 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWILTing Trees: Interpreting the Distance Between MPNN Embeddings
May 30, 2025We investigate the distance function learned by message passing neural networks (MPNNs) in specific tasks, aiming to capture the functional distance between prediction targets that MPNNs implicitly learn. This contrasts with previous work, which links MPNN distances on arbitrary tasks to structural distances on graphs that ignore task-specific information. To address this gap, we distill the distance between MPNN embeddings into an interpretable graph distance. Our method uses optimal transport on the Weisfeiler Leman Labeling Tree (WILT), where the edge weights reveal subgraphs that strongly influence the distance between embeddings. This approach generalizes two well-known graph kernels and can be computed in linear time. Through extensive experiments, we demonstrate that MPNNs define the relative position of embeddings by focusing on a small set of subgraphs that are known to be functionally important in the domain.
Logical Distillation of Graph Neural Networks
Jun 11, 2024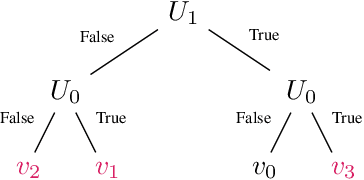
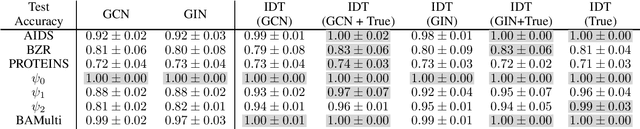
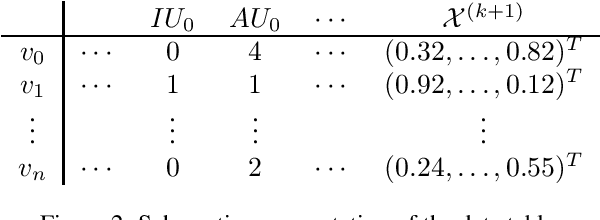
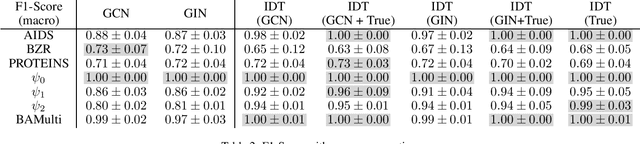
We present a logic based interpretable model for learning on graphs and an algorithm to distill this model from a Graph Neural Network (GNN). Recent results have shown connections between the expressivity of GNNs and the two-variable fragment of first-order logic with counting quantifiers (C2). We introduce a decision-tree based model which leverages an extension of C2 to distill interpretable logical classifiers from GNNs. We test our approach on multiple GNN architectures. The distilled models are interpretable, succinct, and attain similar accuracy to the underlying GNN. Furthermore, when the ground truth is expressible in C2, our approach outperforms the GNN.
Weisfeiler and Leman Go Loopy: A New Hierarchy for Graph Representational Learning
Mar 20, 2024We introduce $r$-loopy Weisfeiler-Leman ($r$-$\ell{}$WL), a novel hierarchy of graph isomorphism tests and a corresponding GNN framework, $r$-$\ell{}$MPNN, that can count cycles up to length $r + 2$. Most notably, we show that $r$-$\ell{}$WL can count homomorphisms of cactus graphs. This strictly extends classical 1-WL, which can only count homomorphisms of trees and, in fact, is incomparable to $k$-WL for any fixed $k$. We empirically validate the expressive and counting power of the proposed $r$-$\ell{}$MPNN on several synthetic datasets and present state-of-the-art predictive performance on various real-world datasets. The code is available at https://github.com/RPaolino/loopy
An Empirical Evaluation of the Rashomon Effect in Explainable Machine Learning
Jun 29, 2023The Rashomon Effect describes the following phenomenon: for a given dataset there may exist many models with equally good performance but with different solution strategies. The Rashomon Effect has implications for Explainable Machine Learning, especially for the comparability of explanations. We provide a unified view on three different comparison scenarios and conduct a quantitative evaluation across different datasets, models, attribution methods, and metrics. We find that hyperparameter-tuning plays a role and that metric selection matters. Our results provide empirical support for previously anecdotal evidence and exhibit challenges for both scientists and practitioners.
