 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Create Legally Relevant Summaries and Analyses of Videos?
Nov 15, 2025

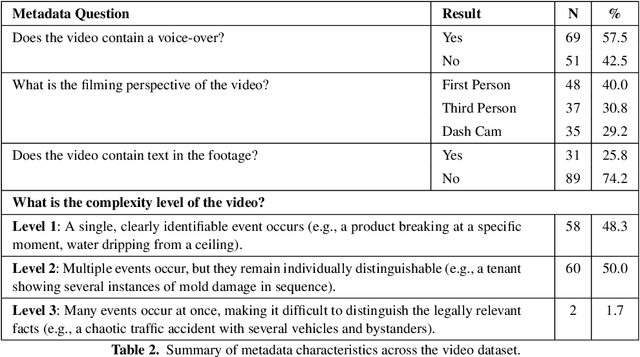
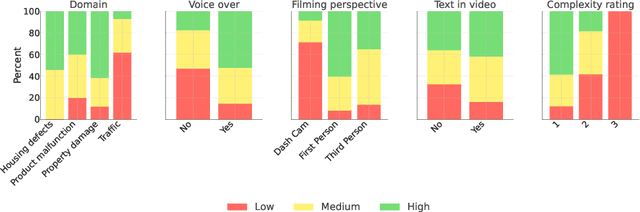
Understanding the legally relevant factual basis of an event and conveying it through text is a key skill of legal professionals. This skill is important for preparing forms (e.g., insurance claims) or other legal documents (e.g., court claims), but often presents a challenge for laypeople. Current AI approaches aim to bridge this gap, but mostly rely on the user to articulate what has happened in text, which may be challenging for many. Here, we investigate the capability of large language models (LLMs) to understand and summarize events occurring in videos. We ask an LLM to summarize and draft legal letters, based on 120 YouTube videos showing legal issues in various domains. Overall, 71.7\% of the summaries were rated as of high or medium quality, which is a promising result, opening the door to a number of applications in e.g. access to justice.
Analyzing Images of Legal Documents: Toward Multi-Modal LLMs for Access to Justice
Dec 16, 2024Interacting with the legal system and the government requires the assembly and analysis of various pieces of information that can be spread across different (paper) documents, such as forms, certificates and contracts (e.g. leases). This information is required in order to understand one's legal rights, as well as to fill out forms to file claims in court or obtain government benefits. However, finding the right information, locating the correct forms and filling them out can be challenging for laypeople. Large language models (LLMs) have emerged as a powerful technology that has the potential to address this gap, but still rely on the user to provide the correct information, which may be challenging and error-prone if the information is only available in complex paper documents. We present an investigation into utilizing multi-modal LLMs to analyze images of handwritten paper forms, in order to automatically extract relevant information in a structured format. Our initial results are promising, but reveal some limitations (e.g., when the image quality is low). Our work demonstrates the potential of integrating multi-modal LLMs to support laypeople and self-represented litigants in finding and assembling relevant information.
Robots in the Middle: Evaluating LLMs in Dispute Resolution
Oct 09, 2024



Mediation is a dispute resolution method featuring a neutral third-party (mediator) who intervenes to help the individuals resolve their dispute. In this paper, we investigate to which extent large language models (LLMs) are able to act as mediators. We investigate whether LLMs are able to analyze dispute conversations, select suitable intervention types, and generate appropriate intervention messages. Using a novel, manually created dataset of 50 dispute scenarios, we conduct a blind evaluation comparing LLMs with human annotators across several key metrics. Overall, the LLMs showed strong performance, even outperforming our human annotators across dimensions. Specifically, in 62% of the cases, the LLMs chose intervention types that were rated as better than or equivalent to those chosen by humans. Moreover, in 84% of the cases, the intervention messages generated by the LLMs were rated as better than or equal to the intervention messages written by humans. LLMs likewise performed favourably on metrics such as impartiality, understanding and contextualization. Our results demonstrate the potential of integrating AI in online dispute resolution (ODR) platforms.
Getting in the Door: Streamlining Intake in Civil Legal Services with Large Language Models
Oct 02, 2024



