 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Data Selection for Training Genomic Perturbation Models
Mar 18, 2025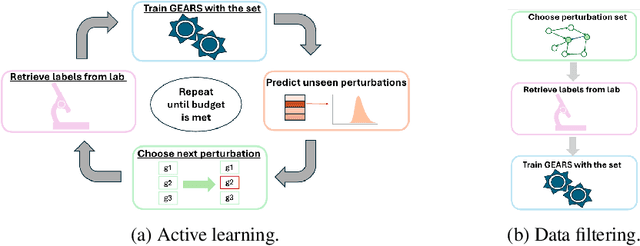
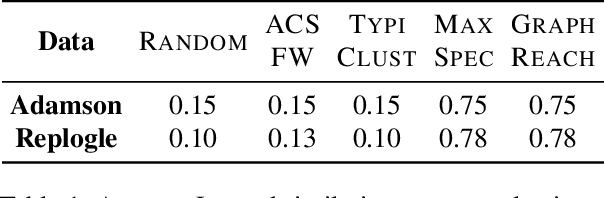
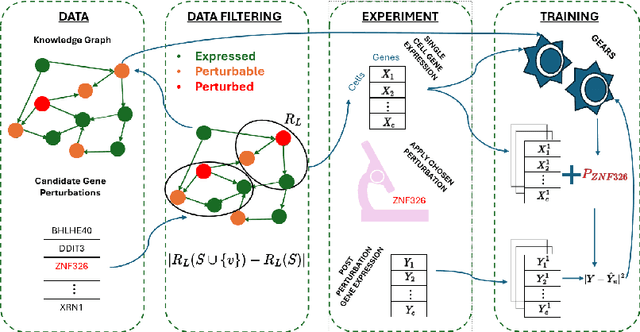
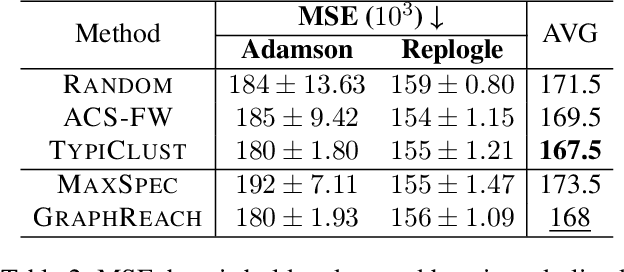
Genomic studies, including CRISPR-based PerturbSeq analyses, face a vast hypothesis space, while gene perturbations remain costly and time-consuming. Gene expression models based on graph neural networks are trained to predict the outcomes of gene perturbations to facilitate such experiments. Active learning methods are often employed to train these models due to the cost of the genomic experiments required to build the training set. However, poor model initialization in active learning can result in suboptimal early selections, wasting time and valuable resources. While typical active learning mitigates this issue over many iterations, the limited number of experimental cycles in genomic studies exacerbates the risk. To this end, we propose graph-based one-shot data selection methods for training gene expression models. Unlike active learning, one-shot data selection predefines the gene perturbations before training, hence removing the initialization bias. The data selection is motivated by theoretical studies of graph neural network generalization. The criteria are defined over the input graph and are optimized with submodular maximization. We compare them empirically to baselines and active learning methods that are state-of-the-art on this problem. The results demonstrate that graph-based one-shot data selection achieves comparable accuracy while alleviating the aforementioned risks.
KAGNNs: Kolmogorov-Arnold Networks meet Graph Learning
Jun 26, 2024



In recent years, Graph Neural Networks (GNNs) have become the de facto tool for learning node and graph representations. Most GNNs typically consist of a sequence of neighborhood aggregation (a.k.a., message passing) layers. Within each of these layers, the representation of each node is updated from an aggregation and transformation of its neighbours representations at the previous layer. The upper bound for the expressive power of message passing GNNs was reached through the use of MLPs as a transformation, due to their universal approximation capabilities. However, MLPs suffer from well-known limitations, which recently motivated the introduction of Kolmogorov-Arnold Networks (KANs). KANs rely on the Kolmogorov-Arnold representation theorem, rendering them a promising alternative to MLPs. In this work, we compare the performance of KANs against that of MLPs in graph learning tasks. We perform extensive experiments on node classification, graph classification and graph regression datasets. Our preliminary results indicate that while KANs are on-par with MLPs in classification tasks, they seem to have a clear advantage in the graph regression tasks.