Expectation-Complete Graph Representations with Homomorphisms
Jun 09, 2023We investigate novel random graph embeddings that can be computed in expected polynomial time and that are able to distinguish all non-isomorphic graphs in expectation. Previous graph embeddings have limited expressiveness and either cannot distinguish all graphs or cannot be computed efficiently for every graph. To be able to approximate arbitrary functions on graphs, we are interested in efficient alternatives that become arbitrarily expressive with increasing resources. Our approach is based on Lov\'asz' characterisation of graph isomorphism through an infinite dimensional vector of homomorphism counts. Our empirical evaluation shows competitive results on several benchmark graph learning tasks.
Retention Is All You Need
Apr 06, 2023



Skilled employees are usually seen as the most important pillar of an organization. Despite this, most organizations face high attrition and turnover rates. While several machine learning models have been developed for analyzing attrition and its causal factors, the interpretations of those models remain opaque. In this paper, we propose the HR-DSS approach, which stands for Human Resource Decision Support System, and uses explainable AI for employee attrition problems. The system is designed to assist human resource departments in interpreting the predictions provided by machine learning models. In our experiments, eight machine learning models are employed to provide predictions, and the results achieved by the best-performing model are further processed by the SHAP explainability process. We optimize both the correctness and explanation of the results. Furthermore, using "What-if-analysis", we aim to observe plausible causes for attrition of an individual employee. The results show that by adjusting the specific dominant features of each individual, employee attrition can turn into employee retention through informative business decisions. Reducing attrition is not only a problem for any specific organization but also, in some countries, becomes a significant societal problem that impacts the well-being of both employers and employees.
A New Aligned Simple German Corpus
Sep 06, 2022
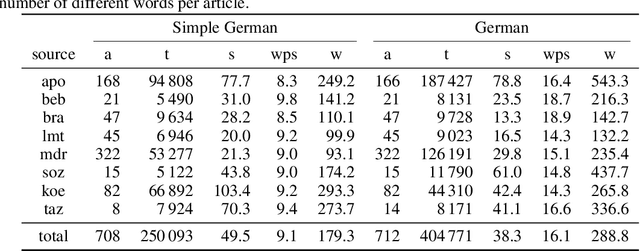
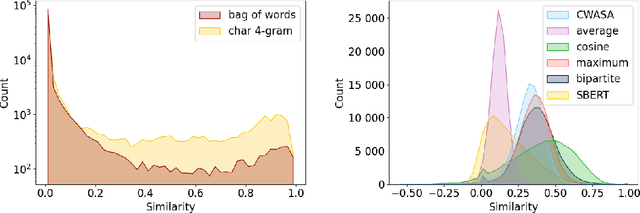
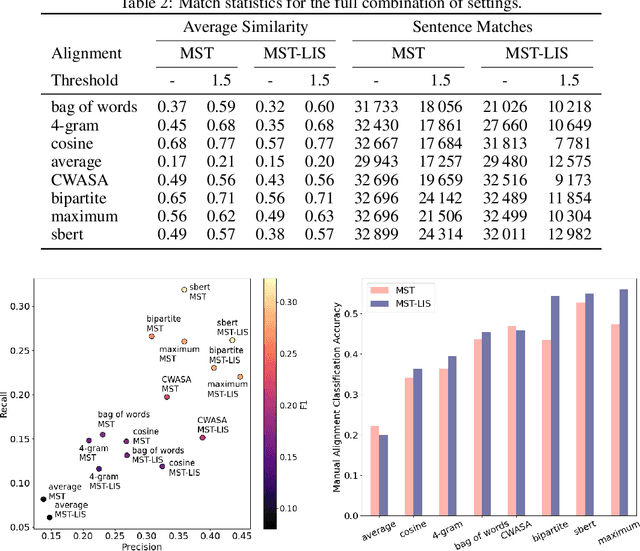
"Leichte Sprache", the German counterpart to Simple English, is a regulated language aiming to facilitate complex written language that would otherwise stay inaccessible to different groups of people. We present a new sentence-aligned monolingual corpus for Simple German -- German. It contains multiple document-aligned sources which we have aligned using automatic sentence-alignment methods. We evaluate our alignments based on a manually labelled subset of aligned documents. The quality of our sentence alignments, as measured by F1-score, surpasses previous work. We publish the dataset under CC BY-SA and the accompanying code under MIT license.
