 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Private Code in IDE Autocomplete using Differential Privacy
Jan 30, 2026Modern Integrated Development Environments (IDEs) increasingly leverage Large Language Models (LLMs) to provide advanced features like code autocomplete. While powerful, training these models on user-written code introduces significant privacy risks, making the models themselves a new type of data vulnerability. Malicious actors can exploit this by launching attacks to reconstruct sensitive training data or infer whether a specific code snippet was used for training. This paper investigates the use of Differential Privacy (DP) as a robust defense mechanism for training an LLM for Kotlin code completion. We fine-tune a \texttt{Mellum} model using DP and conduct a comprehensive evaluation of its privacy and utility. Our results demonstrate that DP provides a strong defense against Membership Inference Attacks (MIAs), reducing the attack's success rate close to a random guess (AUC from 0.901 to 0.606). Furthermore, we show that this privacy guarantee comes at a minimal cost to model performance, with the DP-trained model achieving utility scores comparable to its non-private counterpart, even when trained on 100x less data. Our findings suggest that DP is a practical and effective solution for building private and trustworthy AI-powered IDE features.
Domain-Adaptation through Synthetic Data: Fine-Tuning Large Language Models for German Law
Jan 20, 2026Large language models (LLMs) often struggle in specialized domains such as legal reasoning due to limited expert knowledge, resulting in factually incorrect outputs or hallucinations. This paper presents an effective method for adapting advanced LLMs to German legal question answering through a novel synthetic data generation approach. In contrast to costly human-annotated resources or unreliable synthetic alternatives, our approach systematically produces high-quality, diverse, and legally accurate question-answer pairs directly from authoritative German statutes. Using rigorous automated filtering methods and parameter-efficient fine-tuning techniques, we demonstrate that LLMs adapted with our synthetic dataset significantly outperform their baseline counterparts on German legal question answering tasks. Our results highlight the feasibility of using carefully designed synthetic data as a robust alternative to manual annotation in high-stakes, knowledge-intensive domains.
Powerful Training-Free Membership Inference Against Autoregressive Language Models
Jan 17, 2026Fine-tuned language models pose significant privacy risks, as they may memorize and expose sensitive information from their training data. Membership inference attacks (MIAs) provide a principled framework for auditing these risks, yet existing methods achieve limited detection rates, particularly at the low false-positive thresholds required for practical privacy auditing. We present EZ-MIA, a membership inference attack that exploits a key observation: memorization manifests most strongly at error positions, specifically tokens where the model predicts incorrectly yet still shows elevated probability for training examples. We introduce the Error Zone (EZ) score, which measures the directional imbalance of probability shifts at error positions relative to a pretrained reference model. This principled statistic requires only two forward passes per query and no model training of any kind. On WikiText with GPT-2, EZ-MIA achieves 3.8x higher detection than the previous state-of-the-art under identical conditions (66.3% versus 17.5% true positive rate at 1% false positive rate), with near-perfect discrimination (AUC 0.98). At the stringent 0.1% FPR threshold critical for real-world auditing, we achieve 8x higher detection than prior work (14.0% versus 1.8%), requiring no reference model training. These gains extend to larger architectures: on AG News with Llama-2-7B, we achieve 3x higher detection (46.7% versus 15.8% TPR at 1% FPR). These results establish that privacy risks of fine-tuned language models are substantially greater than previously understood, with implications for both privacy auditing and deployment decisions. Code is available at https://github.com/JetBrains-Research/ez-mia.
Towards Fast Coarse-graining and Equation Discovery with Foundation Inference Models
Oct 14, 2025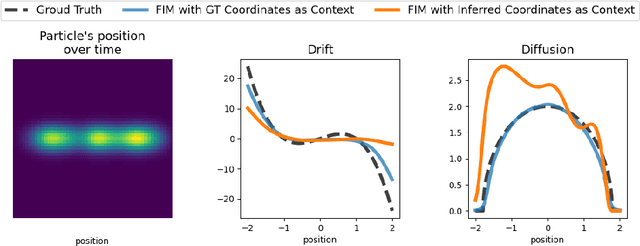
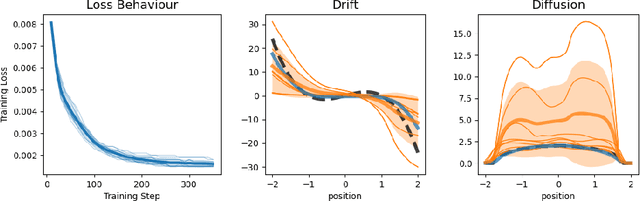
High-dimensional recordings of dynamical processes are often characterized by a much smaller set of effective variables, evolving on low-dimensional manifolds. Identifying these latent dynamics requires solving two intertwined problems: discovering appropriate coarse-grained variables and simultaneously fitting the governing equations. Most machine learning approaches tackle these tasks jointly by training autoencoders together with models that enforce dynamical consistency. We propose to decouple the two problems by leveraging the recently introduced Foundation Inference Models (FIMs). FIMs are pretrained models that estimate the infinitesimal generators of dynamical systems (e.g., the drift and diffusion of a stochastic differential equation) in zero-shot mode. By amortizing the inference of the dynamics through a FIM with frozen weights, and training only the encoder-decoder map, we define a simple, simulation-consistent loss that stabilizes representation learning. A proof of concept on a stochastic double-well system with semicircle diffusion, embedded into synthetic video data, illustrates the potential of this approach for fast and reusable coarse-graining pipelines.
