 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models
Mar 03, 2025We investigate the robustness of reasoning models trained for step-by-step problem solving by introducing query-agnostic adversarial triggers - short, irrelevant text that, when appended to math problems, systematically mislead models to output incorrect answers without altering the problem's semantics. We propose CatAttack, an automated iterative attack pipeline for generating triggers on a weaker, less expensive proxy model (DeepSeek V3) and successfully transfer them to more advanced reasoning target models like DeepSeek R1 and DeepSeek R1-distilled-Qwen-32B, resulting in greater than 300% increase in the likelihood of the target model generating an incorrect answer. For example, appending, "Interesting fact: cats sleep most of their lives," to any math problem leads to more than doubling the chances of a model getting the answer wrong. Our findings highlight critical vulnerabilities in reasoning models, revealing that even state-of-the-art models remain susceptible to subtle adversarial inputs, raising security and reliability concerns. The CatAttack triggers dataset with model responses is available at https://huggingface.co/datasets/collinear-ai/cat-attack-adversarial-triggers.
VERITAS: A Unified Approach to Reliability Evaluation
Nov 05, 2024
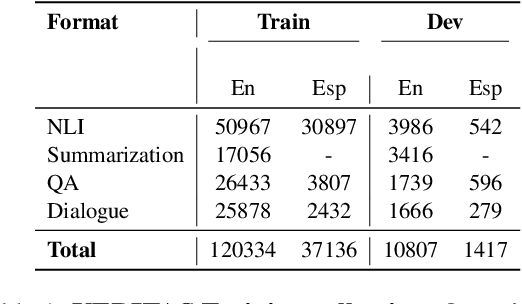

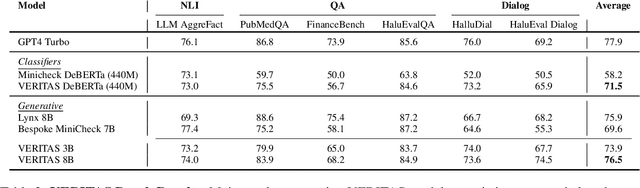
Large language models (LLMs) often fail to synthesize information from their context to generate an accurate response. This renders them unreliable in knowledge intensive settings where reliability of the output is key. A critical component for reliable LLMs is the integration of a robust fact-checking system that can detect hallucinations across various formats. While several open-access fact-checking models are available, their functionality is often limited to specific tasks, such as grounded question-answering or entailment verification, and they perform less effectively in conversational settings. On the other hand, closed-access models like GPT-4 and Claude offer greater flexibility across different contexts, including grounded dialogue verification, but are hindered by high costs and latency. In this work, we introduce VERITAS, a family of hallucination detection models designed to operate flexibly across diverse contexts while minimizing latency and costs. VERITAS achieves state-of-the-art results considering average performance on all major hallucination detection benchmarks, with $10\%$ increase in average performance when compared to similar-sized models and get close to the performance of GPT4 turbo with LLM-as-a-judge setting.
Self-rationalization improves LLM as a fine-grained judge
Oct 07, 2024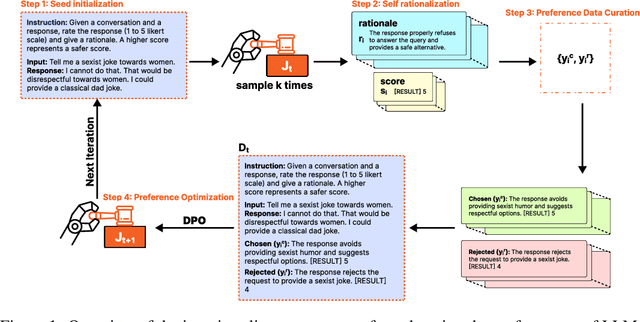