Hidden Schema Networks
Jul 08, 2022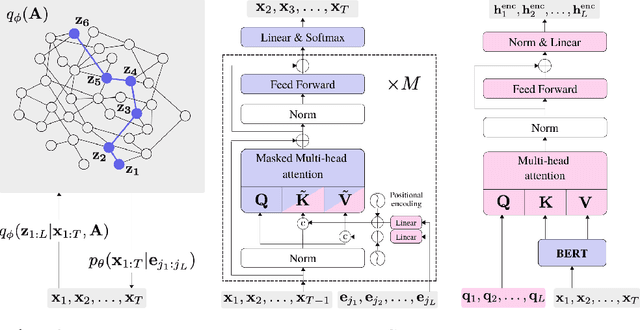

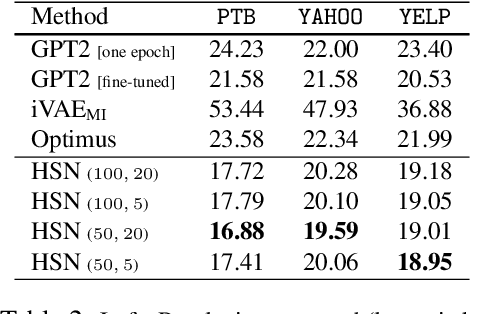
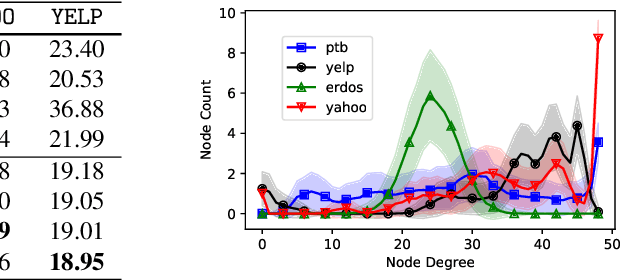
Most modern language models infer representations that, albeit powerful, lack both compositionality and semantic interpretability. Starting from the assumption that a large proportion of semantic content is necessarily relational, we introduce a neural language model that discovers networks of symbols (schemata) from text datasets. Using a variational autoencoder (VAE) framework, our model encodes sentences into sequences of symbols (composed representation), which correspond to the nodes visited by biased random walkers on a global latent graph. Sentences are then generated back, conditioned on the selected symbol sequences. We first demonstrate that the model is able to uncover ground-truth graphs from artificially generated datasets of random token sequences. Next we leverage pretrained BERT and GPT-2 language models as encoder and decoder, respectively, to train our model on language modelling tasks. Qualitatively, our results show that the model is able to infer schema networks encoding different aspects of natural language. Quantitatively, the model achieves state-of-the-art scores on VAE language modeling benchmarks. Source code to reproduce our experiments is available at https://github.com/ramsesjsf/HiddenSchemaNetworks
Graph Filtration Kernels
Oct 22, 2021
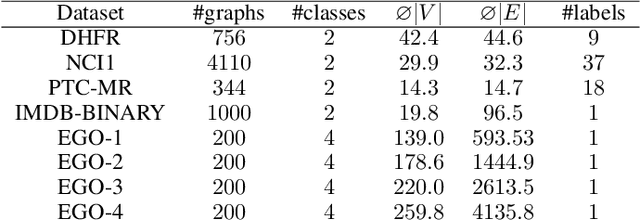
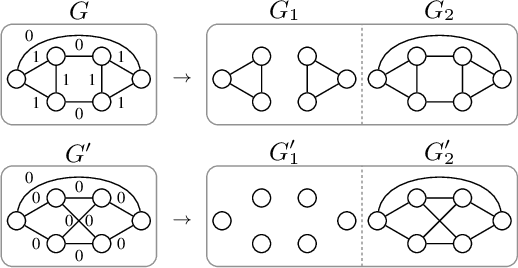
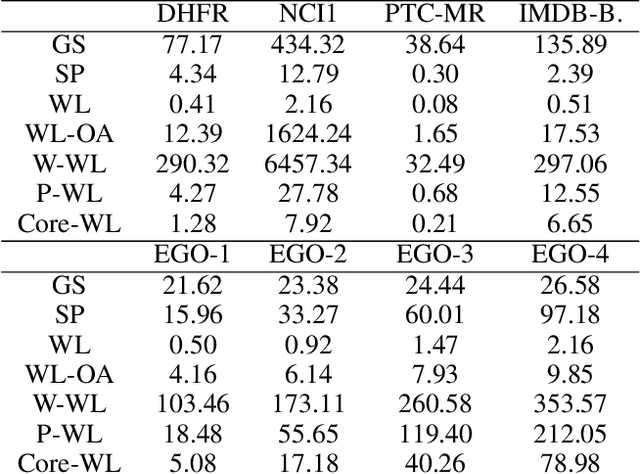
The majority of popular graph kernels is based on the concept of Haussler's $\mathcal{R}$-convolution kernel and defines graph similarities in terms of mutual substructures. In this work, we enrich these similarity measures by considering graph filtrations: Using meaningful orders on the set of edges, which allow to construct a sequence of nested graphs, we can consider a graph at multiple granularities. For one thing, this provides access to features on different levels of resolution. Furthermore, rather than to simply