 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fresh Look at Lamarckian Evolution and the Baldwin Effect
May 27, 2026Baldwinian and Lamarckian evolution have existed for a long time in evolutionary algorithms (EAs) without ever dominating the academic literature or practical applications. In this work, we use modern empirical and theoretical methods to revisit Lamarckian and Baldwinian evolution and rigorously compare them with the generic Darwinian evolution. On the empirical side, we run a comprehensive suite of experiments on graphs from six different datasets from the recent GraphBench benchmark on Maximum Independent Set and Maximum Cut problems. Our results show that Baldwinian and Lamarckian evolution consistently outperform Darwinian evolution, confirming the great potential of local search augmented evolutionary algorithms. Notably, in the great majority of cases, all EAs outperform recent deep learning baselines and approach the performance of highly specialised heuristic and exact solvers. We furthermore report a high-performing set of generalist parameters for all studied evolution types that we hope will be of use to practitioners in future. On the theoretical side, we extend the existing Deceptive Leading Block benchmark to arbitrary block length and use tools from modern theoretical runtime analysis to prove upper and lower bounds on the expected runtime. For block lengths greater than two, Baldwinian evolution is asymptotically faster than Lamarckian which is asymptotically faster than Darwinian evolution. When accounting for the cost of the local search procedure in fitness evaluations, the ordering depends on the implementation with Baldwinian evolution staying fastest from small block lengths onwards, explaining its strong empirical performance.
GASS: Geometry-Aware Spherical Sampling for Disentangled Diversity Enhancement in Text-to-Image Generation
Feb 19, 2026Despite high semantic alignment, modern text-to-image (T2I) generative models still struggle to synthesize diverse images from a given prompt. This lack of diversity not only restricts user choice, but also risks amplifying societal biases. In this work, we enhance the T2I diversity through a geometric lens. Unlike most existing methods that rely primarily on entropy-based guidance to increase sample dissimilarity, we introduce Geometry-Aware Spherical Sampling (GASS) to enhance diversity by explicitly controlling both prompt-dependent and prompt-independent sources of variation. Specifically, we decompose the diversity measure in CLIP embeddings using two orthogonal directions: the text embedding, which captures semantic variation related to the prompt, and an identified orthogonal direction that captures prompt-independent variation (e.g., backgrounds). Based on this decomposition, GASS increases the geometric projection spread of generated image embeddings along both axes and guides the T2I sampling process via expanded predictions along the generation trajectory. Our experiments on different frozen T2I backbones (U-Net and DiT, diffusion and flow) and benchmarks demonstrate the effectiveness of disentangled diversity enhancement with minimal impact on image fidelity and semantic alignment.
Position: Don't be Afraid of Over-Smoothing And Over-Squashing
Jan 12, 2026Over-smoothing and over-squashing have been extensively studied in the literature on Graph Neural Networks (GNNs) over the past years. We challenge this prevailing focus in GNN research, arguing that these phenomena are less critical for practical applications than assumed. We suggest that performance decreases often stem from uninformative receptive fields rather than over-smoothing. We support this position with extensive experiments on several standard benchmark datasets, demonstrating that accuracy and over-smoothing are mostly uncorrelated and that optimal model depths remain small even with mitigation techniques, thus highlighting the negligible role of over-smoothing. Similarly, we challenge that over-squashing is always detrimental in practical applications. Instead, we posit that the distribution of relevant information over the graph frequently factorises and is often localised within a small k-hop neighbourhood, questioning the necessity of jointly observing entire receptive fields or engaging in an extensive search for long-range interactions. The results of our experiments show that architectural interventions designed to mitigate over-squashing fail to yield significant performance gains. This position paper advocates for a paradigm shift in theoretical research, urging a diligent analysis of learning tasks and datasets using statistics that measure the underlying distribution of label-relevant information to better understand their localisation and factorisation.
