 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Matters: When Time Series Foundation Models Fail Under Spectral Shift
Nov 06, 2025Time series foundation models (TSFMs) have shown strong results on public benchmarks, prompting comparisons to a "BERT moment" for time series. Their effectiveness in industrial settings, however, remains uncertain. We examine why TSFMs often struggle to generalize and highlight spectral shift (a mismatch between the dominant frequency components in downstream tasks and those represented during pretraining) as a key factor. We present evidence from an industrial-scale player engagement prediction task in mobile gaming, where TSFMs underperform domain-adapted baselines. To isolate the mechanism, we design controlled synthetic experiments contrasting signals with seen versus unseen frequency bands, observing systematic degradation under spectral mismatch. These findings position frequency awareness as critical for robust TSFM deployment and motivate new pretraining and evaluation protocols that explicitly account for spectral diversity.
If You Want to Be Robust, Be Wary of Initialization
Oct 26, 2025Graph Neural Networks (GNNs) have demonstrated remarkable performance across a spectrum of graph-related tasks, however concerns persist regarding their vulnerability to adversarial perturbations. While prevailing defense strategies focus primarily on pre-processing techniques and adaptive message-passing schemes, this study delves into an under-explored dimension: the impact of weight initialization and associated hyper-parameters, such as training epochs, on a model's robustness. We introduce a theoretical framework bridging the connection between initialization strategies and a network's resilience to adversarial perturbations. Our analysis reveals a direct relationship between initial weights, number of training epochs and the model's vulnerability, offering new insights into adversarial robustness beyond conventional defense mechanisms. While our primary focus is on GNNs, we extend our theoretical framework, providing a general upper-bound applicable to Deep Neural Networks. Extensive experiments, spanning diverse models and real-world datasets subjected to various adversarial attacks, validate our findings. We illustrate that selecting appropriate initialization not only ensures performance on clean datasets but also enhances model robustness against adversarial perturbations, with observed gaps of up to 50\% compared to alternative initialization approaches.
Enhancing Graph Classification Robustness with Singular Pooling
Oct 26, 2025Graph Neural Networks (GNNs) have achieved strong performance across a range of graph representation learning tasks, yet their adversarial robustness in graph classification remains underexplored compared to node classification. While most existing defenses focus on the message-passing component, this work investigates the overlooked role of pooling operations in shaping robustness. We present a theoretical analysis of standard flat pooling methods (sum, average and max), deriving upper bounds on their adversarial risk and identifying their vulnerabilities under different attack scenarios and graph structures. Motivated by these insights, we propose \textit{Robust Singular Pooling (RS-Pool)}, a novel pooling strategy that leverages the dominant singular vector of the node embedding matrix to construct a robust graph-level representation. We theoretically investigate the robustness of RS-Pool and interpret the resulting bound leading to improved understanding of our proposed pooling operator. While our analysis centers on Graph Convolutional Networks (GCNs), RS-Pool is model-agnostic and can be implemented efficiently via power iteration. Empirical results on real-world benchmarks show that RS-Pool provides better robustness than the considered pooling methods when subject to state-of-the-art adversarial attacks while maintaining competitive clean accuracy. Our code is publicly available at:\href{https://github.com/king/rs-pool}{https://github.com/king/rs-pool}.
Efficient Data Selection for Training Genomic Perturbation Models
Mar 18, 2025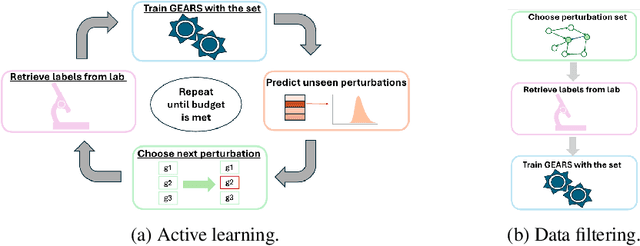
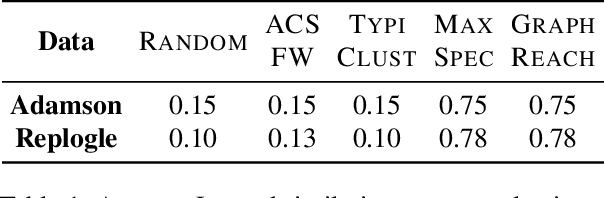
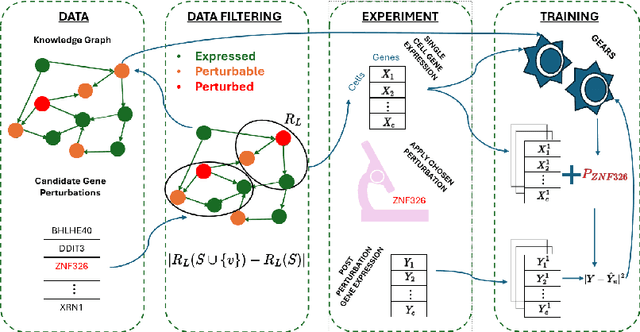
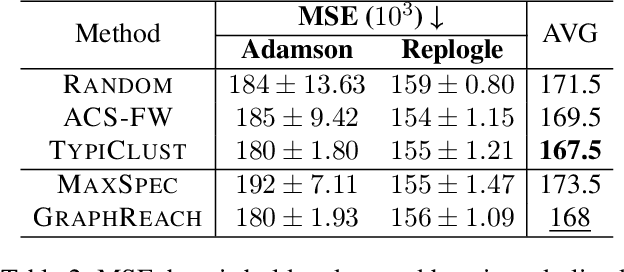
