 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Create Legally Relevant Summaries and Analyses of Videos?
Nov 15, 2025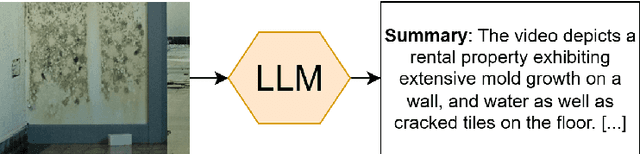

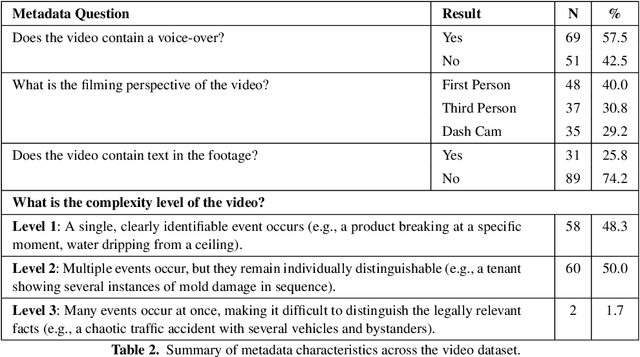
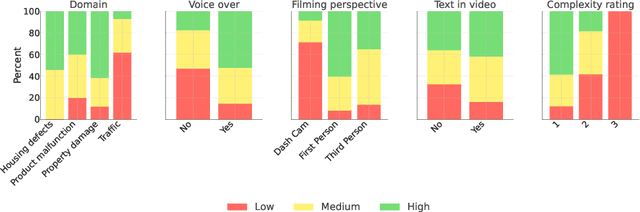
Understanding the legally relevant factual basis of an event and conveying it through text is a key skill of legal professionals. This skill is important for preparing forms (e.g., insurance claims) or other legal documents (e.g., court claims), but often presents a challenge for laypeople. Current AI approaches aim to bridge this gap, but mostly rely on the user to articulate what has happened in text, which may be challenging for many. Here, we investigate the capability of large language models (LLMs) to understand and summarize events occurring in videos. We ask an LLM to summarize and draft legal letters, based on 120 YouTube videos showing legal issues in various domains. Overall, 71.7\% of the summaries were rated as of high or medium quality, which is a promising result, opening the door to a number of applications in e.g. access to justice.
"I Like That You Have to Poke Around": Instructors on How Experiential Approaches to AI Literacy Spark Inquiry and Critical Thinking
Nov 07, 2025As artificial intelligence (AI) increasingly shapes decision-making across domains, there is a growing need to support AI literacy among learners beyond computer science. However, many current approaches rely on programming-heavy tools or abstract lecture-based content, limiting accessibility for non-STEM audiences. This paper presents findings from a study of AI User, a modular, web-based curriculum that teaches core AI concepts through interactive, no-code projects grounded in real-world scenarios. The curriculum includes eight projects; this study focuses on instructor feedback on Projects 5-8, which address applied topics such as natural language processing, computer vision, decision support, and responsible AI. Fifteen community college instructors participated in structured focus groups, completing the projects as learners and providing feedback through individual reflection and group discussion. Using thematic analysis, we examined how instructors evaluated the design, instructional value, and classroom applicability of these experiential activities. Findings highlight instructors' appreciation for exploratory tasks, role-based simulations, and real-world relevance, while also surfacing design trade-offs around cognitive load, guidance, and adaptability for diverse learners. This work extends prior research on AI literacy by centering instructor perspectives on teaching complex AI topics without code. It offers actionable insights for designing inclusive, experiential AI learning resources that scale across disciplines and learner backgrounds.
