 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLearner-LLM: Balancing Logical Grounding and Fluency in Large Language Models via Hybrid Direct Preference Optimization
May 06, 2026Direct Preference Optimization (DPO), the efficient alternative to PPO-based RLHF, falls short on knowledge-intensive generation: standard preference signals from human annotators or LLM judges exhibit a systematic verbosity bias that rewards fluency over logical correctness. This blindspot leaves a logical alignment gap -- SFT models reach NLI entailment of only 0.05-0.22 despite producing fluent text. We propose RLearner-LLM with Hybrid-DPO: an automated preference pipeline that fuses a DeBERTa-v3 NLI signal with a verifier LLM score, removing human annotation while overcoming the "alignment tax" of single-signal optimization. Evaluated across five academic domains (Biology, Medicine, Law) with three base architectures (LLaMA-2-13B, Qwen3-8B, Gemma 4 E4B-it), RLearner-LLM yields up to 6x NLI improvement over SFT, with NLI gains in 11 of 15 cells and consistent answer-coverage gains. On Gemma 4 E4B-it (4.5B effective params), Hybrid-DPO lifts NLI in four of five domains (+11.9% to +2.4x) with faster inference across all five, scaling down to compact base models without losing the alignment-tax mitigation. Our Qwen3-8B RLearner-LLM wins 95% of pairwise comparisons against its own SFT baseline; GPT-4o-mini in turn wins 95% against our concise output -- alongside the 69% win the same judge gives a verbose SFT over our DPO model, this replicates verbosity bias on a frontier comparator and motivates logic-aware metrics (NLI, ACR) over LLM-as-a-judge for knowledge-intensive generation.
EduRABSA: An Education Review Dataset for Aspect-based Sentiment Analysis Tasks
Aug 23, 2025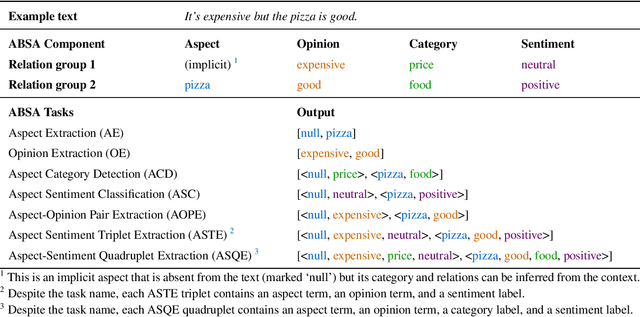
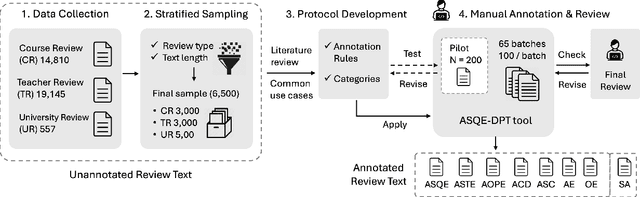
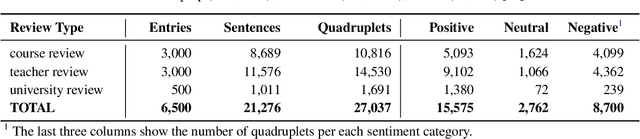
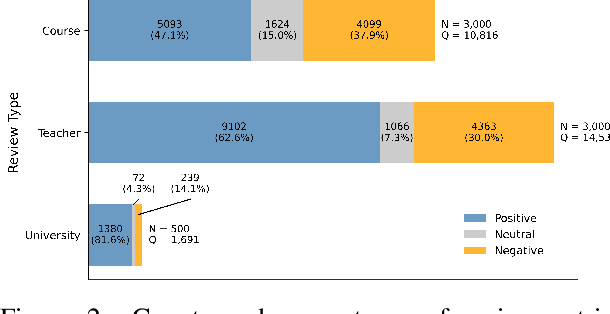
Every year, most educational institutions seek and receive an enormous volume of text feedback from students on courses, teaching, and overall experience. Yet, turning this raw feedback into useful insights is far from straightforward. It has been a long-standing challenge to adopt automatic opinion mining solutions for such education review text data due to the content complexity and low-granularity reporting requirements. Aspect-based Sentiment Analysis (ABSA) offers a promising solution with its rich, sub-sentence-level opinion mining capabilities. However, existing ABSA research and resources are very heavily focused on the commercial domain. In education, they are scarce and hard to develop due to limited public datasets and strict data protection. A high-quality, annotated dataset is urgently needed to advance research in this under-resourced area. In this work, we present EduRABSA (Education Review ABSA), the first public, annotated ABSA education review dataset that covers three review subject types (course, teaching staff, university) in the English language and all main ABSA tasks, including the under-explored implicit aspect and implicit opinion extraction. We also share ASQE-DPT (Data Processing Tool), an offline, lightweight, installation-free manual data annotation tool that generates labelled datasets for comprehensive ABSA tasks from a single-task annotation. Together, these resources contribute to the ABSA community and education domain by removing the dataset barrier, supporting research transparency and reproducibility, and enabling the creation and sharing of further resources. The dataset, annotation tool, and scripts and statistics for dataset processing and sampling are available at https://github.com/yhua219/edurabsa_dataset_and_annotation_tool.
