 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Prototypes for Contradiction Detection Using Large Language Models and Linguistic Rules
Oct 23, 2023We introduce a novel data generation method for contradiction detection, which leverages the generative power of large language models as well as linguistic rules. Our vision is to provide a condensed corpus of prototypical contradictions, allowing for in-depth linguistic analysis as well as efficient language model fine-tuning. To this end, we instruct the generative models to create contradicting statements with respect to descriptions of specific contradiction types. In addition, the model is also instructed to come up with completely new contradiction typologies. As an auxiliary approach, we use linguistic rules to construct simple contradictions such as those arising from negation, antonymy and numeric mismatch. We find that our methods yield promising results in terms of coherence and variety of the data. Further studies, as well as manual refinement are necessary to make use of this data in a machine learning setup.
Towards Linguistically Informed Multi-Objective Pre-Training for Natural Language Inference
Dec 30, 2022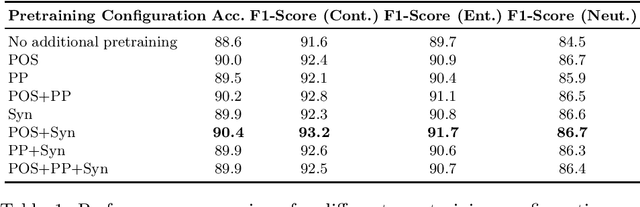
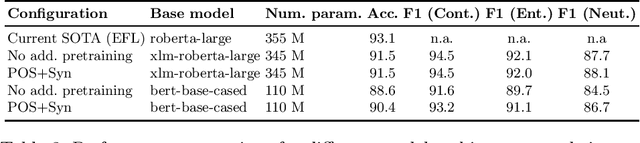
We introduce a linguistically enhanced combination of pre-training methods for transformers. The pre-training objectives include POS-tagging, synset prediction based on semantic knowledge graphs, and parent prediction based on dependency parse trees. Our approach achieves competitive results on the Natural Language Inference task, compared to the state of the art. Specifically for smaller models, the method results in a significant performance boost, emphasizing the fact that intelligent pre-training can make up for fewer parameters and help building more efficient models. Combining POS-tagging and synset prediction yields the overall best results.