What Are the Facts? Automated Extraction of Court-Established Facts from Criminal-Court Opinions
Nov 07, 2025

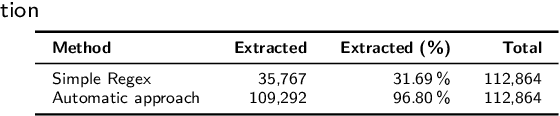
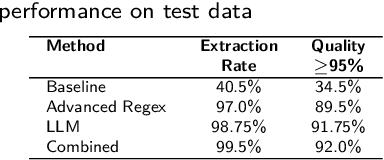
Criminal justice administrative data contain only a limited amount of information about the committed offense. However, there is an unused source of extensive information in continental European courts' decisions: descriptions of criminal behaviors in verdicts by which offenders are found guilty. In this paper, we study the feasibility of extracting these descriptions from publicly available court decisions from Slovakia. We use two different approaches for retrieval: regular expressions and large language models (LLMs). Our baseline was a simple method employing regular expressions to identify typical words occurring before and after the description. The advanced regular expression approach further focused on "sparing" and its normalization (insertion of spaces between individual letters), typical for delineating the description. The LLM approach involved prompting the Gemini Flash 2.0 model to extract the descriptions using predefined instructions. Although the baseline identified descriptions in only 40.5% of verdicts, both methods significantly outperformed it, achieving 97% with advanced regular expressions and 98.75% with LLMs, and 99.5% when combined. Evaluation by law students showed that both advanced methods matched human annotations in about 90% of cases, compared to just 34.5% for the baseline. LLMs fully matched human-labeled descriptions in 91.75% of instances, and a combination of advanced regular expressions with LLMs reached 92%.
AI Literacy Assessment Revisited: A Task-Oriented Approach Aligned with Real-world Occupations
Nov 07, 2025As artificial intelligence (AI) systems become ubiquitous in professional contexts, there is an urgent need to equip workers, often with backgrounds outside of STEM, with the skills to use these tools effectively as well as responsibly, that is, to be AI literate. However, prevailing definitions and therefore assessments of AI literacy often emphasize foundational technical knowledge, such as programming, mathematics, and statistics, over practical knowledge such as interpreting model outputs, selecting tools, or identifying ethical concerns. This leaves a noticeable gap in assessing someone's AI literacy for real-world job use. We propose a work-task-oriented assessment model for AI literacy which is grounded in the competencies required for effective use of AI tools in professional settings. We describe the development of a novel AI literacy assessment instrument, and accompanying formative assessments, in the context of a US Navy robotics training program. The program included training in robotics and AI literacy, as well as a competition with practical tasks and a multiple choice scenario task meant to simulate use of AI in a job setting. We found that, as a measure of applied AI literacy, the competition's scenario task outperformed the tests we adopted from past research or developed ourselves. We argue that when training people for AI-related work, educators should consider evaluating them with instruments that emphasize highly contextualized practical skills rather than abstract technical knowledge, especially when preparing workers without technical backgrounds for AI-integrated roles.
AI Literacy for Community Colleges: Instructors' Perspectives on Scenario-Based and Interactive Approaches to Teaching AI
Nov 07, 2025


This research category full paper investigates how community college instructors evaluate interactive, no-code AI literacy resources designed for non-STEM learners. As artificial intelligence becomes increasingly integrated into everyday technologies, AI literacy - the ability to evaluate AI systems, communicate with them, and understand their broader impacts - has emerged as a critical skill across disciplines. Yet effective, scalable approaches for teaching these concepts in higher education remain limited, particularly for students outside STEM fields. To address this gap, we developed AI User, an interactive online curriculum that introduces core AI concepts through scenario - based activities set in real - world contexts. This study presents findings from four focus groups with instructors who engaged with AI User materials and participated in structured feedback activities. Thematic analysis revealed that instructors valued exploratory tasks that simulated real - world AI use cases and fostered experimentation, while also identifying challenges related to scaffolding, accessibility, and multi-modal support. A ranking task for instructional support materials showed a strong preference for interactive demonstrations over traditional educational materials like conceptual guides or lecture slides. These findings offer insights into instructor perspectives on making AI concepts more accessible and relevant for broad learner audiences. They also inform the design of AI literacy tools that align with diverse teaching contexts and support critical engagement with AI in higher education.