On Foundation Models for Temporal Point Processes to Accelerate Scientific Discovery
Oct 14, 2025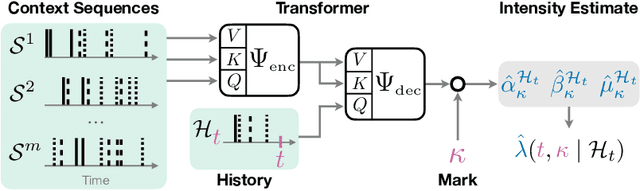
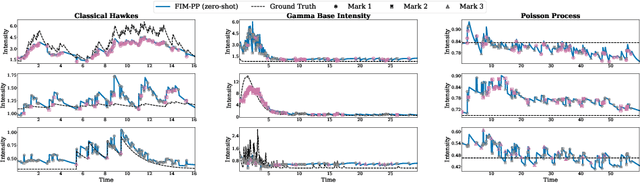
Many scientific fields, from medicine to seismology, rely on analyzing sequences of events over time to understand complex systems. Traditionally, machine learning models must be built and trained from scratch for each new dataset, which is a slow and costly process. We introduce a new approach: a single, powerful model that learns the underlying patterns of event data in context. We trained this "foundation model" on millions of simulated event sequences, teaching it a general-purpose understanding of how events can unfold. As a result, our model can analyze new scientific data instantly, without retraining, simply by looking at a few examples from the dataset. It can also be quickly fine-tuned for even higher accuracy. This approach makes sophisticated event analysis more accessible and accelerates the pace of scientific discovery.
Foundation Inference Models for Stochastic Differential Equations: A Transformer-based Approach for Zero-shot Function Estimation
Feb 26, 2025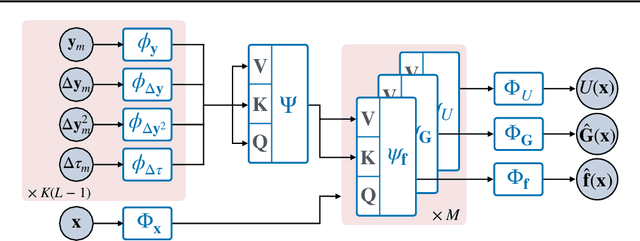
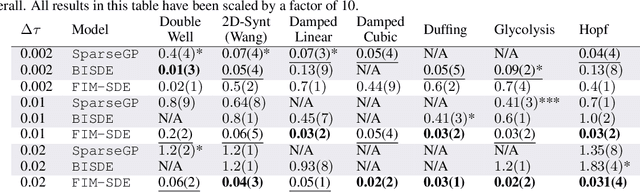
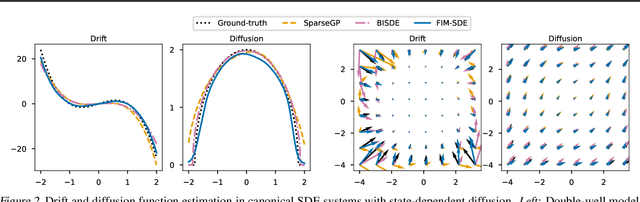
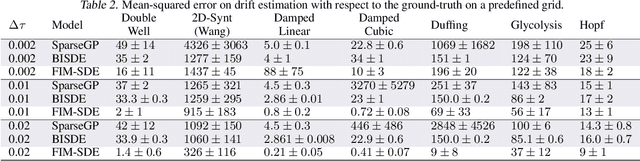
Stochastic differential equations (SDEs) describe dynamical systems where deterministic flows, governed by a drift function, are superimposed with random fluctuations dictated by a diffusion function. The accurate estimation (or discovery) of these functions from data is a central problem in machine learning, with wide application across natural and social sciences alike. Yet current solutions are brittle, and typically rely on symbolic regression or Bayesian non-parametrics. In this work, we introduce FIM-SDE (Foundation Inference Model for SDEs), a transformer-based recognition model capable of performing accurate zero-shot estimation of the drift and diffusion functions of SDEs, from noisy and sparse observations on empirical processes of different dimensionalities. Leveraging concepts from amortized inference and neural operators, we train FIM-SDE in a supervised fashion, to map a large set of noisy and discretely observed SDE paths to their corresponding drift and diffusion functions. We demonstrate that one and the same (pretrained) FIM-SDE achieves robust zero-shot function estimation (i.e. without any parameter fine-tuning) across a wide range of synthetic and real-world processes, from canonical SDE systems (e.g. double-well dynamics or weakly perturbed Hopf bifurcations) to human motion recordings and oil price and wind speed fluctuations.