Graph Neural Networks for Treatment Effect Prediction
Mar 28, 2024



Estimating causal effects in e-commerce tends to involve costly treatment assignments which can be impractical in large-scale settings. Leveraging machine learning to predict such treatment effects without actual intervention is a standard practice to diminish the risk. However, existing methods for treatment effect prediction tend to rely on training sets of substantial size, which are built from real experiments and are thus inherently risky to create. In this work we propose a graph neural network to diminish the required training set size, relying on graphs that are common in e-commerce data. Specifically, we view the problem as node regression with a restricted number of labeled instances, develop a two-model neural architecture akin to previous causal effect estimators, and test varying message-passing layers for encoding. Furthermore, as an extra step, we combine the model with an acquisition function to guide the creation of the training set in settings with extremely low experimental budget. The framework is flexible since each step can be used separately with other models or policies. The experiments on real large-scale networks indicate a clear advantage of our methodology over the state of the art, which in many cases performs close to random underlining the need for models that can generalize with limited labeled samples to reduce experimental risks.
Learning to Maximize Influence
Aug 10, 2021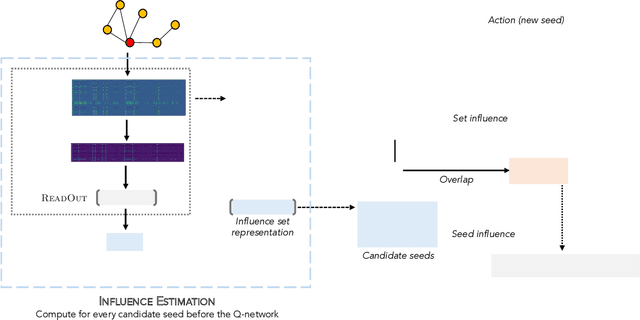


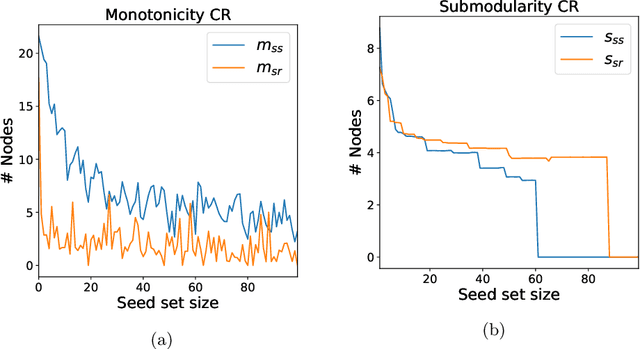
As the field of machine learning for combinatorial optimization advances, traditional problems are resurfaced and readdressed through this new perspective. The overwhelming majority of the literature focuses on small graph problems, while several real-world problems are devoted to large graphs. Here, we focus on two such problems that are related: influence estimation, a \#P-hard counting problem, and influence maximization, an NP-hard problem. We develop GLIE, a Graph Neural Network (GNN) that inherently parameterizes an upper bound of influence estimation and train it on small simulated graphs. Experiments show that GLIE can provide accurate predictions faster than the alternatives for graphs 10 times larger than the train set. More importantly, it can be used on arbitrary large graphs for influence maximization, as the predictions can rank effectively seed sets even when the accuracy deteriorates. To showcase this, we propose a version of a standard Influence Maximization (IM) algorithm where we substitute traditional influence estimation with the predictions of GLIE.We also transfer GLIE into a reinforcement learning model that learns how to choose seeds to maximize influence sequentially using GLIE's hidden representations and predictions. The final results show that the proposed methods surpasses a previous GNN-RL approach and perform on par with a state-of-the-art IM algorithm.
