 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudents' Perceptions and Use of Generative AI Tools for Programming Across Different Computing Courses
Oct 09, 2024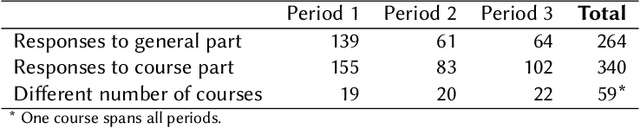
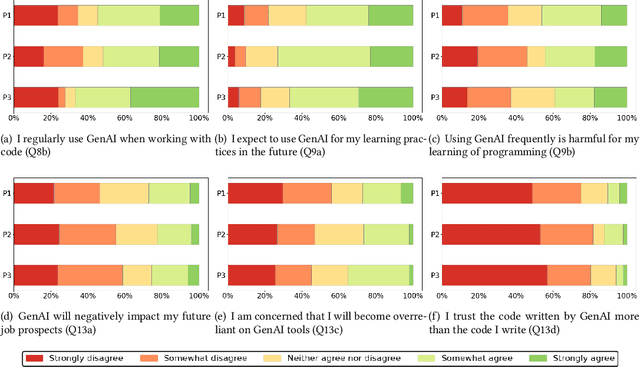
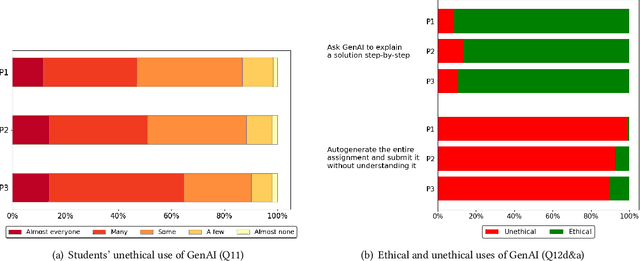
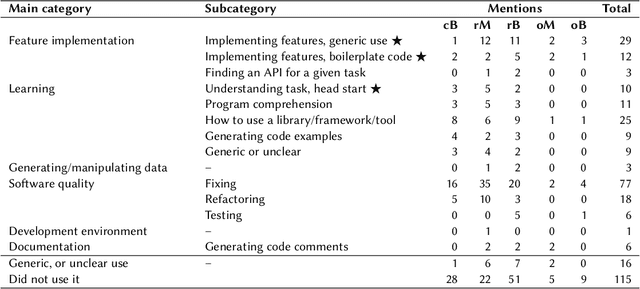
Investigation of students' perceptions and opinions on the use of generative artificial intelligence (GenAI) in education is a topic gaining much interest. Studies addressing this are typically conducted with large heterogeneous groups, at one moment in time. However, how students perceive and use GenAI tools can potentially depend on many factors, including their background knowledge, familiarity with the tools, and the learning goals and policies of the courses they are taking. In this study we explore how students following computing courses use GenAI for programming-related tasks across different programs and courses: Bachelor and Master, in courses in which learning programming is the learning goal, courses that require programming as a means to achieve another goal, and in courses in which programming is optional, but can be useful. We are also interested in changes over time, since GenAI capabilities are changing at a fast pace, and users are adopting GenAI increasingly. We conducted three consecutive surveys (fall `23, winter `23, and spring `24) among students of all computing programs of a large European research university. We asked questions on the use in education, ethics, and job prospects, and we included specific questions on the (dis)allowed use of GenAI tools in the courses they were taking at the time. We received 264 responses, which we quantitatively and qualitatively analyzed, to find out how students have employed GenAI tools across 59 different computing courses, and whether the opinion of an average student about these tools evolves over time. Our study contributes to the emerging discussion of how to differentiate GenAI use across different courses, and how to align its use with the learning goals of a computing course.
