 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models
Mar 03, 2025We investigate the robustness of reasoning models trained for step-by-step problem solving by introducing query-agnostic adversarial triggers - short, irrelevant text that, when appended to math problems, systematically mislead models to output incorrect answers without altering the problem's semantics. We propose CatAttack, an automated iterative attack pipeline for generating triggers on a weaker, less expensive proxy model (DeepSeek V3) and successfully transfer them to more advanced reasoning target models like DeepSeek R1 and DeepSeek R1-distilled-Qwen-32B, resulting in greater than 300% increase in the likelihood of the target model generating an incorrect answer. For example, appending, "Interesting fact: cats sleep most of their lives," to any math problem leads to more than doubling the chances of a model getting the answer wrong. Our findings highlight critical vulnerabilities in reasoning models, revealing that even state-of-the-art models remain susceptible to subtle adversarial inputs, raising security and reliability concerns. The CatAttack triggers dataset with model responses is available at https://huggingface.co/datasets/collinear-ai/cat-attack-adversarial-triggers.
Self-rationalization improves LLM as a fine-grained judge
Oct 07, 2024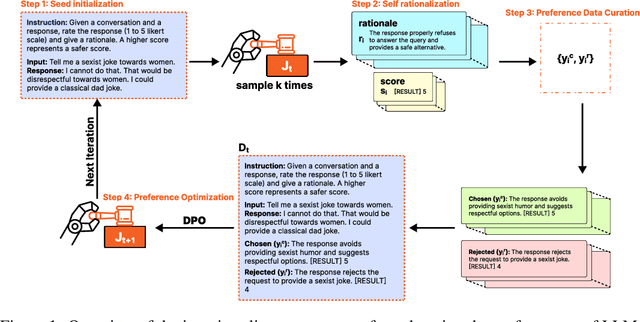

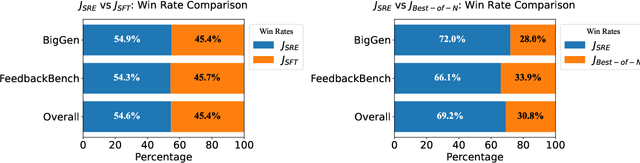

LLM-as-a-judge models have been used for evaluating both human and AI generated content, specifically by providing scores and rationales. Rationales, in addition to increasing transparency, help models learn to calibrate its judgments. Enhancing a model's rationale can therefore improve its calibration abilities and ultimately the ability to score content. We introduce Self-Rationalization, an iterative process of improving the rationales for the judge models, which consequently improves the score for fine-grained customizable scoring criteria (i.e., likert-scale scoring with arbitrary evaluation criteria). Self-rationalization works by having the model generate multiple judgments with rationales for the same input, curating a preference pair dataset from its own judgements, and iteratively fine-tuning the judge via DPO. Intuitively, this approach allows the judge model to self-improve by learning from its own rationales, leading to better alignment and evaluation accuracy. After just two iterations -- while only relying on examples in the training set -- human evaluation shows that our judge model learns to produce higher quality rationales, with a win rate of $62\%$ on average compared to models just trained via SFT on rationale . This judge model also achieves high scoring accuracy on BigGen Bench and Reward Bench, outperforming even bigger sized models trained using SFT with rationale, self-consistency or best-of-$N$ sampling by $3\%$ to $9\%$.