Legal intake, the process of finding out if an applicant is eligible for help from a free legal aid program, takes significant time and resources. In part this is because eligibility criteria are nuanced, open-textured, and require frequent revision as grants start and end. In this paper, we investigate the use of large language models (LLMs) to reduce this burden. We describe a digital intake platform that combines logical rules with LLMs to offer eligibility recommendations, and we evaluate the ability of 8 different LLMs to perform this task. We find promising results for this approach to help close the access to justice gap, with the best model reaching an F1 score of .82, while minimizing false negatives.
A Path Towards Legal Autonomy: An interoperable and explainable approach to extracting, transforming, loading and computing legal information using large language models, expert systems and Bayesian networks
Mar 27, 2024Legal autonomy - the lawful activity of artificial intelligence agents - can be achieved in one of two ways. It can be achieved either by imposing constraints on AI actors such as developers, deployers and users, and on AI resources such as data, or by imposing constraints on the range and scope of the impact that AI agents can have on the environment. The latter approach involves encoding extant rules concerning AI driven devices into the software of AI agents controlling those devices (e.g., encoding rules about limitations on zones of operations into the agent software of an autonomous drone device). This is a challenge since the effectivity of such an approach requires a method of extracting, loading, transforming and computing legal information that would be both explainable and legally interoperable, and that would enable AI agents to reason about the law. In this paper, we sketch a proof of principle for such a method using large language models (LLMs), expert legal systems known as legal decision paths, and Bayesian networks. We then show how the proposed method could be applied to extant regulation in matters of autonomous cars, such as the California Vehicle Code.
From Text to Structure: Using Large Language Models to Support the Development of Legal Expert Systems
Nov 01, 2023



Encoding legislative text in a formal representation is an important prerequisite to different tasks in the field of AI & Law. For example, rule-based expert systems focused on legislation can support laypeople in understanding how legislation applies to them and provide them with helpful context and information. However, the process of analyzing legislation and other sources to encode it in the desired formal representation can be time-consuming and represents a bottleneck in the development of such systems. Here, we investigate to what degree large language models (LLMs), such as GPT-4, are able to automatically extract structured representations from legislation. We use LLMs to create pathways from legislation, according to the JusticeBot methodology for legal decision support systems, evaluate the pathways and compare them to manually created pathways. The results are promising, with 60% of generated pathways being rated as equivalent or better than manually created ones in a blind comparison. The approach suggests a promising path to leverage the capabilities of LLMs to ease the costly development of systems based on symbolic approaches that are transparent and explainable.
Using Large Language Models to Support Thematic Analysis in Empirical Legal Studies
Oct 28, 2023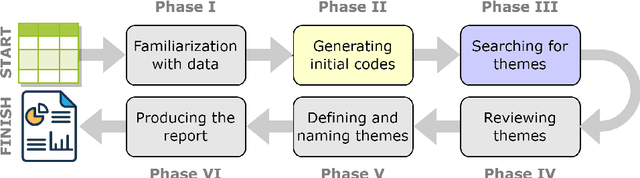