Prompting for products: Investigating design space exploration strategies for text-to-image generative models
Jul 22, 2024Text-to-image models are enabling efficient design space exploration, rapidly generating images from text prompts. However, many generative AI tools are imperfect for product design applications as they are not built for the goals and requirements of product design. The unclear link between text input and image output further complicates their application. This work empirically investigates design space exploration strategies that can successfully yield product images that are feasible, novel, and aesthetic, which are three common goals in product design. Specifically, user actions within the global and local editing modes, including their time spent, prompt length, mono vs. multi-criteria prompts, and goal orientation of prompts, are analyzed. Key findings reveal the pivotal role of mono vs. multi-criteria and goal orientation of prompts in achieving specific design goals over time and prompt length. The study recommends prioritizing the use of multi-criteria prompts for feasibility and novelty during global editing, while favoring mono-criteria prompts for aesthetics during local editing. Overall, this paper underscores the nuanced relationship between the AI-driven text-to-image models and their effectiveness in product design, urging designers to carefully structure prompts during different editing modes to better meet the unique demands of product design.
CAD-Prompted Generative Models: A Pathway to Feasible and Novel Engineering Designs
Jul 11, 2024



Text-to-image generative models have increasingly been used to assist designers during concept generation in various creative domains, such as graphic design, user interface design, and fashion design. However, their applications in engineering design remain limited due to the models' challenges in generating images of feasible designs concepts. To address this issue, this paper introduces a method that improves the design feasibility by prompting the generation with feasible CAD images. In this work, the usefulness of this method is investigated through a case study with a bike design task using an off-the-shelf text-to-image model, Stable Diffusion 2.1. A diverse set of bike designs are produced in seven different generation settings with varying CAD image prompting weights, and these designs are evaluated on their perceived feasibility and novelty. Results demonstrate that the CAD image prompting successfully helps text-to-image models like Stable Diffusion 2.1 create visibly more feasible design images. While a general tradeoff is observed between feasibility and novelty, when the prompting weight is kept low around 0.35, the design feasibility is significantly improved while its novelty remains on par with those generated by text prompts alone. The insights from this case study offer some guidelines for selecting the appropriate CAD image prompting weight for different stages of the engineering design process. When utilized effectively, our CAD image prompting method opens doors to a wider range of applications of text-to-image models in engineering design.
