 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Representational Learning: When Does More Expressivity Hurt Generalization?
May 16, 2025Graph Neural Networks (GNNs) are powerful tools for learning on structured data, yet the relationship between their expressivity and predictive performance remains unclear. We introduce a family of premetrics that capture different degrees of structural similarity between graphs and relate these similarities to generalization, and consequently, the performance of expressive GNNs. By considering a setting where graph labels are correlated with structural features, we derive generalization bounds that depend on the distance between training and test graphs, model complexity, and training set size. These bounds reveal that more expressive GNNs may generalize worse unless their increased complexity is balanced by a sufficiently large training set or reduced distance between training and test graphs. Our findings relate expressivity and generalization, offering theoretical insights supported by empirical results.
Weisfeiler and Leman Go Loopy: A New Hierarchy for Graph Representational Learning
Mar 20, 2024We introduce $r$-loopy Weisfeiler-Leman ($r$-$\ell{}$WL), a novel hierarchy of graph isomorphism tests and a corresponding GNN framework, $r$-$\ell{}$MPNN, that can count cycles up to length $r + 2$. Most notably, we show that $r$-$\ell{}$WL can count homomorphisms of cactus graphs. This strictly extends classical 1-WL, which can only count homomorphisms of trees and, in fact, is incomparable to $k$-WL for any fixed $k$. We empirically validate the expressive and counting power of the proposed $r$-$\ell{}$MPNN on several synthetic datasets and present state-of-the-art predictive performance on various real-world datasets. The code is available at https://github.com/RPaolino/loopy
A Fractional Graph Laplacian Approach to Oversmoothing
May 22, 2023



Graph neural networks (GNNs) have shown state-of-the-art performances in various applications. However, GNNs often struggle to capture long-range dependencies in graphs due to oversmoothing. In this paper, we generalize the concept of oversmoothing from undirected to directed graphs. To this aim, we extend the notion of Dirichlet energy by considering a directed symmetrically normalized Laplacian. As vanilla graph convolutional networks are prone to oversmooth, we adopt a neural graph ODE framework. Specifically, we propose fractional graph Laplacian neural ODEs, which describe non-local dynamics. We prove that our approach allows propagating information between distant nodes while maintaining a low probability of long-distance jumps. Moreover, we show that our method is more flexible with respect to the convergence of the graph's Dirichlet energy, thereby mitigating oversmoothing. We conduct extensive experiments on synthetic and real-world graphs, both directed and undirected, demonstrating our method's versatility across diverse graph homophily levels. Our code is available at https://github.com/RPaolino/fLode .
Unveiling the Sampling Density in Non-Uniform Geometric Graphs
Oct 15, 2022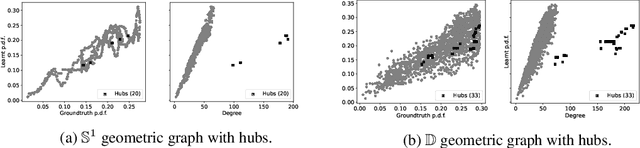



A powerful framework for studying graphs is to consider them as geometric graphs: nodes are randomly sampled from an underlying metric space, and any pair of nodes is connected if their distance is less than a specified neighborhood radius. Currently, the literature mostly focuses on uniform sampling and constant neighborhood radius. However, real-world graphs are likely to be better represented by a model in which the sampling density and the neighborhood radius can both vary over the latent space. For instance, in a social network communities can be modeled as densely sampled areas, and hubs as nodes with larger neighborhood radius. In this work, we first perform a rigorous mathematical analysis of this (more general) class of models, including derivations of the resulting graph shift operators. The key insight is that graph shift operators should be corrected in order to avoid potential distortions introduced by the non-uniform sampling. Then, we develop methods to estimate the unknown sampling density in a self-supervised fashion. Finally, we present exemplary applications in which the learnt density is used to 1) correct the graph shift operator and improve performance on a variety of tasks, 2) improve pooling, and 3) extract knowledge from networks. Our experimental findings support our theory and provide strong evidence for our model.