PyTorch Geometric Temporal: Spatiotemporal Signal Processing with Neural Machine Learning Models
Apr 30, 2021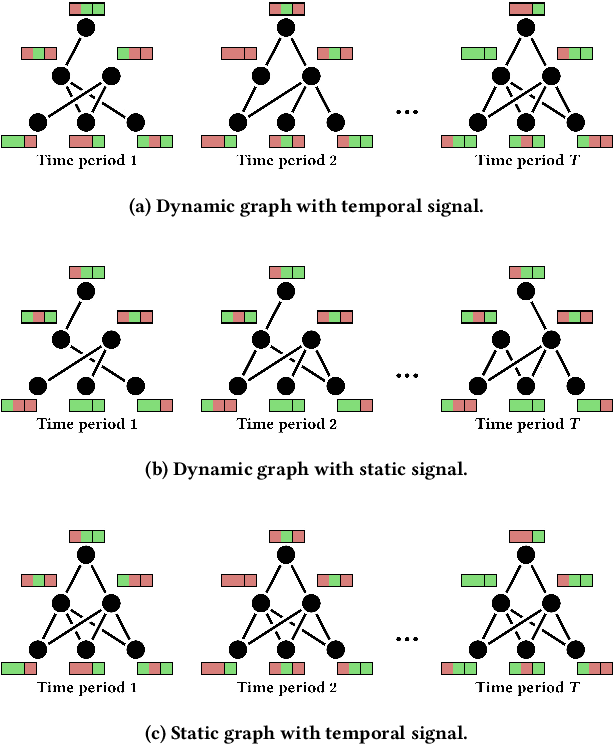
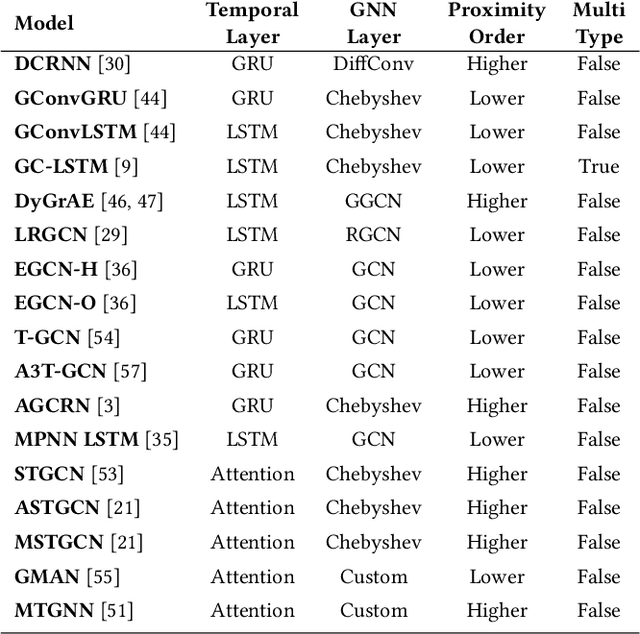
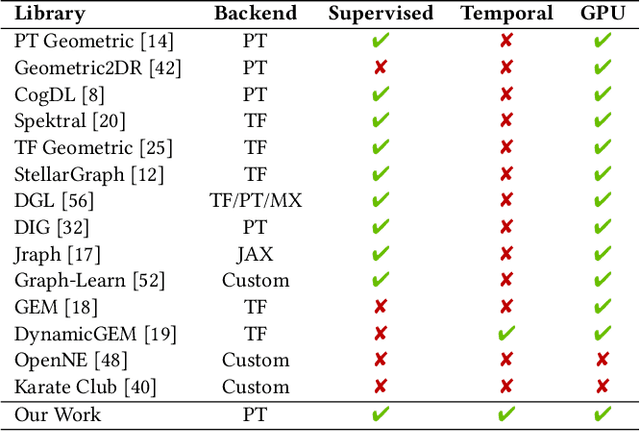
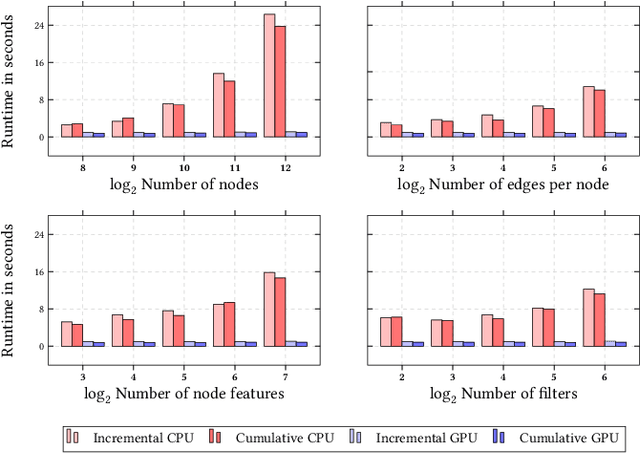
We present PyTorch Geometric Temporal a deep learning framework combining state-of-the-art machine learning algorithms for neural spatiotemporal signal processing. The main goal of the library is to make temporal geometric deep learning available for researchers and machine learning practitioners in a unified easy-to-use framework. PyTorch Geometric Temporal was created with foundations on existing libraries in the PyTorch eco-system, streamlined neural network layer definitions, temporal snapshot generators for batching, and integrated benchmark datasets. These features are illustrated with a tutorial-like case study. Experiments demonstrate the predictive performance of the models implemented in the library on real world problems such as epidemiological forecasting, ridehail demand prediction and web-traffic management. Our sensitivity analysis of runtime shows that the framework can potentially operate on web-scale datasets with rich temporal features and spatial structure.