From Prompts to Propositions: A Logic-Based Lens on Student-LLM Interactions
Apr 25, 2025Background and Context. The increasing integration of large language models (LLMs) in computing education presents an emerging challenge in understanding how students use LLMs and craft prompts to solve computational tasks. Prior research has used both qualitative and quantitative methods to analyze prompting behavior, but these approaches lack scalability or fail to effectively capture the semantic evolution of prompts. Objective. In this paper, we investigate whether students prompts can be systematically analyzed using propositional logic constraints. We examine whether this approach can identify patterns in prompt evolution, detect struggling students, and provide insights into effective and ineffective strategies. Method. We introduce Prompt2Constraints, a novel method that translates students prompts into logical constraints. The constraints are able to represent the intent of the prompts in succinct and quantifiable ways. We used this approach to analyze a dataset of 1,872 prompts from 203 students solving introductory programming tasks. Findings. We find that while successful and unsuccessful attempts tend to use a similar number of constraints overall, when students fail, they often modify their prompts more significantly, shifting problem-solving strategies midway. We also identify points where specific interventions could be most helpful to students for refining their prompts. Implications. This work offers a new and scalable way to detect students who struggle in solving natural language programming tasks. This work could be extended to investigate more complex tasks and integrated into programming tools to provide real-time support.
Prompt Programming: A Platform for Dialogue-based Computational Problem Solving with Generative AI Models
Mar 06, 2025



Computing students increasingly rely on generative AI tools for programming assistance, often without formal instruction or guidance. This highlights a need to teach students how to effectively interact with AI models, particularly through natural language prompts, to generate and critically evaluate code for solving computational tasks. To address this, we developed a novel platform for prompt programming that enables authentic dialogue-based interactions, supports problems involving multiple interdependent functions, and offers on-request execution of generated code. Data analysis from over 900 students in an introductory programming course revealed high engagement, with the majority of prompts occurring within multi-turn dialogues. Problems with multiple interdependent functions encouraged iterative refinement, with progression graphs highlighting several common strategies. Students were highly selective about the code they chose to test, suggesting that on-request execution of generated code promoted critical thinking. Given the growing importance of learning dialogue-based programming with AI, we provide this tool as a publicly accessible resource, accompanied by a corpus of programming problems for educational use.
Breaking the Programming Language Barrier: Multilingual Prompting to Empower Non-Native English Learners
Dec 17, 2024


Non-native English speakers (NNES) face multiple barriers to learning programming. These barriers can be obvious, such as the fact that programming language syntax and instruction are often in English, or more subtle, such as being afraid to ask for help in a classroom full of native English speakers. However, these barriers are frustrating because many NNES students know more about programming than they can articulate in English. Advances in generative AI (GenAI) have the potential to break down these barriers because state of the art models can support interactions in multiple languages. Moreover, recent work has shown that GenAI can be highly accurate at code generation and explanation. In this paper, we provide the first exploration of NNES students prompting in their native languages (Arabic, Chinese, and Portuguese) to generate code to solve programming problems. Our results show that students are able to successfully use their native language to solve programming problems, but not without some difficulty specifying programming terminology and concepts. We discuss the challenges they faced, the implications for practice in the short term, and how this might transform computing education globally in the long term.
