 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Student Interaction with AI-Powered Next-Step Hints: Strategies and Challenges
Nov 09, 2025Automated feedback generation plays a crucial role in enhancing personalized learning experiences in computer science education. Among different types of feedback, next-step hint feedback is particularly important, as it provides students with actionable steps to progress towards solving programming tasks. This study investigates how students interact with an AI-driven next-step hint system in an in-IDE learning environment. We gathered and analyzed a dataset from 34 students solving Kotlin tasks, containing detailed hint interaction logs. We applied process mining techniques and identified 16 common interaction scenarios. Semi-structured interviews with 6 students revealed strategies for managing unhelpful hints, such as adapting partial hints or modifying code to generate variations of the same hint. These findings, combined with our publicly available dataset, offer valuable opportunities for future research and provide key insights into student behavior, helping improve hint design for enhanced learning support.
You're (Not) My Type -- Can LLMs Generate Feedback of Specific Types for Introductory Programming Tasks?
Dec 04, 2024Background: Feedback as one of the most influential factors for learning has been subject to a great body of research. It plays a key role in the development of educational technology systems and is traditionally rooted in deterministic feedback defined by experts and their experience. However, with the rise of generative AI and especially Large Language Models (LLMs), we expect feedback as part of learning systems to transform, especially for the context of programming. In the past, it was challenging to automate feedback for learners of programming. LLMs may create new possibilities to provide richer, and more individual feedback than ever before. Objectives: This paper aims to generate specific types of feedback for introductory programming tasks using LLMs. We revisit existing feedback taxonomies to capture the specifics of the generated feedback, such as randomness, uncertainty, and degrees of variation. Methods: We iteratively designed prompts for the generation of specific feedback types (as part of existing feedback taxonomies) in response to authentic student programs. We then evaluated the generated output and determined to what extent it reflected certain feedback types. Results and Conclusion: The present work provides a better understanding of different feedback dimensions and characteristics. The results have implications for future feedback research with regard to, for example, feedback effects and learners' informational needs. It further provides a basis for the development of new tools and learning systems for novice programmers including feedback generated by AI.
One Step at a Time: Combining LLMs and Static Analysis to Generate Next-Step Hints for Programming Tasks
Oct 11, 2024Students often struggle with solving programming problems when learning to code, especially when they have to do it online, with one of the most common disadvantages of working online being the lack of personalized help. This help can be provided as next-step hint generation, i.e., showing a student what specific small step they need to do next to get to the correct solution. There are many ways to generate such hints, with large language models (LLMs) being among the most actively studied right now. While LLMs constitute a promising technology for providing personalized help, combining them with other techniques, such as static analysis, can significantly improve the output quality. In this work, we utilize this idea and propose a novel system to provide both textual and code hints for programming tasks. The pipeline of the proposed approach uses a chain-of-thought prompting technique and consists of three distinct steps: (1) generating subgoals - a list of actions to proceed with the task from the current student's solution, (2) generating the code to achieve the next subgoal, and (3) generating the text to describe this needed action. During the second step, we apply static analysis to the generated code to control its size and quality. The tool is implemented as a modification to the open-source JetBrains Academy plugin, supporting students in their in-IDE courses. To evaluate our approach, we propose a list of criteria for all steps in our pipeline and conduct two rounds of expert validation. Finally, we evaluate the next-step hints in a classroom with 14 students from two universities. Our results show that both forms of the hints - textual and code - were helpful for the students, and the proposed system helped them to proceed with the coding tasks.
Students' Perceptions and Use of Generative AI Tools for Programming Across Different Computing Courses
Oct 09, 2024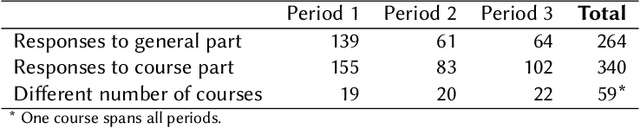
