 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Autograding: Large Language Models as Test Suite Generators for Introductory Programming
Nov 14, 2024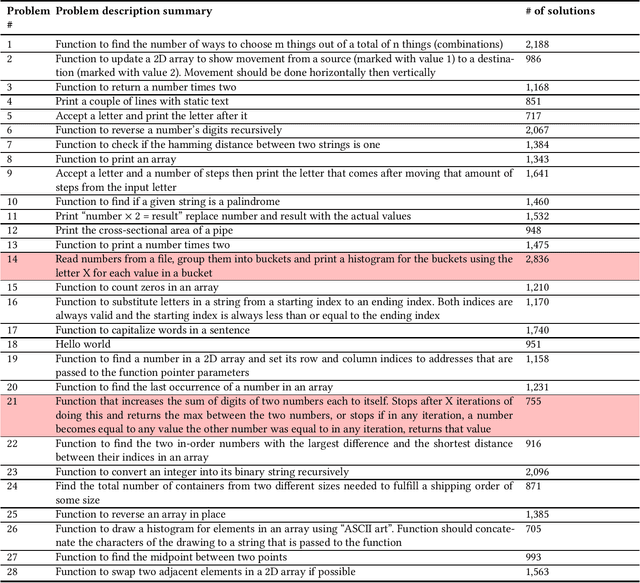



Automatically graded programming assignments provide instant feedback to students and significantly reduce manual grading time for instructors. However, creating comprehensive suites of test cases for programming problems within automatic graders can be time-consuming and complex. The effort needed to define test suites may deter some instructors from creating additional problems or lead to inadequate test coverage, potentially resulting in misleading feedback on student solutions. Such limitations may reduce student access to the well-documented benefits of timely feedback when learning programming. In this work, we evaluate the effectiveness of using Large Language Models (LLMs), as part of a larger workflow, to automatically generate test suites for CS1-level programming problems. Each problem's statement and reference solution are provided to GPT-4 to produce a test suite that can be used by an autograder. We evaluate our proposed approach using a sample of 26 problems, and more than 25,000 attempted solutions to those problems, submitted by students in an introductory programming course. We compare the performance of the LLM-generated test suites against the instructor-created test suites for each problem. Our findings reveal that LLM-generated test suites can correctly identify most valid solutions, and for most problems are at least as comprehensive as the instructor test suites. Additionally, the LLM-generated test suites exposed ambiguities in some problem statements, underscoring their potential to improve both autograding and instructional design.
The Robots are Here: Navigating the Generative AI Revolution in Computing Education
Oct 01, 2023Recent advancements in artificial intelligence (AI) are fundamentally reshaping computing, with large language models (LLMs) now effectively being able to generate and interpret source code and natural language instructions. These emergent capabilities have sparked urgent questions in the computing education community around how educators should adapt their pedagogy to address the challenges and to leverage the opportunities presented by this new technology. In this working group report, we undertake a comprehensive exploration of LLMs in the context of computing education and make five significant contributions. First, we provide a detailed review of the literature on LLMs in computing education and synthesise findings from 71 primary articles. Second, we report the findings of a survey of computing students and instructors from across 20 countries, capturing prevailing attitudes towards LLMs and their use in computing education contexts. Third, to understand how pedagogy is already changing, we offer insights collected from in-depth interviews with 22 computing educators from five continents who have already adapted their curricula and assessments. Fourth, we use the ACM Code of Ethics to frame a discussion of ethical issues raised by the use of large language models in computing education, and we provide concrete advice for policy makers, educators, and students. Finally, we benchmark the performance of LLMs on various computing education datasets, and highlight the extent to which the capabilities of current models are rapidly improving. Our aim is that this report will serve as a focal point for both researchers and practitioners who are exploring, adapting, using, and evaluating LLMs and LLM-based tools in computing classrooms.