 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Forest and the Trees: Solving Visual Graph and Tree Based Data Structure Problems using Large Multimodal Models
Dec 15, 2024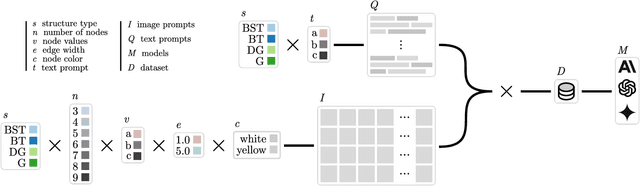

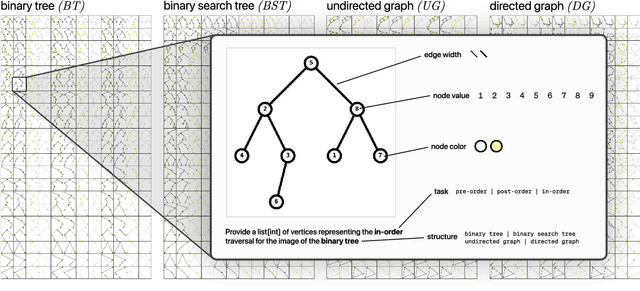

Recent advancements in generative AI systems have raised concerns about academic integrity among educators. Beyond excelling at solving programming problems and text-based multiple-choice questions, recent research has also found that large multimodal models (LMMs) can solve Parsons problems based only on an image. However, such problems are still inherently text-based and rely on the capabilities of the models to convert the images of code blocks to their corresponding text. In this paper, we further investigate the capabilities of LMMs to solve graph and tree data structure problems based only on images. To achieve this, we computationally construct and evaluate a novel benchmark dataset comprising 9,072 samples of diverse graph and tree data structure tasks to assess the performance of the GPT-4o, GPT-4v, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.0 Pro Vision, and Claude 3 model families. GPT-4o and Gemini 1.5 Flash performed best on trees and graphs respectively. GPT-4o achieved 87.6% accuracy on tree samples, while Gemini 1.5 Flash, achieved 56.2% accuracy on graph samples. Our findings highlight the influence of structural and visual variations on model performance. This research not only introduces an LMM benchmark to facilitate replication and further exploration but also underscores the potential of LMMs in solving complex computing problems, with important implications for pedagogy and assessment practices.
More Robots are Coming: Large Multimodal Models (ChatGPT) can Solve Visually Diverse Images of Parsons Problems
Nov 03, 2023



The advent of large language models is reshaping computing education. Recent research has demonstrated that these models can produce better explanations than students, answer multiple-choice questions at or above the class average, and generate code that can pass automated tests in introductory courses. These capabilities have prompted instructors to rapidly adapt their courses and assessment methods to accommodate changes in learning objectives and the potential for academic integrity violations. While some scholars have advocated for the integration of visual problems as a safeguard against the capabilities of language models, new multimodal language models now have vision and language capabilities that may allow them to analyze and solve visual problems. In this paper, we evaluate the performance of two large multimodal models on visual assignments, with a specific focus on Parsons problems presented across diverse visual representations. Our results show that GPT-4V solved 96.7\% of these visual problems, struggling minimally with a single Parsons problem. Conversely, Bard performed poorly by only solving 69.2\% of problems, struggling with common issues like hallucinations and refusals. These findings suggest that merely transitioning to visual programming problems might not be a panacea to issues of academic integrity in the generative AI era.