Genomic studies, including CRISPR-based PerturbSeq analyses, face a vast hypothesis space, while gene perturbations remain costly and time-consuming. Gene expression models based on graph neural networks are trained to predict the outcomes of gene perturbations to facilitate such experiments. Active learning methods are often employed to train these models due to the cost of the genomic experiments required to build the training set. However, poor model initialization in active learning can result in suboptimal early selections, wasting time and valuable resources. While typical active learning mitigates this issue over many iterations, the limited number of experimental cycles in genomic studies exacerbates the risk. To this end, we propose graph-based one-shot data selection methods for training gene expression models. Unlike active learning, one-shot data selection predefines the gene perturbations before training, hence removing the initialization bias. The data selection is motivated by theoretical studies of graph neural network generalization. The criteria are defined over the input graph and are optimized with submodular maximization. We compare them empirically to baselines and active learning methods that are state-of-the-art on this problem. The results demonstrate that graph-based one-shot data selection achieves comparable accuracy while alleviating the aforementioned risks.
Unified Approaches in Self-Supervised Event Stream Modeling: Progress and Prospects
Feb 07, 2025



The proliferation of digital interactions across diverse domains, such as healthcare, e-commerce, gaming, and finance, has resulted in the generation of vast volumes of event stream (ES) data. ES data comprises continuous sequences of timestamped events that encapsulate detailed contextual information relevant to each domain. While ES data holds significant potential for extracting actionable insights and enhancing decision-making, its effective utilization is hindered by challenges such as the scarcity of labeled data and the fragmented nature of existing research efforts. Self-Supervised Learning (SSL) has emerged as a promising paradigm to address these challenges by enabling the extraction of meaningful representations from unlabeled ES data. In this survey, we systematically review and synthesize SSL methodologies tailored for ES modeling across multiple domains, bridging the gaps between domain-specific approaches that have traditionally operated in isolation. We present a comprehensive taxonomy of SSL techniques, encompassing both predictive and contrastive paradigms, and analyze their applicability and effectiveness within different application contexts. Furthermore, we identify critical gaps in current research and propose a future research agenda aimed at developing scalable, domain-agnostic SSL frameworks for ES modeling. By unifying disparate research efforts and highlighting cross-domain synergies, this survey aims to accelerate innovation, improve reproducibility, and expand the applicability of SSL to diverse real-world ES challenges.
Expressivity of Representation Learning on Continuous-Time Dynamic Graphs: An Information-Flow Centric Review
Dec 05, 2024Graphs are ubiquitous in real-world applications, ranging from social networks to biological systems, and have inspired the development of Graph Neural Networks (GNNs) for learning expressive representations. While most research has centered on static graphs, many real-world scenarios involve dynamic, temporally evolving graphs, motivating the need for Continuous-Time Dynamic Graph (CTDG) models. This paper provides a comprehensive review of Graph Representation Learning (GRL) on CTDGs with a focus on Self-Supervised Representation Learning (SSRL). We introduce a novel theoretical framework that analyzes the expressivity of CTDG models through an Information-Flow (IF) lens, quantifying their ability to propagate and encode temporal and structural information. Leveraging this framework, we categorize existing CTDG methods based on their suitability for different graph types and application scenarios. Within the same scope, we examine the design of SSRL methods tailored to CTDGs, such as predictive and contrastive approaches, highlighting their potential to mitigate the reliance on labeled data. Empirical evaluations on synthetic and real-world datasets validate our theoretical insights, demonstrating the strengths and limitations of various methods across long-range, bi-partite and community-based graphs. This work offers both a theoretical foundation and practical guidance for selecting and developing CTDG models, advancing the understanding of GRL in dynamic settings.
Post-Hoc Robustness Enhancement in Graph Neural Networks with Conditional Random Fields
Nov 08, 2024Graph Neural Networks (GNNs), which are nowadays the benchmark approach in graph representation learning, have been shown to be vulnerable to adversarial attacks, raising concerns about their real-world applicability. While existing defense techniques primarily concentrate on the training phase of GNNs, involving adjustments to message passing architectures or pre-processing methods, there is a noticeable gap in methods focusing on increasing robustness during inference. In this context, this study introduces RobustCRF, a post-hoc approach aiming to enhance the robustness of GNNs at the inference stage. Our proposed method, founded on statistical relational learning using a Conditional Random Field, is model-agnostic and does not require prior knowledge about the underlying model architecture. We validate the efficacy of this approach across various models, leveraging benchmark node classification datasets.
