 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge[Vision Paper] PRObot: Enhancing Patient-Reported Outcome Measures for Diabetic Retinopathy using Chatbots and Generative AI
Nov 05, 2024We present an outline of the first large language model (LLM) based chatbot application in the context of patient-reported outcome measures (PROMs) for diabetic retinopathy. By utilizing the capabilities of current LLMs, we enable patients to provide feedback about their quality of life and treatment progress via an interactive application. The proposed framework offers significant advantages over the current approach, which encompasses only qualitative collection of survey data or a static survey with limited answer options. Using the PROBot LLM-PROM application, patients will be asked tailored questions about their individual challenges, and can give more detailed feedback on the progress of their treatment. Based on this input, we will use machine learning to infer conventional PROM scores, which can be used by clinicians to evaluate the treatment status. The goal of the application is to improve adherence to the healthcare system and treatments, and thus ultimately reduce cases of subsequent vision impairment. The approach needs to be further validated using a survey and a clinical study.
Generating Prototypes for Contradiction Detection Using Large Language Models and Linguistic Rules
Oct 23, 2023We introduce a novel data generation method for contradiction detection, which leverages the generative power of large language models as well as linguistic rules. Our vision is to provide a condensed corpus of prototypical contradictions, allowing for in-depth linguistic analysis as well as efficient language model fine-tuning. To this end, we instruct the generative models to create contradicting statements with respect to descriptions of specific contradiction types. In addition, the model is also instructed to come up with completely new contradiction typologies. As an auxiliary approach, we use linguistic rules to construct simple contradictions such as those arising from negation, antonymy and numeric mismatch. We find that our methods yield promising results in terms of coherence and variety of the data. Further studies, as well as manual refinement are necessary to make use of this data in a machine learning setup.
Improving Zero-Shot Text Matching for Financial Auditing with Large Language Models
Aug 14, 2023


Auditing financial documents is a very tedious and time-consuming process. As of today, it can already be simplified by employing AI-based solutions to recommend relevant text passages from a report for each legal requirement of rigorous accounting standards. However, these methods need to be fine-tuned regularly, and they require abundant annotated data, which is often lacking in industrial environments. Hence, we present ZeroShotALI, a novel recommender system that leverages a state-of-the-art large language model (LLM) in conjunction with a domain-specifically optimized transformer-based text-matching solution. We find that a two-step approach of first retrieving a number of best matching document sections per legal requirement with a custom BERT-based model and second filtering these selections using an LLM yields significant performance improvements over existing approaches.
Improving Natural Language Inference in Arabic using Transformer Models and Linguistically Informed Pre-Training
Jul 27, 2023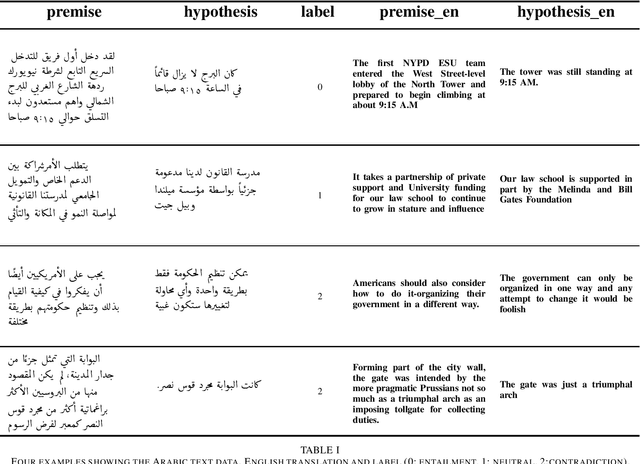


This paper addresses the classification of Arabic text data in the field of Natural Language Processing (NLP), with a particular focus on Natural Language Inference (NLI) and Contradiction Detection (CD). Arabic is considered a resource-poor language, meaning that there are few data sets available, which leads to limited availability of NLP methods. To overcome this limitation, we create a dedicated data set from publicly available resources. Subsequently, transformer-based machine learning models are being trained and evaluated. We find that a language-specific model (AraBERT) performs competitively with state-of-the-art multilingual approaches, when we apply linguistically informed pre-training methods such as Named Entity Recognition (NER). To our knowledge, this is the first large-scale evaluation for this task in Arabic, as well as the first application of multi-task pre-training in this context.
sustain.AI: a Recommender System to analyze Sustainability Reports
May 26, 2023