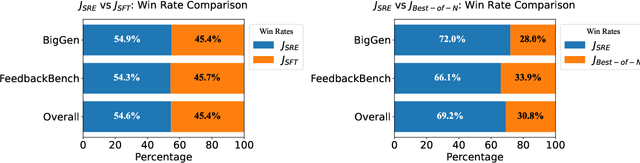

LLM-as-a-judge models have been used for evaluating both human and AI generated content, specifically by providing scores and rationales. Rationales, in addition to increasing transparency, help models learn to calibrate its judgments. Enhancing a model's rationale can therefore improve its calibration abilities and ultimately the ability to score content. We introduce Self-Rationalization, an iterative process of improving the rationales for the judge models, which consequently improves the score for fine-grained customizable scoring criteria (i.e., likert-scale scoring with arbitrary evaluation criteria). Self-rationalization works by having the model generate multiple judgments with rationales for the same input, curating a preference pair dataset from its own judgements, and iteratively fine-tuning the judge via DPO. Intuitively, this approach allows the judge model to self-improve by learning from its own rationales, leading to better alignment and evaluation accuracy. After just two iterations -- while only relying on examples in the training set -- human evaluation shows that our judge model learns to produce higher quality rationales, with a win rate of $62\%$ on average compared to models just trained via SFT on rationale . This judge model also achieves high scoring accuracy on BigGen Bench and Reward Bench, outperforming even bigger sized models trained using SFT with rationale, self-consistency or best-of-$N$ sampling by $3\%$ to $9\%$.
Learning to Generate Better Than Your LLM
Jun 20, 2023Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning Large Language Models (LLMs) for conditional text generation. In particular, recent LLMs such as ChatGPT and GPT-4 can engage in fluent conversations with users by incorporating RL and feedback from humans. Inspired by learning-to-search algorithms and capitalizing on key properties of text generation, we seek to investigate reinforcement learning algorithms beyond general purpose algorithms such as Proximal policy optimization (PPO). In particular, we extend RL algorithms to allow them to interact with a dynamic black-box guide LLM such as GPT-3 and propose RL with guided feedback (RLGF), a suite of RL algorithms for LLM fine-tuning. We experiment on the IMDB positive review and CommonGen text generation task from the GRUE benchmark. We show that our RL algorithms achieve higher performance than supervised learning (SL) and default PPO baselines, demonstrating the benefit of interaction with the guide LLM. On CommonGen, we not only outperform our SL baselines but also improve beyond PPO across a variety of lexical and semantic metrics beyond the one we optimized for. Notably, on the IMDB dataset, we show that our GPT-2 based policy outperforms the zero-shot GPT-3 oracle, indicating that our algorithms can learn from a powerful, black-box GPT-3 oracle with a simpler, cheaper, and publicly available GPT-2 model while gaining performance.
Zero-Shot Text Matching for Automated Auditing using Sentence Transformers
Oct 28, 2022Natural language processing methods have several applications in automated auditing, including document or passage classification, information retrieval, and question answering. However, training such models requires a large amount of annotated data which is scarce in industrial settings. At the same time, techniques like zero-shot and unsupervised learning allow for application of models pre-trained using general domain data to unseen domains. In this work, we study the efficiency of unsupervised text matching using Sentence-Bert, a transformer-based model, by applying it to the semantic similarity of financial passages. Experimental results show that this model is robust to documents from in- and out-of-domain data.
Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
Oct 03, 2022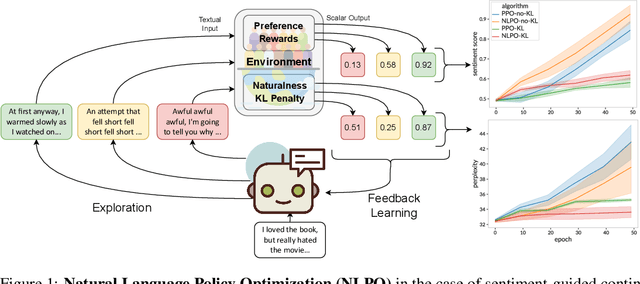
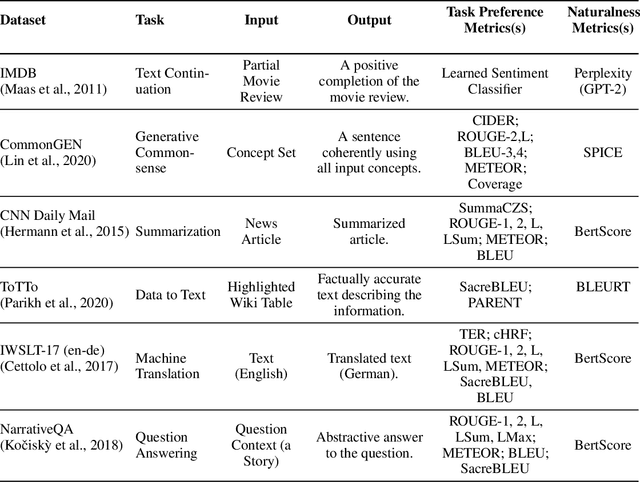
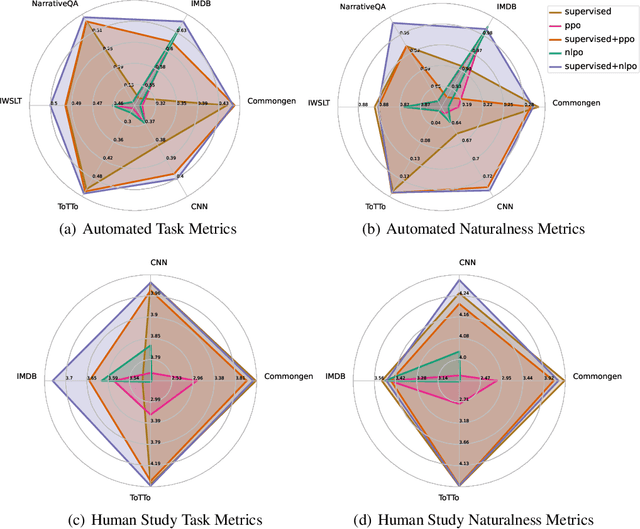
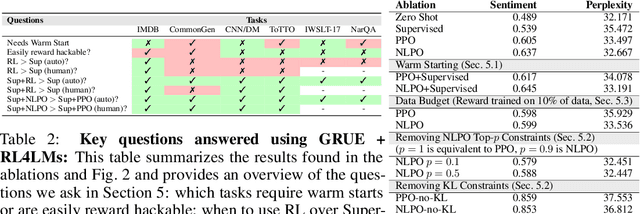
We tackle the problem of aligning pre-trained large language models (LMs) with human preferences. If we view text generation as a sequential decision-making problem, reinforcement learning (RL) appears to be a natural conceptual framework. However, using RL for LM-based generation faces empirical challenges, including training instability due to the combinatorial action space, as well as a lack of open-source libraries and benchmarks customized for LM alignment. Thus, a question rises in the research community: is RL a practical paradigm for NLP? To help answer this, we first introduce an open-source modular library, RL4LMs (Reinforcement Learning for Language Models), for optimizing language generators with RL. The library consists of on-policy RL algorithms that can be used to train any encoder or encoder-decoder LM in the HuggingFace library (Wolf et al. 2020) with an arbitrary reward function. Next, we present the GRUE (General Reinforced-language Understanding Evaluation) benchmark, a set of 6 language generation tasks which are supervised not by target strings, but by reward functions which capture automated measures of human preference.GRUE is the first leaderboard-style evaluation of RL algorithms for NLP tasks. Finally, we introduce an easy-to-use, performant RL algorithm, NLPO (Natural Language Policy Optimization)} that learns to effectively reduce the combinatorial action space in language generation. We show 1) that RL techniques are generally better than supervised methods at aligning LMs to human preferences; and 2) that NLPO exhibits greater stability and performance than previous policy gradient methods (e.g., PPO (Schulman et al. 2017)), based on both automatic and human evaluation.
NLPGym -- A toolkit for evaluating RL agents on Natural Language Processing Tasks
Nov 16, 2020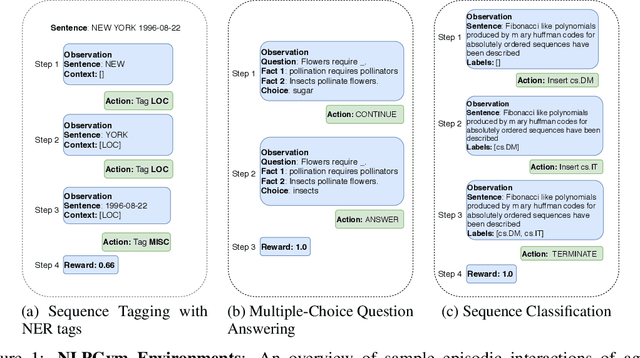