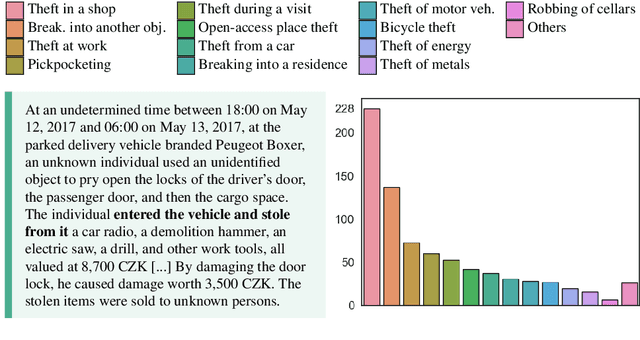

Thematic analysis and other variants of inductive coding are widely used qualitative analytic methods within empirical legal studies (ELS). We propose a novel framework facilitating effective collaboration of a legal expert with a large language model (LLM) for generating initial codes (phase 2 of thematic analysis), searching for themes (phase 3), and classifying the data in terms of the themes (to kick-start phase 4). We employed the framework for an analysis of a dataset (n=785) of facts descriptions from criminal court opinions regarding thefts. The goal of the analysis was to discover classes of typical thefts. Our results show that the LLM, namely OpenAI's GPT-4, generated reasonable initial codes, and it was capable of improving the quality of the codes based on expert feedback. They also suggest that the model performed well in zero-shot classification of facts descriptions in terms of the themes. Finally, the themes autonomously discovered by the LLM appear to map fairly well to the themes arrived at by legal experts. These findings can be leveraged by legal researchers to guide their decisions in integrating LLMs into their thematic analyses, as well as other inductive coding projects.
* 10 pages, 5 figures, 3 tables
JusticeBot: A Methodology for Building Augmented Intelligence Tools for Laypeople to Increase Access to Justice
Jul 27, 2023



Laypeople (i.e. individuals without legal training) may often have trouble resolving their legal problems. In this work, we present the JusticeBot methodology. This methodology can be used to build legal decision support tools, that support laypeople in exploring their legal rights in certain situations, using a hybrid case-based and rule-based reasoning approach. The system ask the user questions regarding their situation and provides them with legal information, references to previous similar cases and possible next steps. This information could potentially help the user resolve their issue, e.g. by settling their case or enforcing their rights in court. We present the methodology for building such tools, which consists of discovering typically applied legal rules from legislation and case law, and encoding previous cases to support the user. We also present an interface to build tools using this methodology and a case study of the first deployed JusticeBot version, focused on landlord-tenant disputes, which has been used by thousands of individuals.
LLMediator: GPT-4 Assisted Online Dispute Resolution
Jul 27, 2023



In this article, we introduce LLMediator, an experimental platform designed to enhance online dispute resolution (ODR) by utilizing capabilities of state-of-the-art large language models (LLMs) such as GPT-4. In the context of high-volume, low-intensity legal disputes, alternative dispute resolution methods such as negotiation and mediation offer accessible and cooperative solutions for laypeople. These approaches can be carried out online on ODR platforms. LLMediator aims to improve the efficacy of such processes by leveraging GPT-4 to reformulate user messages, draft mediator responses, and potentially autonomously engage in the discussions. We present and discuss several features of LLMediator and conduct initial qualitative evaluations, demonstrating the potential for LLMs to support ODR and facilitate amicable settlements. The initial proof of concept is promising and opens up avenues for further research in AI-assisted negotiation and mediation.
Can GPT-4 Support Analysis of Textual Data in Tasks Requiring Highly Specialized Domain Expertise?
Jun 24, 2023



We evaluated the capability of generative pre-trained transformers~(GPT-4) in analysis of textual data in tasks that require highly specialized domain expertise. Specifically, we focused on the task of analyzing court opinions to interpret legal concepts. We found that GPT-4, prompted with annotation guidelines, performs on par with well-trained law student annotators. We observed that, with a relatively minor decrease in performance, GPT-4 can perform batch predictions leading to significant cost reductions. However, employing chain-of-thought prompting did not lead to noticeably improved performance on this task. Further, we demonstrated how to analyze GPT-4's predictions to identify and mitigate deficiencies in annotation guidelines, and subsequently improve the performance of the model. Finally, we observed that the model is quite brittle, as small formatting related changes in the prompt had a high impact on the predictions. These findings can be leveraged by researchers and practitioners who engage in semantic/pragmatic annotations of texts in the context of the tasks requiring highly specialized domain expertise.