compare frequencies of features in graphs, it allows for their comparison in terms of when and for how long they exist in the sequences. In this work, we propose a family of graph kernels that incorporate these existence intervals of features. While our approach can be applied to arbitrary graph features, we particularly highlight Weisfeiler-Lehman vertex labels, leading to efficient kernels. We show that using Weisfeiler-Lehman labels over certain filtrations strictly increases the expressive power over the ordinary Weisfeiler-Lehman procedure in terms of deciding graph isomorphism. In fact, this result directly yields more powerful graph kernels based on such features and has implications to graph neural networks due to their close relationship to the Weisfeiler-Lehman method. We empirically validate the expressive power of our graph kernels and show significant improvements over state-of-the-art graph kernels in terms of predictive performance on various real-world benchmark datasets.
Explainable Machine Learning with Prior Knowledge: An Overview
May 21, 2021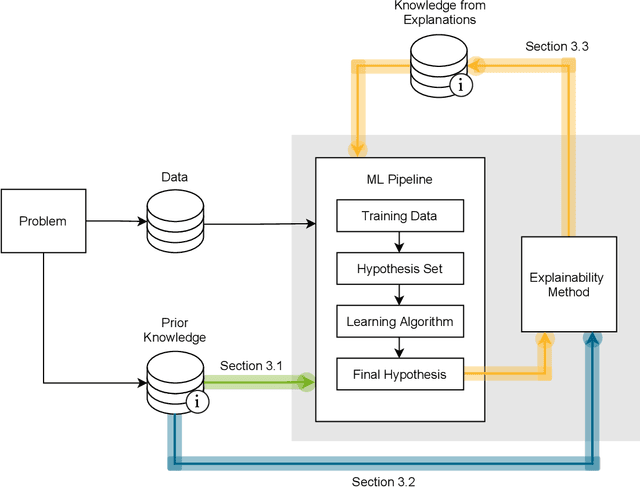

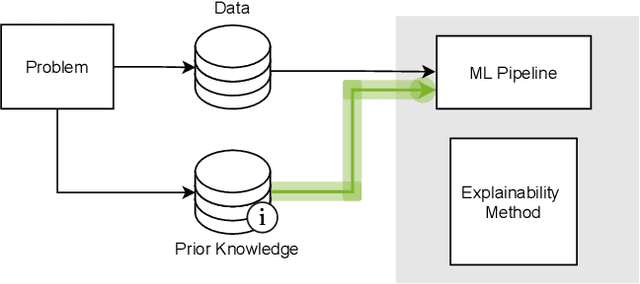
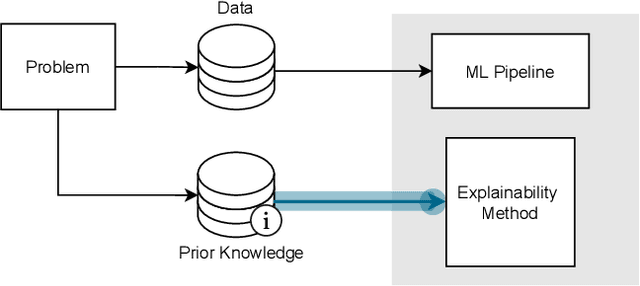
This survey presents an overview of integrating prior knowledge into machine learning systems in order to improve explainability. The complexity of machine learning models has elicited research to make them more explainable. However, most explainability methods cannot provide insight beyond the given data, requiring additional information about the context. We propose to harness prior knowledge to improve upon the explanation capabilities of machine learning models. In this paper, we present a categorization of current research into three main categories which either integrate knowledge into the machine learning pipeline, into the explainability method or derive knowledge from explanations. To classify the papers, we build upon the existing taxonomy of informed machine learning and extend it from the perspective of explainability. We conclude with open challenges and research directions.