AI Technicians: Developing Rapid Occupational Training Methods for a Competitive AI Workforce
Jan 17, 2025



The accelerating pace of developments in Artificial Intelligence~(AI) and the increasing role that technology plays in society necessitates substantial changes in the structure of the workforce. Besides scientists and engineers, there is a need for a very large workforce of competent AI technicians (i.e., maintainers, integrators) and users~(i.e., operators). As traditional 4-year and 2-year degree-based education cannot fill this quickly opening gap, alternative training methods have to be developed. We present the results of the first four years of the AI Technicians program which is a unique collaboration between the U.S. Army's Artificial Intelligence Integration Center (AI2C) and Carnegie Mellon University to design, implement and evaluate novel rapid occupational training methods to create a competitive AI workforce at the technicians level. Through this multi-year effort we have already trained 59 AI Technicians. A key observation is that ongoing frequent updates to the training are necessary as the adoption of AI in the U.S. Army and within the society at large is evolving rapidly. A tight collaboration among the stakeholders from the army and the university is essential for successful development and maintenance of the training for the evolving role. Our findings can be leveraged by large organizations that face the challenge of developing a competent AI workforce as well as educators and researchers engaged in solving the challenge.
Beyond the Hype: A Comprehensive Review of Current Trends in Generative AI Research, Teaching Practices, and Tools
Dec 19, 2024



Generative AI (GenAI) is advancing rapidly, and the literature in computing education is expanding almost as quickly. Initial responses to GenAI tools were mixed between panic and utopian optimism. Many were fast to point out the opportunities and challenges of GenAI. Researchers reported that these new tools are capable of solving most introductory programming tasks and are causing disruptions throughout the curriculum. These tools can write and explain code, enhance error messages, create resources for instructors, and even provide feedback and help for students like a traditional teaching assistant. In 2024, new research started to emerge on the effects of GenAI usage in the computing classroom. These new data involve the use of GenAI to support classroom instruction at scale and to teach students how to code with GenAI. In support of the former, a new class of tools is emerging that can provide personalized feedback to students on their programming assignments or teach both programming and prompting skills at the same time. With the literature expanding so rapidly, this report aims to summarize and explain what is happening on the ground in computing classrooms. We provide a systematic literature review; a survey of educators and industry professionals; and interviews with educators using GenAI in their courses, educators studying GenAI, and researchers who create GenAI tools to support computing education. The triangulation of these methods and data sources expands the understanding of GenAI usage and perceptions at this critical moment for our community.
Analyzing Images of Legal Documents: Toward Multi-Modal LLMs for Access to Justice
Dec 16, 2024Interacting with the legal system and the government requires the assembly and analysis of various pieces of information that can be spread across different (paper) documents, such as forms, certificates and contracts (e.g. leases). This information is required in order to understand one's legal rights, as well as to fill out forms to file claims in court or obtain government benefits. However, finding the right information, locating the correct forms and filling them out can be challenging for laypeople. Large language models (LLMs) have emerged as a powerful technology that has the potential to address this gap, but still rely on the user to provide the correct information, which may be challenging and error-prone if the information is only available in complex paper documents. We present an investigation into utilizing multi-modal LLMs to analyze images of handwritten paper forms, in order to automatically extract relevant information in a structured format. Our initial results are promising, but reveal some limitations (e.g., when the image quality is low). Our work demonstrates the potential of integrating multi-modal LLMs to support laypeople and self-represented litigants in finding and assembling relevant information.
Using LLMs to Discover Legal Factors
Oct 10, 2024



Factors are a foundational component of legal analysis and computational models of legal reasoning. These factor-based representations enable lawyers, judges, and AI and Law researchers to reason about legal cases. In this paper, we introduce a methodology that leverages large language models (LLMs) to discover lists of factors that effectively represent a legal domain. Our method takes as input raw court opinions and produces a set of factors and associated definitions. We demonstrate that a semi-automated approach, incorporating minimal human involvement, produces factor representations that can predict case outcomes with moderate success, if not yet as well as expert-defined factors can.
