 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Topic Extraction and Word Embedding Learning using row-stochastic DEDICOM
Jul 22, 2025The DEDICOM algorithm provides a uniquely interpretable matrix factorization method for symmetric and asymmetric square matrices. We employ a new row-stochastic variation of DEDICOM on the pointwise mutual information matrices of text corpora to identify latent topic clusters within the vocabulary and simultaneously learn interpretable word embeddings. We introduce a method to efficiently train a constrained DEDICOM algorithm and a qualitative evaluation of its topic modeling and word embedding performance.
* Accepted and published at CD-MAKE 2020, 20 pages, 8 tables, 8 figures
Quantum Adiabatic Generation of Human-Like Passwords
Jun 10, 2025Generative Artificial Intelligence (GenAI) for Natural Language Processing (NLP) is the predominant AI technology to date. An important perspective for Quantum Computing (QC) is the question whether QC has the potential to reduce the vast resource requirements for training and operating GenAI models. While large-scale generative NLP tasks are currently out of reach for practical quantum computers, the generation of short semantic structures such as passwords is not. Generating passwords that mimic real user behavior has many applications, for example to test an authentication system against realistic threat models. Classical password generation via deep learning have recently been investigated with significant progress in their ability to generate novel, realistic password candidates. In the present work we investigate the utility of adiabatic quantum computers for this task. More precisely, we study different encodings of token strings and propose novel approaches based on the Quadratic Unconstrained Binary Optimization (QUBO) and the Unit-Disk Maximum Independent Set (UD-MIS) problems. Our approach allows us to estimate the token distribution from data and adiabatically prepare a quantum state from which we eventually sample the generated passwords via measurements. Our results show that relatively small samples of 128 passwords, generated on the QuEra Aquila 256-qubit neutral atom quantum computer, contain human-like passwords such as "Tunas200992" or "teedem28iglove".
Zero-Shot Text Matching for Automated Auditing using Sentence Transformers
Oct 28, 2022Natural language processing methods have several applications in automated auditing, including document or passage classification, information retrieval, and question answering. However, training such models requires a large amount of annotated data which is scarce in industrial settings. At the same time, techniques like zero-shot and unsupervised learning allow for application of models pre-trained using general domain data to unseen domains. In this work, we study the efficiency of unsupervised text matching using Sentence-Bert, a transformer-based model, by applying it to the semantic similarity of financial passages. Experimental results show that this model is robust to documents from in- and out-of-domain data.
Improving Chest X-Ray Classification by RNN-based Patient Monitoring
Oct 28, 2022Chest X-Ray imaging is one of the most common radiological tools for detection of various pathologies related to the chest area and lung function. In a clinical setting, automated assessment of chest radiographs has the potential of assisting physicians in their decision making process and optimize clinical workflows, for example by prioritizing emergency patients. Most work analyzing the potential of machine learning models to classify chest X-ray images focuses on vision methods processing and predicting pathologies for one image at a time. However, many patients undergo such a procedure multiple times during course of a treatment or during a single hospital stay. The patient history, that is previous images and especially the corresponding diagnosis contain useful information that can aid a classification system in its prediction. In this study, we analyze how information about diagnosis can improve CNN-based image classification models by constructing a novel dataset from the well studied CheXpert dataset of chest X-rays. We show that a model trained on additional patient history information outperforms a model trained without the information by a significant margin. We provide code to replicate the dataset creation and model training.
Generative Deep Learning Techniques for Password Generation
Dec 16, 2020



Password guessing approaches via deep learning have recently been investigated with significant breakthroughs in their ability to generate novel, realistic password candidates. In the present work we study a broad collection of deep learning and probabilistic based models in the light of password guessing: attention-based deep neural networks, autoencoding mechanisms and generative adversarial networks. We provide novel generative deep-learning models in terms of variational autoencoders exhibiting state-of-art sampling performance, yielding additional latent-space features such as interpolations and targeted sampling. Lastly, we perform a thorough empirical analysis in a unified controlled framework over well-known datasets (RockYou, LinkedIn, Youku, Zomato, Pwnd). Our results not only identify the most promising schemes driven by deep neural networks, but also illustrate the strengths of each approach in terms of generation variability and sample uniqueness.
Towards Supervised Extractive Text Summarization via RNN-based Sequence Classification
Nov 13, 2019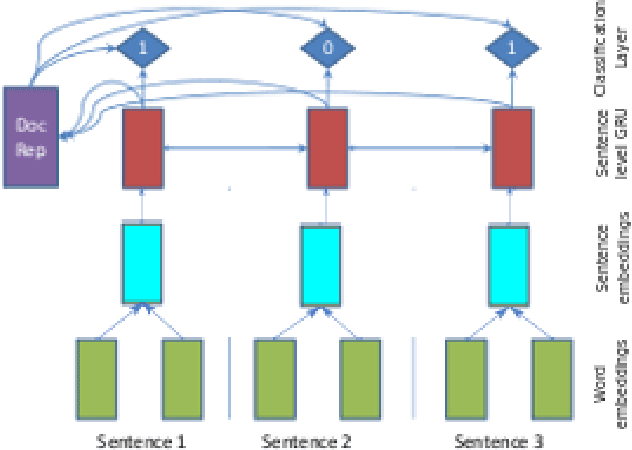

This article briefly explains our submitted approach to the DocEng'19 competition on extractive summarization. We implemented a recurrent neural network based model that learns to classify whether an article's sentence belongs to the corresponding extractive summary or not. We bypass the lack of large annotated news corpora for extractive summarization by generating extractive summaries from abstractive ones, which are available from the CNN corpus.