Atlas-Chat: Adapting Large Language Models for Low-Resource Moroccan Arabic Dialect
Sep 26, 2024We introduce Atlas-Chat, the first-ever collection of large language models specifically developed for dialectal Arabic. Focusing on Moroccan Arabic, also known as Darija, we construct our instruction dataset by consolidating existing Darija language resources, creating novel datasets both manually and synthetically, and translating English instructions with stringent quality control. Atlas-Chat-9B and 2B models, fine-tuned on the dataset, exhibit superior ability in following Darija instructions and performing standard NLP tasks. Notably, our models outperform both state-of-the-art and Arabic-specialized LLMs like LLaMa, Jais, and AceGPT, e.g., achieving a 13% performance boost over a larger 13B model on DarijaMMLU, in our newly introduced evaluation suite for Darija covering both discriminative and generative tasks. Furthermore, we perform an experimental analysis of various fine-tuning strategies and base model choices to determine optimal configurations. All our resources are publicly accessible, and we believe our work offers comprehensive design methodologies of instruction-tuning for low-resource language variants, which are often neglected in favor of data-rich languages by contemporary LLMs.
Bounding the Expected Robustness of Graph Neural Networks Subject to Node Feature Attacks
Apr 27, 2024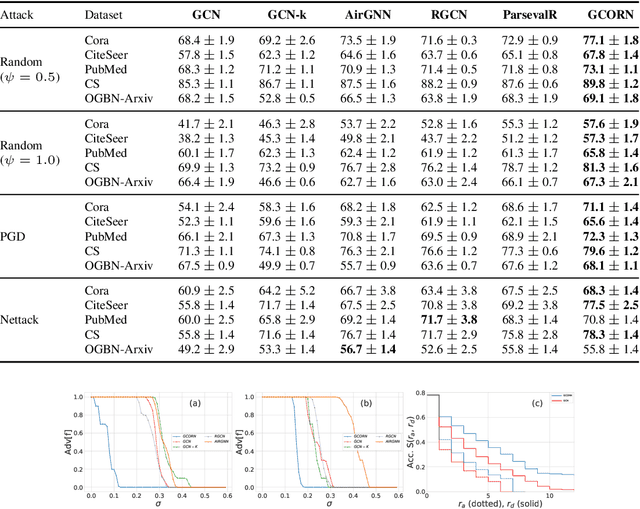
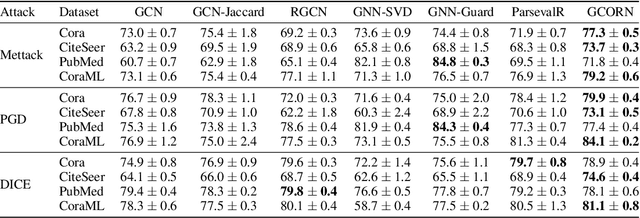


Graph Neural Networks (GNNs) have demonstrated state-of-the-art performance in various graph representation learning tasks. Recently, studies revealed their vulnerability to adversarial attacks. In this work, we theoretically define the concept of expected robustness in the context of attributed graphs and relate it to the classical definition of adversarial robustness in the graph representation learning literature. Our definition allows us to derive an upper bound of the expected robustness of Graph Convolutional Networks (GCNs) and Graph Isomorphism Networks subject to node feature attacks. Building on these findings, we connect the expected robustness of GNNs to the orthonormality of their weight matrices and consequently propose an attack-independent, more robust variant of the GCN, called the Graph Convolutional Orthonormal Robust Networks (GCORNs). We further introduce a probabilistic method to estimate the expected robustness, which allows us to evaluate the effectiveness of GCORN on several real-world datasets. Experimental experiments showed that GCORN outperforms available defense methods. Our code is publicly available at: \href{https://github.com/Sennadir/GCORN}{https://github.com/Sennadir/GCORN}.
A Simple and Yet Fairly Effective Defense for Graph Neural Networks
Feb 21, 2024Graph Neural Networks (GNNs) have emerged as the dominant approach for machine learning on graph-structured data. However, concerns have arisen regarding the vulnerability of GNNs to small adversarial perturbations. Existing defense methods against such perturbations suffer from high time complexity and can negatively impact the model's performance on clean graphs. To address these challenges, this paper introduces NoisyGNNs, a novel defense method that incorporates noise into the underlying model's architecture. We establish a theoretical connection between noise injection and the enhancement of GNN robustness, highlighting the effectiveness of our approach. We further conduct extensive empirical evaluations on the node classification task to validate our theoretical findings, focusing on two popular GNNs: the GCN and GIN. The results demonstrate that NoisyGNN achieves superior or comparable defense performance to existing methods while minimizing added time complexity. The NoisyGNN approach is model-agnostic, allowing it to be integrated with different GNN architectures. Successful combinations of our NoisyGNN approach with existing defense techniques demonstrate even further improved adversarial defense results. Our code is publicly available at: https://github.com/Sennadir/NoisyGNN.