It's about time: Online Macrotask Sequencing in Expert Crowdsourcing
Jan 15, 2016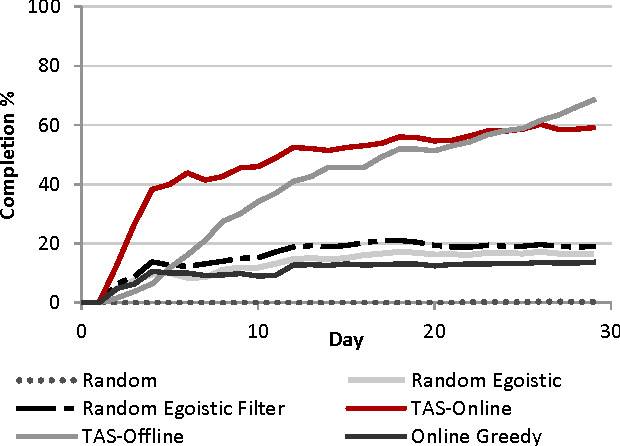
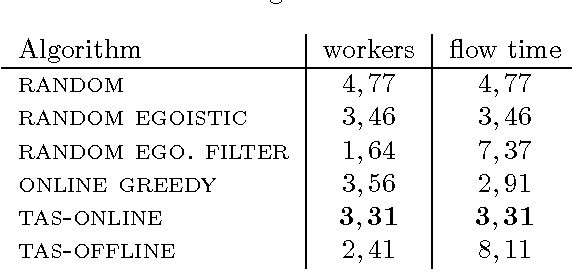
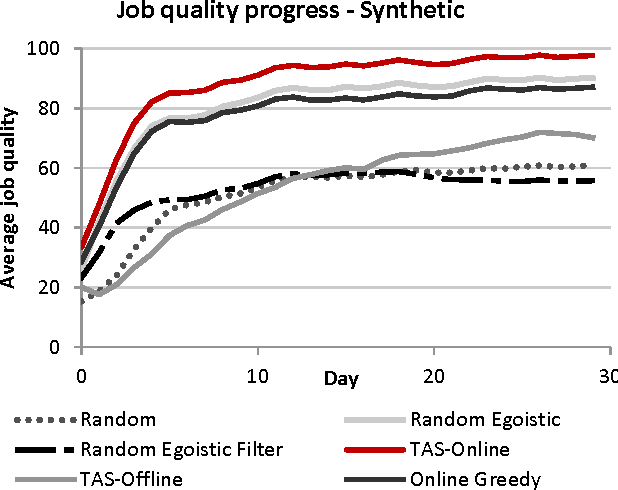
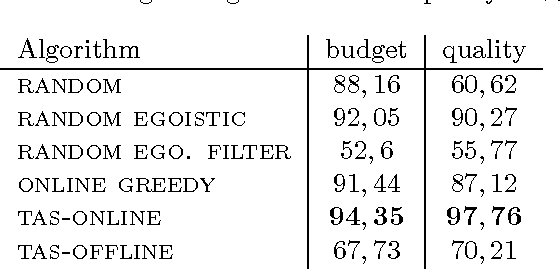
We introduce the problem of Task Assignment and Sequencing (TAS), which adds the timeline perspective to expert crowdsourcing optimization. Expert crowdsourcing involves macrotasks, like document writing, product design, or web development, which take more time than typical binary microtasks, require expert skills, assume varying degrees of knowledge over a topic, and require crowd workers to build on each other's contributions. Current works usually assume offline optimization models, which consider worker and task arrivals known and do not take into account the element of time. Realistically however, time is critical: tasks have deadlines, expert workers are available only at specific time slots, and worker/task arrivals are not known a-priori. Our work is the first to address the problem of optimal task sequencing for online, heterogeneous, time-constrained macrotasks. We propose tas-online, an online algorithm that aims to complete as many tasks as possible within budget, required quality and a given timeline, without future input information regarding job release dates or worker availabilities. Results, comparing tas-online to four typical benchmarks, show that it achieves more completed jobs, lower flow times and higher job quality. This work has practical implications for improving the Quality of Service of current crowdsourcing platforms, allowing them to offer cost, quality and time improvements for expert tasks.
Engineering Crowdsourced Stream Processing Systems
Aug 04, 2014
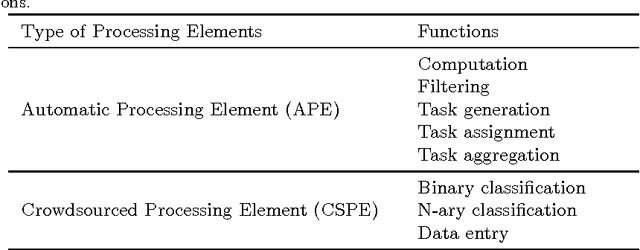

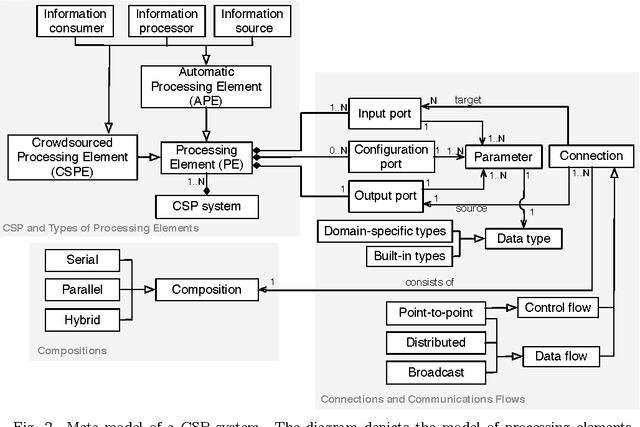
A crowdsourced stream processing system (CSP) is a system that incorporates crowdsourced tasks in the processing of a data stream. This can be seen as enabling crowdsourcing work to be applied on a sample of large-scale data at high speed, or equivalently, enabling stream processing to employ human intelligence. It also leads to a substantial expansion of the capabilities of data processing systems. Engineering a CSP system requires the combination of human and machine computation elements. From a general systems theory perspective, this means taking into account inherited as well as emerging properties from both these elements. In this paper, we position CSP systems within a broader taxonomy, outline a series of design principles and evaluation metrics, present an extensible framework for their design, and describe several design patterns. We showcase the capabilities of CSP systems by performing a case study that applies our proposed framework to the design and analysis of a real system (AIDR) that classifies social media messages during time-critical crisis events. Results show that compared to a pure stream processing system, AIDR can achieve a higher data classification accuracy, while compared to a pure crowdsourcing solution, the system makes better use of human workers by requiring much less manual work effort.