Foundation Inference Models for Markov Jump Processes
Jun 10, 2024



Markov jump processes are continuous-time stochastic processes which describe dynamical systems evolving in discrete state spaces. These processes find wide application in the natural sciences and machine learning, but their inference is known to be far from trivial. In this work we introduce a methodology for zero-shot inference of Markov jump processes (MJPs), on bounded state spaces, from noisy and sparse observations, which consists of two components. First, a broad probability distribution over families of MJPs, as well as over possible observation times and noise mechanisms, with which we simulate a synthetic dataset of hidden MJPs and their noisy observation process. Second, a neural network model that processes subsets of the simulated observations, and that is trained to output the initial condition and rate matrix of the target MJP in a supervised way. We empirically demonstrate that one and the same (pretrained) model can infer, in a zero-shot fashion, hidden MJPs evolving in state spaces of different dimensionalities. Specifically, we infer MJPs which describe (i) discrete flashing ratchet systems, which are a type of Brownian motors, and the conformational dynamics in (ii) molecular simulations, (iii) experimental ion channel data and (iv) simple protein folding models. What is more, we show that our model performs on par with state-of-the-art models which are finetuned to the target datasets.
Foundational Inference Models for Dynamical Systems
Feb 12, 2024



Ordinary differential equations (ODEs) underlie dynamical systems which serve as models for a vast number of natural and social phenomena. Yet inferring the ODE that best describes a set of noisy observations on one such phenomenon can be remarkably challenging, and the models available to achieve it tend to be highly specialized and complex too. In this work we propose a novel supervised learning framework for zero-shot inference of ODEs from noisy data. We first generate large datasets of one-dimensional ODEs, by sampling distributions over the space of initial conditions, and the space of vector fields defining them. We then learn neural maps between noisy observations on the solutions of these equations, and their corresponding initial condition and vector fields. The resulting models, which we call foundational inference models (FIM), can be (i) copied and matched along the time dimension to increase their resolution; and (ii) copied and composed to build inference models of any dimensionality, without the need of any finetuning. We use FIM to model both ground-truth dynamical systems of different dimensionalities and empirical time series data in a zero-shot fashion, and outperform state-of-the-art models which are finetuned to these systems. Our (pretrained) FIMs are available online
Neural Dynamic Focused Topic Model
Jan 26, 2023Topic models and all their variants analyse text by learning meaningful representations through word co-occurrences. As pointed out by Williamson et al. (2010), such models implicitly assume that the probability of a topic to be active and its proportion within each document are positively correlated. This correlation can be strongly detrimental in the case of documents created over time, simply because recent documents are likely better described by new and hence rare topics. In this work we leverage recent advances in neural variational inference and present an alternative neural approach to the dynamic Focused Topic Model. Indeed, we develop a neural model for topic evolution which exploits sequences of Bernoulli random variables in order to track the appearances of topics, thereby decoupling their activities from their proportions. We evaluate our model on three different datasets (the UN general debates, the collection of NeurIPS papers, and the ACL Anthology dataset) and show that it (i) outperforms state-of-the-art topic models in generalization tasks and (ii) performs comparably to them on prediction tasks, while employing roughly the same number of parameters, and converging about two times faster. Source code to reproduce our experiments is available online.
The future is different: Large pre-trained language models fail in prediction tasks
Nov 02, 2022Large pre-trained language models (LPLM) have shown spectacular success when fine-tuned on downstream supervised tasks. Yet, it is known that their performance can drastically drop when there is a distribution shift between the data used during training and that used at inference time. In this paper we focus on data distributions that naturally change over time and introduce four new REDDIT datasets, namely the WALLSTREETBETS, ASKSCIENCE, THE DONALD, and POLITICS sub-reddits. First, we empirically demonstrate that LPLM can display average performance drops of about 88% (in the best case!) when predicting the popularity of future posts from sub-reddits whose topic distribution changes with time. We then introduce a simple methodology that leverages neural variational dynamic topic models and attention mechanisms to infer temporal language model representations for regression tasks. Our models display performance drops of only about 40% in the worst cases (2% in the best ones) when predicting the popularity of future posts, while using only about 7% of the total number of parameters of LPLM and providing interpretable representations that offer insight into real-world events, like the GameStop short squeeze of 2021