 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Linguistically Informed Multi-Objective Pre-Training for Natural Language Inference
Dec 30, 2022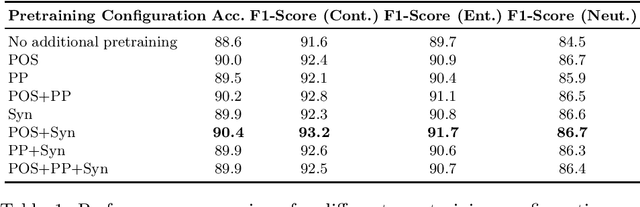
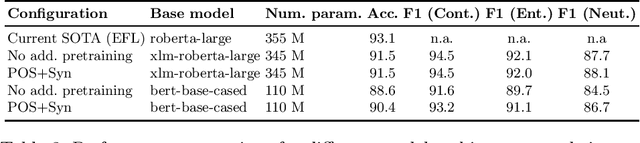
We introduce a linguistically enhanced combination of pre-training methods for transformers. The pre-training objectives include POS-tagging, synset prediction based on semantic knowledge graphs, and parent prediction based on dependency parse trees. Our approach achieves competitive results on the Natural Language Inference task, compared to the state of the art. Specifically for smaller models, the method results in a significant performance boost, emphasizing the fact that intelligent pre-training can make up for fewer parameters and help building more efficient models. Combining POS-tagging and synset prediction yields the overall best results.
A Linguistic Investigation of Machine Learning based Contradiction Detection Models: An Empirical Analysis and Future Perspectives
Oct 19, 2022
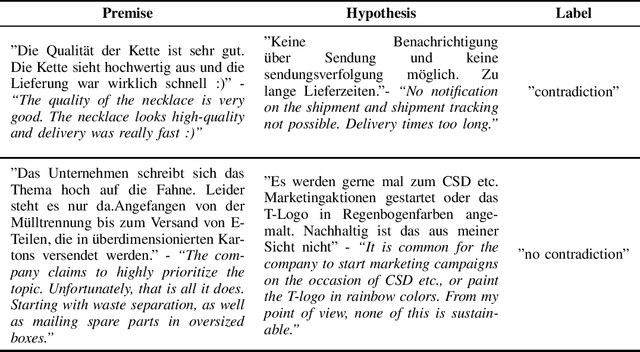
We analyze two Natural Language Inference data sets with respect to their linguistic features. The goal is to identify those syntactic and semantic properties that are particularly hard to comprehend for a machine learning model. To this end, we also investigate the differences between a crowd-sourced, machine-translated data set (SNLI) and a collection of text pairs from internet sources. Our main findings are, that the model has difficulty recognizing the semantic importance of prepositions and verbs, emphasizing the importance of linguistically aware pre-training tasks. Furthermore, it often does not comprehend antonyms and homonyms, especially if those are depending on the context. Incomplete sentences are another problem, as well as longer paragraphs and rare words or phrases. The study shows that automated language understanding requires a more informed approach, utilizing as much external knowledge as possible throughout the training process.