 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI expose tax loopholes? Towards a new generation of legal policy assistants
Mar 21, 2025

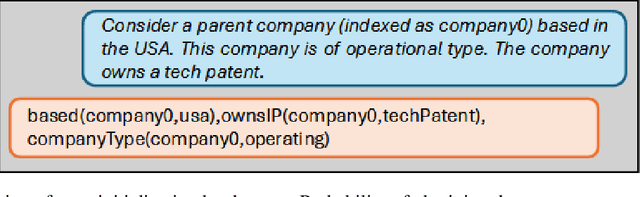

The legislative process is the backbone of a state built on solid institutions. Yet, due to the complexity of laws -- particularly tax law -- policies may lead to inequality and social tensions. In this study, we introduce a novel prototype system designed to address the issues of tax loopholes and tax avoidance. Our hybrid solution integrates a natural language interface with a domain-specific language tailored for planning. We demonstrate on a case study how tax loopholes and avoidance schemes can be exposed. We conclude that our prototype can help enhance social welfare by systematically identifying and addressing tax gaps stemming from loopholes.
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains
Dec 15, 2021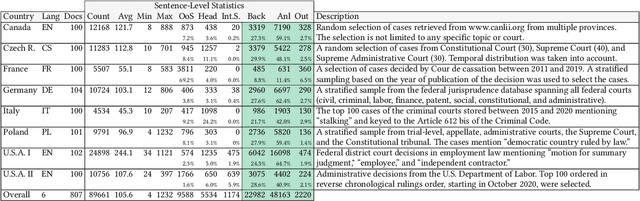
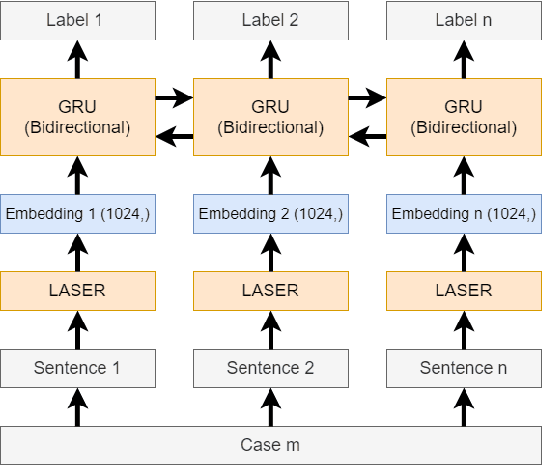
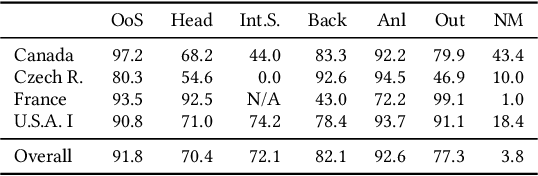
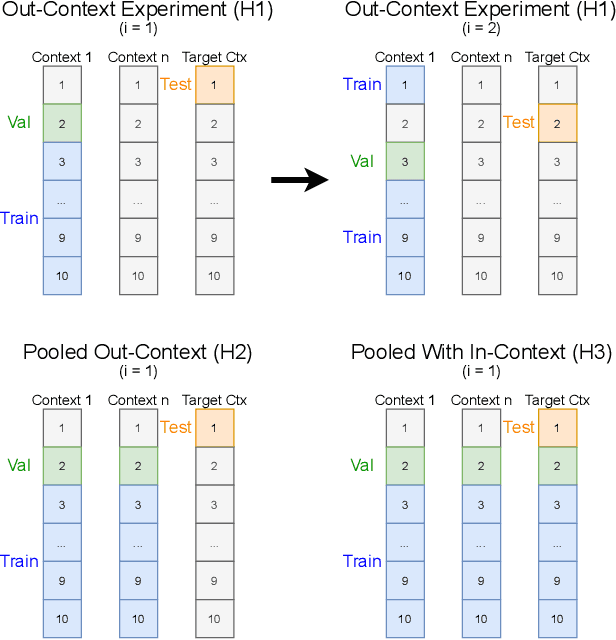
In this paper, we examine the use of multi-lingual sentence embeddings to transfer predictive models for functional segmentation of adjudicatory decisions across jurisdictions, legal systems (common and civil law), languages, and domains (i.e. contexts). Mechanisms for utilizing linguistic resources outside of their original context have significant potential benefits in AI & Law because differences between legal systems, languages, or traditions often block wider adoption of research outcomes. We analyze the use of Language-Agnostic Sentence Representations in sequence labeling models using Gated Recurrent Units (GRUs) that are transferable across languages. To investigate transfer between different contexts we developed an annotation scheme for functional segmentation of adjudicatory decisions. We found that models generalize beyond the contexts on which they were trained (e.g., a model trained on administrative decisions from the US can be applied to criminal law decisions from Italy). Further, we found that training the models on multiple contexts increases robustness and improves overall performance when evaluating on previously unseen contexts. Finally, we found that pooling the training data from all the contexts enhances the models' in-context performance.
* 10 pages
JuriBERT: A Masked-Language Model Adaptation for French Legal Text
Oct 04, 2021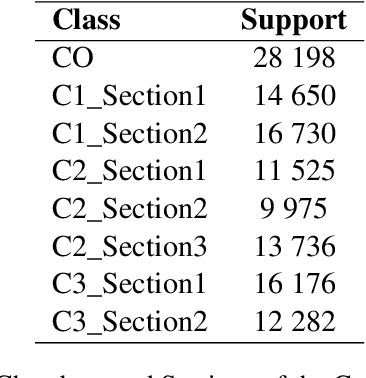
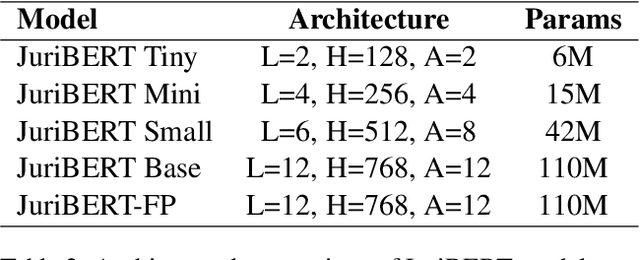
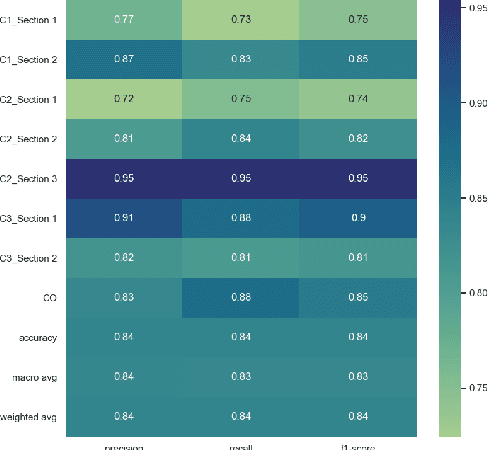
Language models have proven to be very useful when adapted to specific domains. Nonetheless, little research has been done on the adaptation of domain-specific BERT models in the French language. In this paper, we focus on creating a language model adapted to French legal text with the goal of helping law professionals. We conclude that some specific tasks do not benefit from generic language models pre-trained on large amounts of data. We explore the use of smaller architectures in domain-specific sub-languages and their benefits for French legal text. We prove that domain-specific pre-trained models can perform better than their equivalent generalised ones in the legal domain. Finally, we release JuriBERT, a new set of BERT models adapted to the French legal domain.
Compliance Generation for Privacy Documents under GDPR: A Roadmap for Implementing Automation and Machine Learning
Dec 23, 2020Most prominent research today addresses compliance with data protection laws through consumer-centric and public-regulatory approaches. We shift this perspective with the Privatech project to focus on corporations and law firms as agents of compliance. To comply with data protection laws, data processors must implement accountability measures to assess and document compliance in relation to both privacy documents and privacy practices. In this paper, we survey, on the one hand, current research on GDPR automation, and on the other hand, the operational challenges corporations face to comply with GDPR, and that may benefit from new forms of automation. We attempt to bridge the gap. We provide a roadmap for compliance assessment and generation by identifying compliance issues, breaking them down into tasks that can be addressed through machine learning and automation, and providing notes about related developments in the Privatech project.
Performance in the Courtroom: Automated Processing and Visualization of Appeal Court Decisions in France
Jul 09, 2020