It Cannot Be Right If It Was Written by AI: On Lawyers' Preferences of Documents Perceived as Authored by an LLM vs a Human
Jul 09, 2024
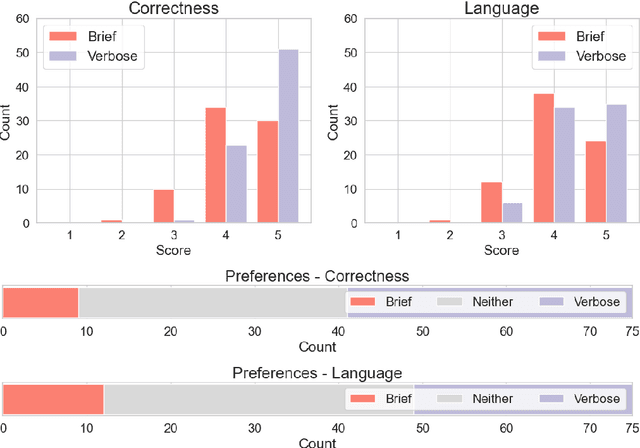
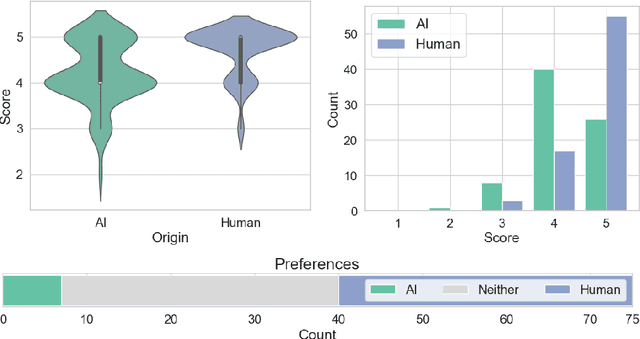
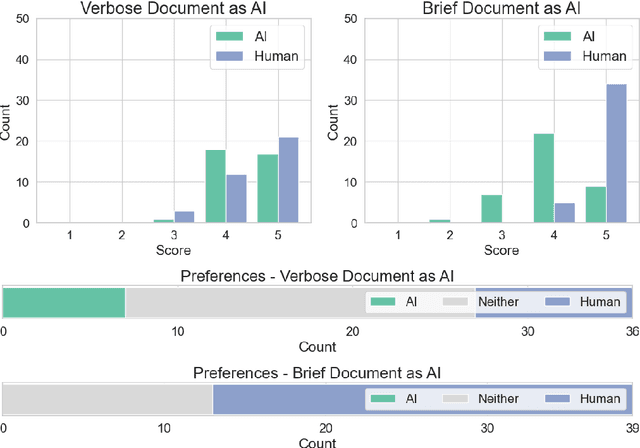
Large Language Models (LLMs) enable a future in which certain types of legal documents may be generated automatically. This has a great potential to streamline legal processes, lower the cost of legal services, and dramatically increase access to justice. While many researchers focus their efforts on proposing and evaluating LLM-based applications supporting tasks in the legal domain, there is a notable lack of investigations into how legal professionals perceive content if they believe it has been generated by an LLM. Yet, this is a critical point as over-reliance or unfounded skepticism may influence whether such documents bring about appropriate legal consequences. This study is the necessary analysis in the context of the ongoing transition towards mature generative AI systems. Specifically, we examined whether the perception of legal documents' by lawyers (n=75) varies based on their assumed origin (human-crafted vs AI-generated). The participants evaluated the documents focusing on their correctness and language quality. Our analysis revealed a clear preference for documents perceived as crafted by a human over those believed to be generated by AI. At the same time, most of the participants are expecting the future in which documents will be generated automatically. These findings could be leveraged by legal practitioners, policy makers and legislators to implement and adopt legal document generation technology responsibly, and to fuel the necessary discussions into how legal processes should be updated to reflect the recent technological developments.