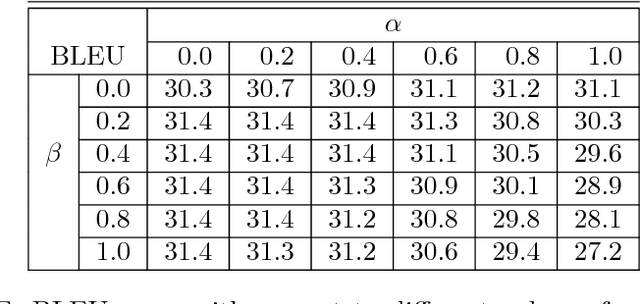
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.