Seeing the Forest and the Trees: Solving Visual Graph and Tree Based Data Structure Problems using Large Multimodal Models
Dec 15, 2024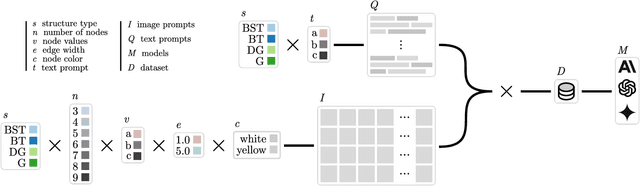

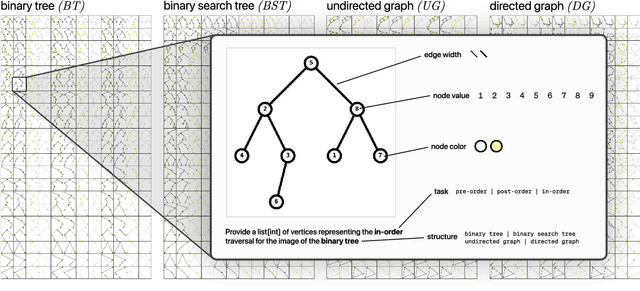

Recent advancements in generative AI systems have raised concerns about academic integrity among educators. Beyond excelling at solving programming problems and text-based multiple-choice questions, recent research has also found that large multimodal models (LMMs) can solve Parsons problems based only on an image. However, such problems are still inherently text-based and rely on the capabilities of the models to convert the images of code blocks to their corresponding text. In this paper, we further investigate the capabilities of LMMs to solve graph and tree data structure problems based only on images. To achieve this, we computationally construct and evaluate a novel benchmark dataset comprising 9,072 samples of diverse graph and tree data structure tasks to assess the performance of the GPT-4o, GPT-4v, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.0 Pro Vision, and Claude 3 model families. GPT-4o and Gemini 1.5 Flash performed best on trees and graphs respectively. GPT-4o achieved 87.6% accuracy on tree samples, while Gemini 1.5 Flash, achieved 56.2% accuracy on graph samples. Our findings highlight the influence of structural and visual variations on model performance. This research not only introduces an LMM benchmark to facilitate replication and further exploration but also underscores the potential of LMMs in solving complex computing problems, with important implications for pedagogy and assessment practices.
BugSpotter: Automated Generation of Code Debugging Exercises
Nov 25, 2024
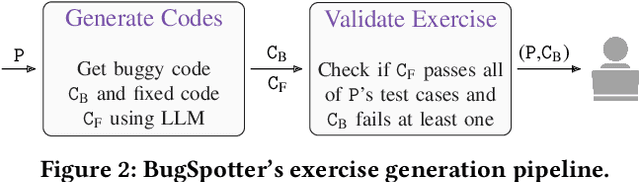

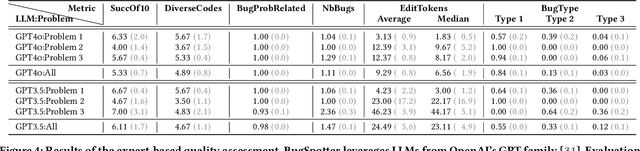
Debugging is an essential skill when learning to program, yet its instruction and emphasis often vary widely across introductory courses. In the era of code-generating large language models (LLMs), the ability for students to reason about code and identify errors is increasingly important. However, students frequently resort to trial-and-error methods to resolve bugs without fully understanding the underlying issues. Developing the ability to identify and hypothesize the cause of bugs is crucial but can be time-consuming to teach effectively through traditional means. This paper introduces BugSpotter, an innovative tool that leverages an LLM to generate buggy code from a problem description and verify the synthesized bugs via a test suite. Students interact with BugSpotter by designing failing test cases, where the buggy code's output differs from the expected result as defined by the problem specification. This not only provides opportunities for students to enhance their debugging skills, but also to practice reading and understanding problem specifications. We deployed BugSpotter in a large classroom setting and compared the debugging exercises it generated to exercises hand-crafted by an instructor for the same problems. We found that the LLM-generated exercises produced by BugSpotter varied in difficulty and were well-matched to the problem specifications. Importantly, the LLM-generated exercises were comparable to those manually created by instructors with respect to student performance, suggesting that BugSpotter could be an effective and efficient aid for learning debugging.