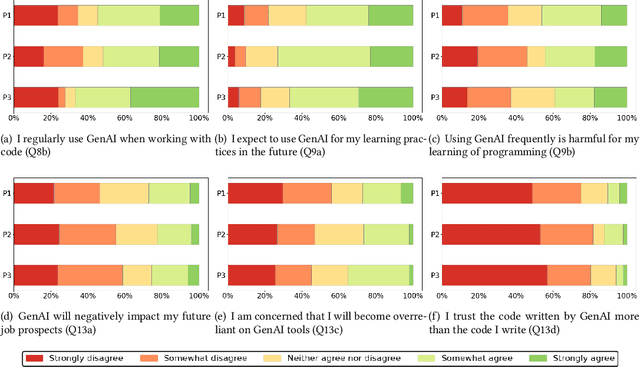
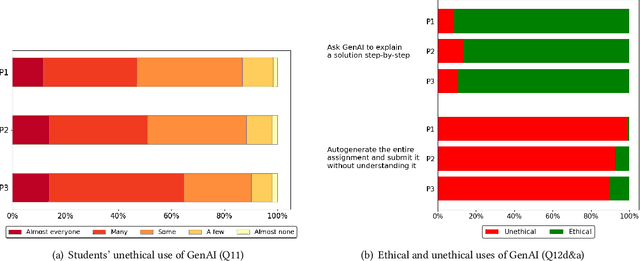
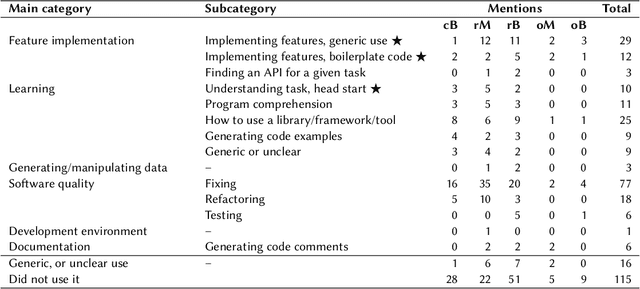
Investigation of students' perceptions and opinions on the use of generative artificial intelligence (GenAI) in education is a topic gaining much interest. Studies addressing this are typically conducted with large heterogeneous groups, at one moment in time. However, how students perceive and use GenAI tools can potentially depend on many factors, including their background knowledge, familiarity with the tools, and the learning goals and policies of the courses they are taking. In this study we explore how students following computing courses use GenAI for programming-related tasks across different programs and courses: Bachelor and Master, in courses in which learning programming is the learning goal, courses that require programming as a means to achieve another goal, and in courses in which programming is optional, but can be useful. We are also interested in changes over time, since GenAI capabilities are changing at a fast pace, and users are adopting GenAI increasingly. We conducted three consecutive surveys (fall `23, winter `23, and spring `24) among students of all computing programs of a large European research university. We asked questions on the use in education, ethics, and job prospects, and we included specific questions on the (dis)allowed use of GenAI tools in the courses they were taking at the time. We received 264 responses, which we quantitatively and qualitatively analyzed, to find out how students have employed GenAI tools across 59 different computing courses, and whether the opinion of an average student about these tools evolves over time. Our study contributes to the emerging discussion of how to differentiate GenAI use across different courses, and how to align its use with the learning goals of a computing course.
The Robots are Here: Navigating the Generative AI Revolution in Computing Education
Oct 01, 2023Recent advancements in artificial intelligence (AI) are fundamentally reshaping computing, with large language models (LLMs) now effectively being able to generate and interpret source code and natural language instructions. These emergent capabilities have sparked urgent questions in the computing education community around how educators should adapt their pedagogy to address the challenges and to leverage the opportunities presented by this new technology. In this working group report, we undertake a comprehensive exploration of LLMs in the context of computing education and make five significant contributions. First, we provide a detailed review of the literature on LLMs in computing education and synthesise findings from 71 primary articles. Second, we report the findings of a survey of computing students and instructors from across 20 countries, capturing prevailing attitudes towards LLMs and their use in computing education contexts. Third, to understand how pedagogy is already changing, we offer insights collected from in-depth interviews with 22 computing educators from five continents who have already adapted their curricula and assessments. Fourth, we use the ACM Code of Ethics to frame a discussion of ethical issues raised by the use of large language models in computing education, and we provide concrete advice for policy makers, educators, and students. Finally, we benchmark the performance of LLMs on various computing education datasets, and highlight the extent to which the capabilities of current models are rapidly improving. Our aim is that this report will serve as a focal point for both researchers and practitioners who are exploring, adapting, using, and evaluating LLMs and LLM-based tools in computing classrooms.
Exploring the Potential of Large Language Models to Generate Formative Programming Feedback
Aug 31, 2023
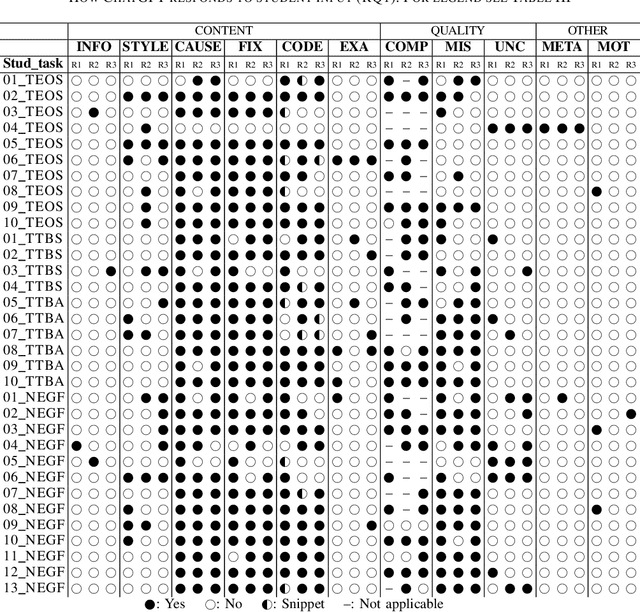
Ever since the emergence of large language models (LLMs) and related applications, such as ChatGPT, its performance and error analysis for programming tasks have been subject to research. In this work-in-progress paper, we explore the potential of such LLMs for computing educators and learners, as we analyze the feedback it generates to a given input containing program code. In particular, we aim at (1) exploring how an LLM like ChatGPT responds to students seeking help with their introductory programming tasks, and (2) identifying feedback types in its responses. To achieve these goals, we used students' programming sequences from a dataset gathered within a CS1 course as input for ChatGPT along with questions required to elicit feedback and correct solutions. The results show that ChatGPT performs reasonably well for some of the introductory programming tasks and student errors, which means that students can potentially benefit. However, educators should provide guidance on how to use the provided feedback, as it can contain misleading information for novices.