We present sustainAI, an intelligent, context-aware recommender system that assists auditors and financial investors as well as the general public to efficiently analyze companies' sustainability reports. The tool leverages an end-to-end trainable architecture that couples a BERT-based encoding module with a multi-label classification head to match relevant text passages from sustainability reports to their respective law regulations from the Global Reporting Initiative (GRI) standards. We evaluate our model on two novel German sustainability reporting data sets and consistently achieve a significantly higher recommendation performance compared to multiple strong baselines. Furthermore, sustainAI is publicly available for everyone at https://sustain.ki.nrw/.
Towards Linguistically Informed Multi-Objective Pre-Training for Natural Language Inference
Dec 30, 2022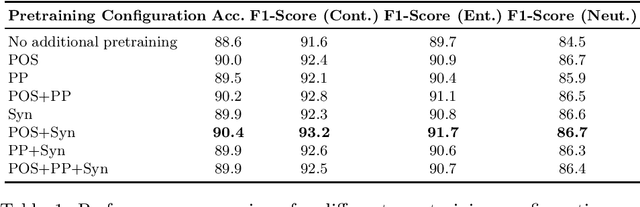
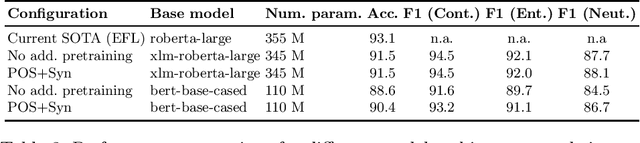
We introduce a linguistically enhanced combination of pre-training methods for transformers. The pre-training objectives include POS-tagging, synset prediction based on semantic knowledge graphs, and parent prediction based on dependency parse trees. Our approach achieves competitive results on the Natural Language Inference task, compared to the state of the art. Specifically for smaller models, the method results in a significant performance boost, emphasizing the fact that intelligent pre-training can make up for fewer parameters and help building more efficient models. Combining POS-tagging and synset prediction yields the overall best results.
Zero-Shot Text Matching for Automated Auditing using Sentence Transformers
Oct 28, 2022Natural language processing methods have several applications in automated auditing, including document or passage classification, information retrieval, and question answering. However, training such models requires a large amount of annotated data which is scarce in industrial settings. At the same time, techniques like zero-shot and unsupervised learning allow for application of models pre-trained using general domain data to unseen domains. In this work, we study the efficiency of unsupervised text matching using Sentence-Bert, a transformer-based model, by applying it to the semantic similarity of financial passages. Experimental results show that this model is robust to documents from in- and out-of-domain data.
A Linguistic Investigation of Machine Learning based Contradiction Detection Models: An Empirical Analysis and Future Perspectives
Oct 19, 2022
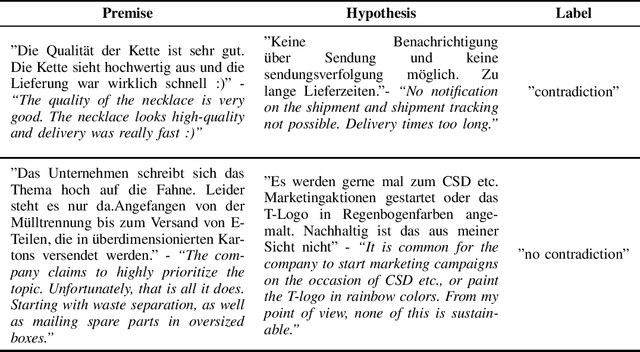
We analyze two Natural Language Inference data sets with respect to their linguistic features. The goal is to identify those syntactic and semantic properties that are particularly hard to comprehend for a machine learning model. To this end, we also investigate the differences between a crowd-sourced, machine-translated data set (SNLI) and a collection of text pairs from internet sources. Our main findings are, that the model has difficulty recognizing the semantic importance of prepositions and verbs, emphasizing the importance of linguistically aware pre-training tasks. Furthermore, it often does not comprehend antonyms and homonyms, especially if those are depending on the context. Incomplete sentences are another problem, as well as longer paragraphs and rare words or phrases. The study shows that automated language understanding requires a more informed approach, utilizing as much external knowledge as possible throughout the training process.