United We Stand: Transfer Graph Neural Networks for Pandemic Forecasting
Sep 10, 2020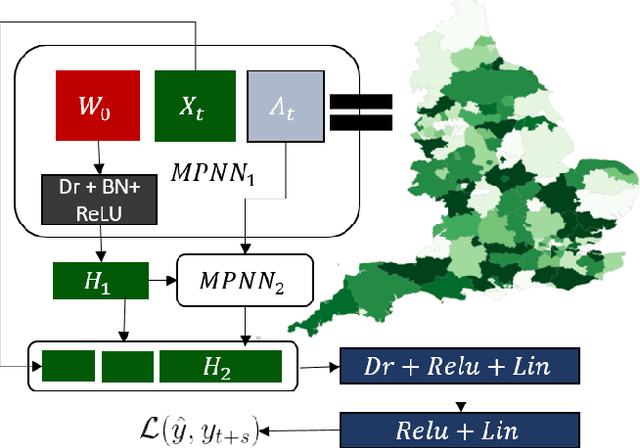

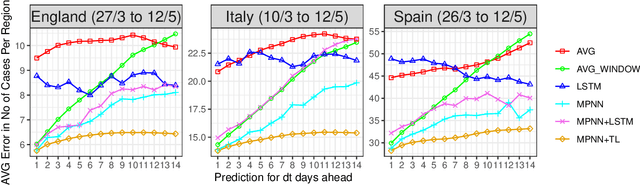
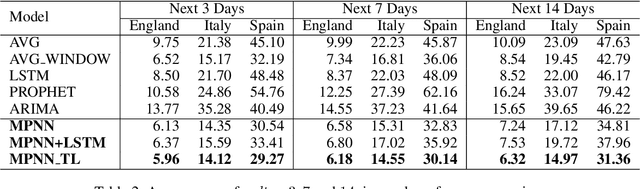
The recent outbreak of COVID-19 has affected millions of individuals around the world and has posed a significant challenge to global healthcare. From the early days of the pandemic, it became clear that it is highly contagious and that human mobility contributes significantly to its spread. In this paper, we study the impact of population movement on the spread of COVID-19, and we capitalize on recent advances in the field of representation learning on graphs to capture the underlying dynamics. Specifically, we create a graph where nodes correspond to a country's regions and the edge weights denote human mobility from one region to another. Then, we employ graph neural networks to predict the number of future cases, encoding the underlying diffusion patterns that govern the spread into our learning model. Furthermore, to account for the limited amount of training data, we capitalize on the pandemic's asynchronous outbreaks across countries and use a model-agnostic meta-learning based method to transfer knowledge from one country's model to another's. We compare the proposed approach against simple baselines and more traditional forecasting techniques in 3 European countries. Experimental results demonstrate the superiority of our method, highlighting the usefulness of GNNs in epidemiological prediction. Transfer learning provides the best model, highlighting its potential to improve the accuracy of the predictions in case of secondary waves, if data from past/parallel outbreaks is utilized.
Performance in the Courtroom: Automated Processing and Visualization of Appeal Court Decisions in France
Jul 09, 2020

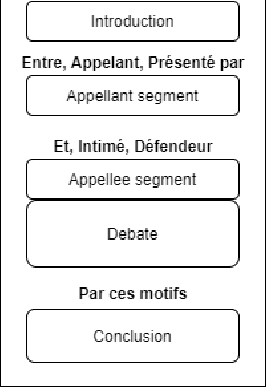
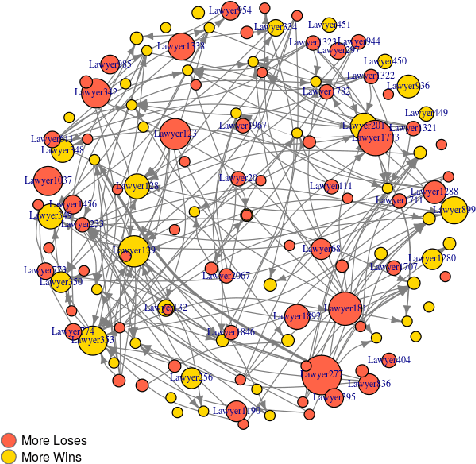
Artificial Intelligence techniques are already popular and important in the legal domain. We extract legal indicators from judicial judgment to decrease the asymmetry of information of the legal system and the access-to-justice gap. We use NLP methods to extract interesting entities/data from judgments to construct networks of lawyers and judgments. We propose metrics to rank lawyers based on their experience, wins/loss ratio and their importance in the network of lawyers. We also perform community detection in the network of judgments and propose metrics to represent the difficulty of cases capitalising on communities features.