Enhancing Graph Classification Robustness with Singular Pooling
Oct 26, 2025Graph Neural Networks (GNNs) have achieved strong performance across a range of graph representation learning tasks, yet their adversarial robustness in graph classification remains underexplored compared to node classification. While most existing defenses focus on the message-passing component, this work investigates the overlooked role of pooling operations in shaping robustness. We present a theoretical analysis of standard flat pooling methods (sum, average and max), deriving upper bounds on their adversarial risk and identifying their vulnerabilities under different attack scenarios and graph structures. Motivated by these insights, we propose \textit{Robust Singular Pooling (RS-Pool)}, a novel pooling strategy that leverages the dominant singular vector of the node embedding matrix to construct a robust graph-level representation. We theoretically investigate the robustness of RS-Pool and interpret the resulting bound leading to improved understanding of our proposed pooling operator. While our analysis centers on Graph Convolutional Networks (GCNs), RS-Pool is model-agnostic and can be implemented efficiently via power iteration. Empirical results on real-world benchmarks show that RS-Pool provides better robustness than the considered pooling methods when subject to state-of-the-art adversarial attacks while maintaining competitive clean accuracy. Our code is publicly available at:\href{https://github.com/king/rs-pool}{https://github.com/king/rs-pool}.
If You Want to Be Robust, Be Wary of Initialization
Oct 26, 2025Graph Neural Networks (GNNs) have demonstrated remarkable performance across a spectrum of graph-related tasks, however concerns persist regarding their vulnerability to adversarial perturbations. While prevailing defense strategies focus primarily on pre-processing techniques and adaptive message-passing schemes, this study delves into an under-explored dimension: the impact of weight initialization and associated hyper-parameters, such as training epochs, on a model's robustness. We introduce a theoretical framework bridging the connection between initialization strategies and a network's resilience to adversarial perturbations. Our analysis reveals a direct relationship between initial weights, number of training epochs and the model's vulnerability, offering new insights into adversarial robustness beyond conventional defense mechanisms. While our primary focus is on GNNs, we extend our theoretical framework, providing a general upper-bound applicable to Deep Neural Networks. Extensive experiments, spanning diverse models and real-world datasets subjected to various adversarial attacks, validate our findings. We illustrate that selecting appropriate initialization not only ensures performance on clean datasets but also enhances model robustness against adversarial perturbations, with observed gaps of up to 50\% compared to alternative initialization approaches.
Graph Representational Learning: When Does More Expressivity Hurt Generalization?
May 16, 2025Graph Neural Networks (GNNs) are powerful tools for learning on structured data, yet the relationship between their expressivity and predictive performance remains unclear. We introduce a family of premetrics that capture different degrees of structural similarity between graphs and relate these similarities to generalization, and consequently, the performance of expressive GNNs. By considering a setting where graph labels are correlated with structural features, we derive generalization bounds that depend on the distance between training and test graphs, model complexity, and training set size. These bounds reveal that more expressive GNNs may generalize worse unless their increased complexity is balanced by a sufficiently large training set or reduced distance between training and test graphs. Our findings relate expressivity and generalization, offering theoretical insights supported by empirical results.
Gaussian Mixture Models Based Augmentation Enhances GNN Generalization
Nov 13, 2024



Graph Neural Networks (GNNs) have shown great promise in tasks like node and graph classification, but they often struggle to generalize, particularly to unseen or out-of-distribution (OOD) data. These challenges are exacerbated when training data is limited in size or diversity. To address these issues, we introduce a theoretical framework using Rademacher complexity to compute a regret bound on the generalization error and then characterize the effect of data augmentation. This framework informs the design of GMM-GDA, an efficient graph data augmentation (GDA) algorithm leveraging the capability of Gaussian Mixture Models (GMMs) to approximate any distribution. Our approach not only outperforms existing augmentation techniques in terms of generalization but also offers improved time complexity, making it highly suitable for real-world applications.