Automated Generation of Code Debugging Exercises
Nov 21, 2024Debugging is an essential skill when learning to program, yet its instruction and emphasis often vary widely across introductory courses. In the era of code-generating large language models (LLMs), the ability for students to reason about code and identify errors is increasingly important. However, students frequently resort to trial-and-error methods to resolve bugs without fully understanding the underlying issues. Developing the ability to identify and hypothesize the cause of bugs is crucial but can be time-consuming to teach effectively through traditional means. This paper introduces BugSpotter, an innovative tool that leverages an LLM to generate buggy code from a problem description and verify the synthesized bugs via a test suite. Students interact with BugSpotter by designing failing test cases, where the buggy code's output differs from the expected result as defined by the problem specification. This not only provides opportunities for students to enhance their debugging skills, but also to practice reading and understanding problem specifications. We deployed BugSpotter in a large classroom setting and compared the debugging exercises it generated to exercises hand-crafted by an instructor for the same problems. We found that the LLM-generated exercises produced by BugSpotter varied in difficulty and were well-matched to the problem specifications. Importantly, the LLM-generated exercises were comparable to those manually created by instructors with respect to student performance, suggesting that BugSpotter could be an effective and efficient aid for learning debugging.
Automating Autograding: Large Language Models as Test Suite Generators for Introductory Programming
Nov 14, 2024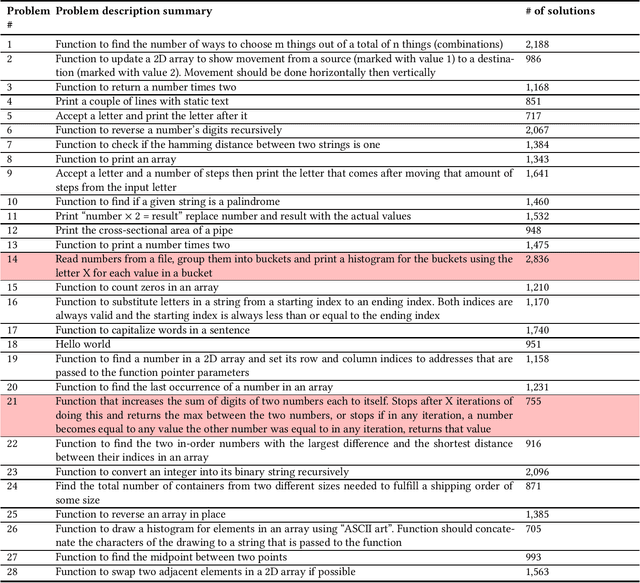



Automatically graded programming assignments provide instant feedback to students and significantly reduce manual grading time for instructors. However, creating comprehensive suites of test cases for programming problems within automatic graders can be time-consuming and complex. The effort needed to define test suites may deter some instructors from creating additional problems or lead to inadequate test coverage, potentially resulting in misleading feedback on student solutions. Such limitations may reduce student access to the well-documented benefits of timely feedback when learning programming. In this work, we evaluate the effectiveness of using Large Language Models (LLMs), as part of a larger workflow, to automatically generate test suites for CS1-level programming problems. Each problem's statement and reference solution are provided to GPT-4 to produce a test suite that can be used by an autograder. We evaluate our proposed approach using a sample of 26 problems, and more than 25,000 attempted solutions to those problems, submitted by students in an introductory programming course. We compare the performance of the LLM-generated test suites against the instructor-created test suites for each problem. Our findings reveal that LLM-generated test suites can correctly identify most valid solutions, and for most problems are at least as comprehensive as the instructor test suites. Additionally, the LLM-generated test suites exposed ambiguities in some problem statements, underscoring their potential to improve both autograding and instructional design.
An Eye for an AI: Evaluating GPT-4o's Visual Perception Skills and Geometric Reasoning Skills Using Computer Graphics Questions
Oct 22, 2024CG (Computer Graphics) is a popular field of CS (Computer Science), but many students find this topic difficult due to it requiring a large number of skills, such as mathematics, programming, geometric reasoning, and creativity. Over the past few years, researchers have investigated ways to harness the power of GenAI (Generative Artificial Intelligence) to improve teaching. In CS, much of the research has focused on introductory computing. A recent study evaluating the performance of an LLM (Large Language Model), GPT-4 (text-only), on CG questions, indicated poor performance and reliance on detailed descriptions of image content, which often required considerable insight from the user to return reasonable results. So far, no studies have investigated the abilities of LMMs (Large Multimodal Models), or multimodal LLMs, to solve CG questions and how these abilities can be used to improve teaching. In this study, we construct two datasets of CG questions requiring varying degrees of visual perception skills and geometric reasoning skills, and evaluate the current state-of-the-art LMM, GPT-4o, on the two datasets. We find that although GPT-4o exhibits great potential in solving questions with visual information independently, major limitations still exist to the accuracy and quality of the generated results. We propose several novel approaches for CG educators to incorporate GenAI into CG teaching despite these limitations. We hope that our guidelines further encourage learning and engagement in CG classrooms.