Influence Maximization via Representation Learning
Apr 18, 2019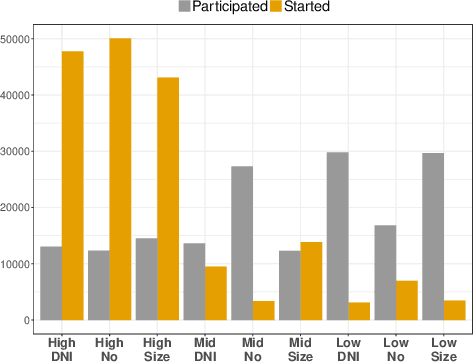
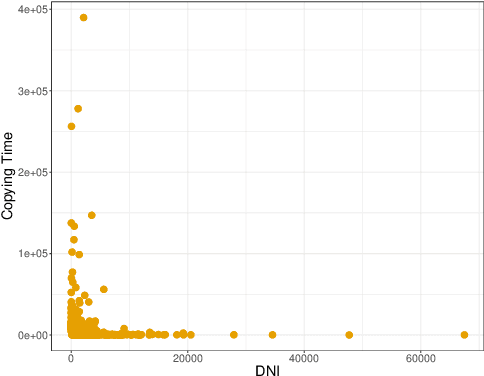

Although influence maximization has been studied extensively in the past, the majority of works focus on the algorithmic aspect of the problem, overlooking several practical improvements that can be derived by data-driven observations or the inclusion of machine learning. The main challenges lie on the one hand on the computational demand of the algorithmic solution which restricts the scalability, and on the other the quality of the predicted influence spread. In this work, we propose IMINFECTOR (Influence Maximization with INFluencer vECTORs), a method that aspires to address both problems using representation learning. It comprises of two parts. The first is based on a multi-task neural network that uses logs of diffusion cascades to embed diffusion probabilities between nodes as well as the ability of a node to create massive cascades. The second part uses diffusion probabilities to reformulate influence maximization as a weighted bipartite matching problem and capitalizes on the learned representations to find a seed set using a greedy heuristic approach. We apply our method in three sizable networks accompanied by diffusion cascades and evaluate it using unseen diffusion cascades from future time steps. We observe that our method outperforms various competitive algorithms and metrics from the diverse landscape of influence maximization, in terms of prediction precision and seed set quality.
A Review of Network Inference Techniques for Neural Activation Time Series
Jun 20, 2018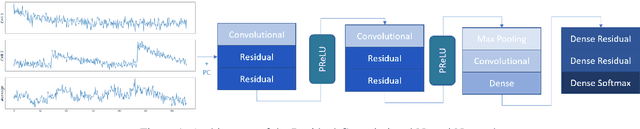
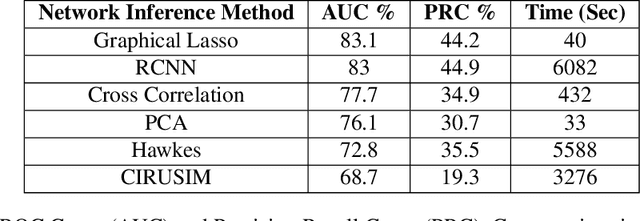

Studying neural connectivity is considered one of the most promising and challenging areas of modern neuroscience. The underpinnings of cognition are hidden in the way neurons interact with each other. However, our experimental methods of studying real neural connections at a microscopic level are still arduous and costly. An efficient alternative is to infer connectivity based on the neuronal activations using computational methods. A reliable method for network inference, would not only facilitate research of neural circuits without the need of laborious experiments but also reveal insights on the underlying mechanisms of the brain. In this work, we perform a review of methods for neural circuit inference given the activation time series of the neural population. Approaching it from machine learning perspective, we divide the methodologies into unsupervised and supervised learning. The methods are based on correlation metrics, probabilistic point processes, and neural networks. Furthermore, we add a data mining methodology inspired by influence estimation in social networks as a new supervised learning approach. For comparison, we use the small version of the Chalearn Connectomics competition, that is accompanied with ground truth connections between neurons. The experiments indicate that unsupervised learning methods perform better, however, supervised methods could surpass them given enough data and resources.