Post-Hoc Robustness Enhancement in Graph Neural Networks with Conditional Random Fields
Nov 08, 2024



Graph Neural Networks (GNNs), which are nowadays the benchmark approach in graph representation learning, have been shown to be vulnerable to adversarial attacks, raising concerns about their real-world applicability. While existing defense techniques primarily concentrate on the training phase of GNNs, involving adjustments to message passing architectures or pre-processing methods, there is a noticeable gap in methods focusing on increasing robustness during inference. In this context, this study introduces RobustCRF, a post-hoc approach aiming to enhance the robustness of GNNs at the inference stage. Our proposed method, founded on statistical relational learning using a Conditional Random Field, is model-agnostic and does not require prior knowledge about the underlying model architecture. We validate the efficacy of this approach across various models, leveraging benchmark node classification datasets.
Centrality Graph Shift Operators for Graph Neural Networks
Nov 07, 2024
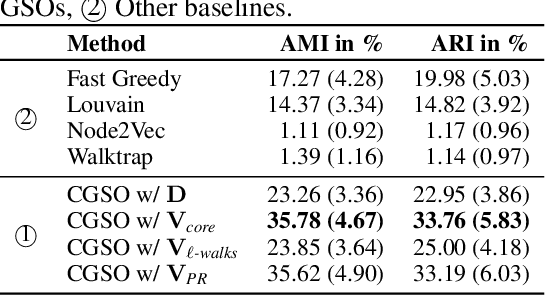
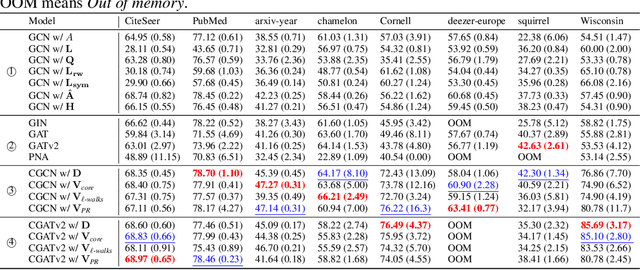
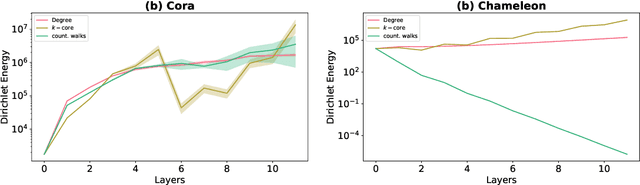
Graph Shift Operators (GSOs), such as the adjacency and graph Laplacian matrices, play a fundamental role in graph theory and graph representation learning. Traditional GSOs are typically constructed by normalizing the adjacency matrix by the degree matrix, a local centrality metric. In this work, we instead propose and study Centrality GSOs (CGSOs), which normalize adjacency matrices by global centrality metrics such as the PageRank, $k$-core or count of fixed length walks. We study spectral properties of the CGSOs, allowing us to get an understanding of their action on graph signals. We confirm this understanding by defining and running the spectral clustering algorithm based on different CGSOs on several synthetic and real-world datasets. We furthermore outline how our CGSO can act as the message passing operator in any Graph Neural Network and in particular demonstrate strong performance of a variant of the Graph Convolutional Network and Graph Attention Network using our CGSOs on several real-world benchmark datasets.
Graph Neural Networks on Discriminative Graphs of Words
Oct 27, 2024



In light of the recent success of Graph Neural Networks (GNNs) and their ability to perform inference on complex data structures, many studies apply GNNs to the task of text classification. In most previous methods, a heterogeneous graph, containing both word and document nodes, is constructed using the entire corpus and a GNN is used to classify document nodes. In this work, we explore a new Discriminative Graph of Words Graph Neural Network (DGoW-GNN) approach encapsulating both a novel discriminative graph construction and model to classify text. In our graph construction, containing only word nodes and no document nodes, we split the training corpus into disconnected subgraphs according to their labels and weight edges by the pointwise mutual information of the represented words. Our graph construction, for which we provide theoretical motivation, allows us to reformulate the task of text classification as the task of walk classification. We also propose a new model for the graph-based classification of text, which combines a GNN and a sequence model. We evaluate our approach on seven benchmark datasets and find that it is outperformed by several state-of-the-art baseline models. We analyse reasons for this performance difference and hypothesise under which conditions it is likely to change.