 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Language Models How to Code Like Learners: Conversational Serialization for Student Simulation
Apr 12, 2026Artificial models that simulate how learners act and respond within educational systems are a promising tool for evaluating tutoring strategies and feedback mechanisms at scale. However, many existing approaches in programming education rely on prompting large, proprietary language models, raising concerns around privacy, cost, and dependence. In this work, we propose a method for training open-weight artificial programming learners using authentic student process data. Our approach serializes temporal log traces into a conversational format, representing each student's problem-solving process as a dialogue between the learner and their automated assessment system. Student code submissions and environment feedback, such as test outcomes, grades, and error traces, form alternating conversational turns, enabling models to learn from the iterative debugging process. We additionally introduce a training pipeline combining supervised fine-tuning with preference optimization to align models with authentic student debugging behavior. We evaluate our framework by training Qwen models at 4B and 8B scales on a large-scale dataset of real student submissions to Python programming assignments. Our results show that incorporating environment feedback strengthens the models' ability to replicate student debugging behavior, improving over both prior code-only approaches and prompted large language models baselines in functional alignment and code similarity. We release our code to support reproducibility.
Can We Improve Educational Diagram Generation with In-Context Examples? Not if a Hallucination Spoils the Bunch
Jan 28, 2026Generative artificial intelligence (AI) has found a widespread use in computing education; at the same time, quality of generated materials raises concerns among educators and students. This study addresses this issue by introducing a novel method for diagram code generation with in-context examples based on the Rhetorical Structure Theory (RST), which aims to improve diagram generation by aligning models' output with user expectations. Our approach is evaluated by computer science educators, who assessed 150 diagrams generated with large language models (LLMs) for logical organization, connectivity, layout aesthetic, and AI hallucination. The assessment dataset is additionally investigated for its utility in automated diagram evaluation. The preliminary results suggest that our method decreases the rate of factual hallucination and improves diagram faithfulness to provided context; however, due to LLMs' stochasticity, the quality of the generated diagrams varies. Additionally, we present an in-depth analysis and discussion on the connection between AI hallucination and the quality of generated diagrams, which reveals that text contexts of higher complexity lead to higher rates of hallucination and LLMs often fail to detect mistakes in their output.
From Prompts to Propositions: A Logic-Based Lens on Student-LLM Interactions
Apr 25, 2025Background and Context. The increasing integration of large language models (LLMs) in computing education presents an emerging challenge in understanding how students use LLMs and craft prompts to solve computational tasks. Prior research has used both qualitative and quantitative methods to analyze prompting behavior, but these approaches lack scalability or fail to effectively capture the semantic evolution of prompts. Objective. In this paper, we investigate whether students prompts can be systematically analyzed using propositional logic constraints. We examine whether this approach can identify patterns in prompt evolution, detect struggling students, and provide insights into effective and ineffective strategies. Method. We introduce Prompt2Constraints, a novel method that translates students prompts into logical constraints. The constraints are able to represent the intent of the prompts in succinct and quantifiable ways. We used this approach to analyze a dataset of 1,872 prompts from 203 students solving introductory programming tasks. Findings. We find that while successful and unsuccessful attempts tend to use a similar number of constraints overall, when students fail, they often modify their prompts more significantly, shifting problem-solving strategies midway. We also identify points where specific interventions could be most helpful to students for refining their prompts. Implications. This work offers a new and scalable way to detect students who struggle in solving natural language programming tasks. This work could be extended to investigate more complex tasks and integrated into programming tools to provide real-time support.
The Role of Generative AI in Software Student CollaborAItion
Jan 23, 2025Collaboration is a crucial part of computing education. The increase in AI capabilities over the last couple of years is bound to profoundly affect all aspects of systems and software engineering, including collaboration. In this position paper, we consider a scenario where AI agents would be able to take on any role in collaborative processes in computing education. We outline these roles, the activities and group dynamics that software development currently include, and discuss if and in what way AI could facilitate these roles and activities. The goal of our work is to envision and critically examine potential futures. We present scenarios suggesting how AI can be integrated into existing collaborations. These are contrasted by design fictions that help demonstrate the new possibilities and challenges for computing education in the AI era.
Beyond the Hype: A Comprehensive Review of Current Trends in Generative AI Research, Teaching Practices, and Tools
Dec 19, 2024



Generative AI (GenAI) is advancing rapidly, and the literature in computing education is expanding almost as quickly. Initial responses to GenAI tools were mixed between panic and utopian optimism. Many were fast to point out the opportunities and challenges of GenAI. Researchers reported that these new tools are capable of solving most introductory programming tasks and are causing disruptions throughout the curriculum. These tools can write and explain code, enhance error messages, create resources for instructors, and even provide feedback and help for students like a traditional teaching assistant. In 2024, new research started to emerge on the effects of GenAI usage in the computing classroom. These new data involve the use of GenAI to support classroom instruction at scale and to teach students how to code with GenAI. In support of the former, a new class of tools is emerging that can provide personalized feedback to students on their programming assignments or teach both programming and prompting skills at the same time. With the literature expanding so rapidly, this report aims to summarize and explain what is happening on the ground in computing classrooms. We provide a systematic literature review; a survey of educators and industry professionals; and interviews with educators using GenAI in their courses, educators studying GenAI, and researchers who create GenAI tools to support computing education. The triangulation of these methods and data sources expands the understanding of GenAI usage and perceptions at this critical moment for our community.
Breaking the Programming Language Barrier: Multilingual Prompting to Empower Non-Native English Learners
Dec 17, 2024