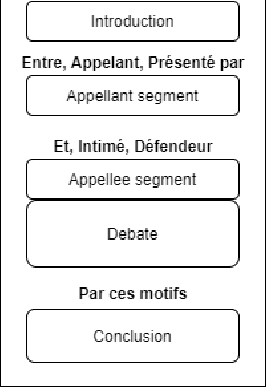
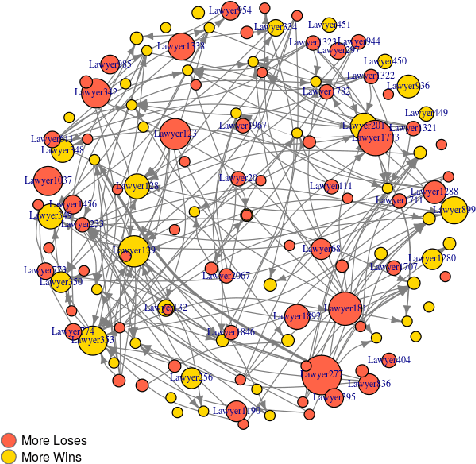
Artificial Intelligence techniques are already popular and important in the legal domain. We extract legal indicators from judicial judgment to decrease the asymmetry of information of the legal system and the access-to-justice gap. We use NLP methods to extract interesting entities/data from judgments to construct networks of lawyers and judgments. We propose metrics to rank lawyers based on their experience, wins/loss ratio and their importance in the network of lawyers. We also perform community detection in the network of judgments and propose metrics to represent the difficulty of cases capitalising on communities features.