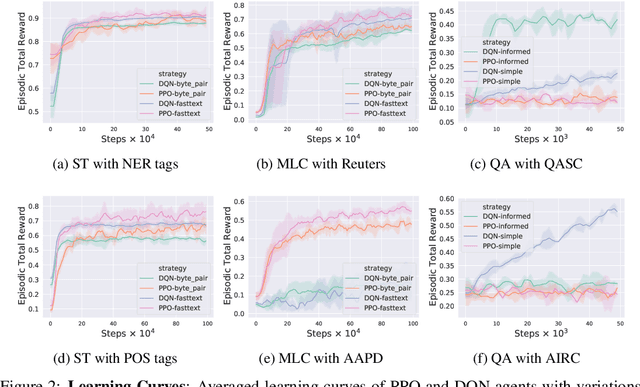
Reinforcement learning (RL) has recently shown impressive performance in complex game AI and robotics tasks. To a large extent, this is thanks to the availability of simulated environments such as OpenAI Gym, Atari Learning Environment, or Malmo which allow agents to learn complex tasks through interaction with virtual environments. While RL is also increasingly applied to natural language processing (NLP), there are no simulated textual environments available for researchers to apply and consistently benchmark RL on NLP tasks. With the work reported here, we therefore release NLPGym, an open-source Python toolkit that provides interactive textual environments for standard NLP tasks such as sequence tagging, multi-label classification, and question answering. We also present experimental results for 6 tasks using different RL algorithms which serve as baselines for further research. The toolkit is published at https://github.com/rajcscw/nlp-gym
Using Echo State Networks for Cryptography
Apr 04, 2017


Echo state networks are simple recurrent neural networks that are easy to implement and train. Despite their simplicity, they show a form of memory and can predict or regenerate sequences of data. We make use of this property to realize a novel neural cryptography scheme. The key idea is to assume that Alice and Bob share a copy of an echo state network. If Alice trains her copy to memorize a message, she can communicate the trained part of the network to Bob who plugs it into his copy to regenerate the message. Considering a byte-level representation of in- and output, the technique applies to arbitrary types of data (texts, images, audio files, etc.) and practical experiments reveal it to satisfy the fundamental cryptographic properties of diffusion and confusion.