Non-native English speakers (NNES) face multiple barriers to learning programming. These barriers can be obvious, such as the fact that programming language syntax and instruction are often in English, or more subtle, such as being afraid to ask for help in a classroom full of native English speakers. However, these barriers are frustrating because many NNES students know more about programming than they can articulate in English. Advances in generative AI (GenAI) have the potential to break down these barriers because state of the art models can support interactions in multiple languages. Moreover, recent work has shown that GenAI can be highly accurate at code generation and explanation. In this paper, we provide the first exploration of NNES students prompting in their native languages (Arabic, Chinese, and Portuguese) to generate code to solve programming problems. Our results show that students are able to successfully use their native language to solve programming problems, but not without some difficulty specifying programming terminology and concepts. We discuss the challenges they faced, the implications for practice in the short term, and how this might transform computing education globally in the long term.
On the Opportunities of Large Language Models for Programming Process Data
Nov 01, 2024

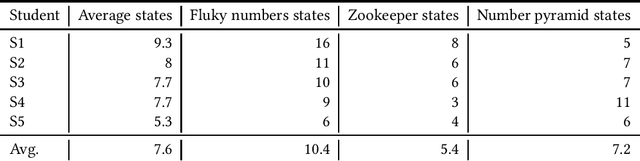

Computing educators and researchers have used programming process data to understand how programs are constructed and what sorts of problems students struggle with. Although such data shows promise for using it for feedback, fully automated programming process feedback systems have still been an under-explored area. The recent emergence of large language models (LLMs) have yielded additional opportunities for researchers in a wide variety of fields. LLMs are efficient at transforming content from one format to another, leveraging the body of knowledge they have been trained with in the process. In this article, we discuss opportunities of using LLMs for analyzing programming process data. To complement our discussion, we outline a case study where we have leveraged LLMs for automatically summarizing the programming process and for creating formative feedback on the programming process. Overall, our discussion and findings highlight that the computing education research and practice community is again one step closer to automating formative programming process-focused feedback.
Synthetic Students: A Comparative Study of Bug Distribution Between Large Language Models and Computing Students
Oct 11, 2024



Large language models (LLMs) present an exciting opportunity for generating synthetic classroom data. Such data could include code containing a typical distribution of errors, simulated student behaviour to address the cold start problem when developing education tools, and synthetic user data when access to authentic data is restricted due to privacy reasons. In this research paper, we conduct a comparative study examining the distribution of bugs generated by LLMs in contrast to those produced by computing students. Leveraging data from two previous large-scale analyses of student-generated bugs, we investigate whether LLMs can be coaxed to exhibit bug patterns that are similar to authentic student bugs when prompted to inject errors into code. The results suggest that unguided, LLMs do not generate plausible error distributions, and many of the generated errors are unlikely to be generated by real students. However, with guidance including descriptions of common errors and typical frequencies, LLMs can be shepherded to generate realistic distributions of errors in synthetic code.
Integrating Natural Language Prompting Tasks in Introductory Programming Courses
Oct 04, 2024



Introductory programming courses often emphasize mastering syntax and basic constructs before progressing to more complex and interesting programs. This bottom-up approach can be frustrating for novices, shifting the focus away from problem solving and potentially making computing less appealing to a broad range of students. The rise of generative AI for code production could partially address these issues by fostering new skills via interaction with AI models, including constructing high-level prompts and evaluating code that is automatically generated. In this experience report, we explore the inclusion of two prompt-focused activities in an introductory course, implemented across four labs in a six-week module. The first requires students to solve computational problems by writing natural language prompts, emphasizing problem-solving over syntax. The second involves students crafting prompts to generate code equivalent to provided fragments, to foster an understanding of the relationship between prompts and code. Most of the students in the course had reported finding programming difficult to learn, often citing frustrations with syntax and debugging. We found that self-reported difficulty with learning programming had a strong inverse relationship with performance on traditional programming assessments such as tests and projects, as expected. However, performance on the natural language tasks was less strongly related to self-reported difficulty, suggesting they may target different skills. Learning how to communicate with AI coding models is becoming an important skill, and natural language prompting tasks may appeal to a broad range of students.
Evaluating Language Models for Generating and Judging Programming Feedback
Jul 05, 2024

The emergence of large language models (LLMs) has transformed research and practice in a wide range of domains. Within the computing education research (CER) domain, LLMs have received plenty of attention especially in the context of learning programming. Much of the work on LLMs in CER has however focused on applying and evaluating proprietary models. In this article, we evaluate the efficiency of open-source LLMs in generating high-quality feedback for programming assignments, and in judging the quality of the programming feedback, contrasting the results against proprietary models. Our evaluations on a dataset of students' submissions to Python introductory programming exercises suggest that the state-of-the-art open-source LLMs (Meta's Llama3) are almost on-par with proprietary models (GPT-4o) in both the generation and assessment of programming feedback. We further demonstrate the efficiency of smaller LLMs in the tasks, and highlight that there are a wide range of LLMs that are accessible even for free for educators and practitioners.