 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniLingua: A Small Open-Source LLM for European Languages
Dec 15, 2025Large language models are powerful but often limited by high computational cost, privacy concerns, and English-centric training. Recent progress demonstrates that small, efficient models with around one billion parameters can deliver strong results and enable on-device use. This paper introduces MiniLingua, a multilingual open-source LLM of one billion parameters trained from scratch for 13 European languages, designed to balance coverage and instruction-following capabilities. Based on evaluation results, the instruction-tuned version of MiniLingua outperforms EuroLLM, a model with a similar training approach but a larger training budget, on summarization, classification and both open- and closed-book question answering. Moreover, it remains competitive with more advanced state-of-the-art models on open-ended generation tasks. We release model weights, tokenizer and source code used for data processing and model training.
ViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models
May 19, 2025Integrating Large Language Models with symbolic planners is a promising direction for obtaining verifiable and grounded plans compared to planning in natural language, with recent works extending this idea to visual domains using Vision-Language Models (VLMs). However, rigorous comparison between VLM-grounded symbolic approaches and methods that plan directly with a VLM has been hindered by a lack of common environments, evaluation protocols and model coverage. We introduce ViPlan, the first open-source benchmark for Visual Planning with symbolic predicates and VLMs. ViPlan features a series of increasingly challenging tasks in two domains: a visual variant of the classic Blocksworld planning problem and a simulated household robotics environment. We benchmark nine open-source VLM families across multiple sizes, along with selected closed models, evaluating both VLM-grounded symbolic planning and using the models directly to propose actions. We find symbolic planning to outperform direct VLM planning in Blocksworld, where accurate image grounding is crucial, whereas the opposite is true in the household robotics tasks, where commonsense knowledge and the ability to recover from errors are beneficial. Finally, we show that across most models and methods, there is no significant benefit to using Chain-of-Thought prompting, suggesting that current VLMs still struggle with visual reasoning.
Evaluating Language Models for Generating and Judging Programming Feedback
Jul 05, 2024

The emergence of large language models (LLMs) has transformed research and practice in a wide range of domains. Within the computing education research (CER) domain, LLMs have received plenty of attention especially in the context of learning programming. Much of the work on LLMs in CER has however focused on applying and evaluating proprietary models. In this article, we evaluate the efficiency of open-source LLMs in generating high-quality feedback for programming assignments, and in judging the quality of the programming feedback, contrasting the results against proprietary models. Our evaluations on a dataset of students' submissions to Python introductory programming exercises suggest that the state-of-the-art open-source LLMs (Meta's Llama3) are almost on-par with proprietary models (GPT-4o) in both the generation and assessment of programming feedback. We further demonstrate the efficiency of smaller LLMs in the tasks, and highlight that there are a wide range of LLMs that are accessible even for free for educators and practitioners.
Generating Code World Models with Large Language Models Guided by Monte Carlo Tree Search
May 24, 2024In this work we consider Code World Models, world models generated by a Large Language Model (LLM) in the form of Python code for model-based Reinforcement Learning (RL). Calling code instead of LLMs for planning has the advantages of being precise, reliable, interpretable, and extremely efficient. However, writing appropriate Code World Models requires the ability to understand complex instructions, to generate exact code with non-trivial logic and to self-debug a long program with feedback from unit tests and environment trajectories. To address these challenges, we propose Generate, Improve and Fix with Monte Carlo Tree Search (GIF-MCTS), a new code generation strategy for LLMs. To test our approach, we introduce the Code World Models Benchmark (CWMB), a suite of program synthesis and planning tasks comprised of 18 diverse RL environments paired with corresponding textual descriptions and curated trajectories. GIF-MCTS surpasses all baselines on the CWMB and two other benchmarks, and we show that the Code World Models synthesized with it can be successfully used for planning, resulting in model-based RL agents with greatly improved sample efficiency and inference speed.
Open Source Language Models Can Provide Feedback: Evaluating LLMs' Ability to Help Students Using GPT-4-As-A-Judge
May 08, 2024Large language models (LLMs) have shown great potential for the automatic generation of feedback in a wide range of computing contexts. However, concerns have been voiced around the privacy and ethical implications of sending student work to proprietary models. This has sparked considerable interest in the use of open source LLMs in education, but the quality of the feedback that such open models can produce remains understudied. This is a concern as providing flawed or misleading generated feedback could be detrimental to student learning. Inspired by recent work that has utilised very powerful LLMs, such as GPT-4, to evaluate the outputs produced by less powerful models, we conduct an automated analysis of the quality of the feedback produced by several open source models using a dataset from an introductory programming course. First, we investigate the viability of employing GPT-4 as an automated evaluator by comparing its evaluations with those of a human expert. We observe that GPT-4 demonstrates a bias toward positively rating feedback while exhibiting moderate agreement with human raters, showcasing its potential as a feedback evaluator. Second, we explore the quality of feedback generated by several leading open-source LLMs by using GPT-4 to evaluate the feedback. We find that some models offer competitive performance with popular proprietary LLMs, such as ChatGPT, indicating opportunities for their responsible use in educational settings.
Benchmarking Educational Program Repair
May 08, 2024The emergence of large language models (LLMs) has sparked enormous interest due to their potential application across a range of educational tasks. For example, recent work in programming education has used LLMs to generate learning resources, improve error messages, and provide feedback on code. However, one factor that limits progress within the field is that much of the research uses bespoke datasets and different evaluation metrics, making direct comparisons between results unreliable. Thus, there is a pressing need for standardization and benchmarks that facilitate the equitable comparison of competing approaches. One task where LLMs show great promise is program repair, which can be used to provide debugging support and next-step hints to students. In this article, we propose a novel educational program repair benchmark. We curate two high-quality publicly available programming datasets, present a unified evaluation procedure introducing a novel evaluation metric rouge@k for approximating the quality of repairs, and evaluate a set of five recent models to establish baseline performance.
In-Context Symbolic Regression: Leveraging Language Models for Function Discovery
Apr 29, 2024


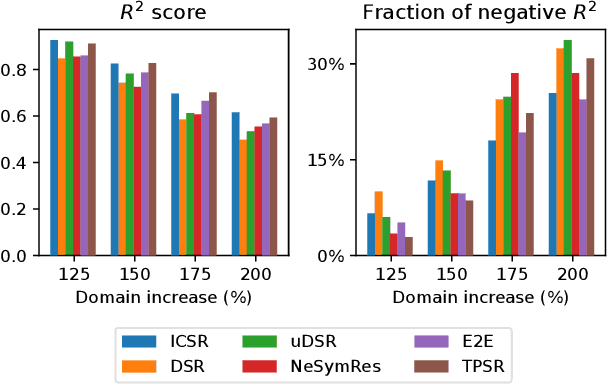
Symbolic Regression (SR) is a task which aims to extract the mathematical expression underlying a set of empirical observations. Transformer-based methods trained on SR datasets detain the current state-of-the-art in this task, while the application of Large Language Models (LLMs) to SR remains unexplored. This work investigates the integration of pre-trained LLMs into the SR pipeline, utilizing an approach that iteratively refines a functional form based on the prediction error it achieves on the observation set, until it reaches convergence. Our method leverages LLMs to propose an initial set of possible functions based on the observations, exploiting their strong pre-training prior. These functions are then iteratively refined by the model itself and by an external optimizer for their coefficients. The process is repeated until the results are satisfactory. We then analyze Vision-Language Models in this context, exploring the inclusion of plots as visual inputs to aid the optimization process. Our findings reveal that LLMs are able to successfully recover good symbolic equations that fit the given data, outperforming SR baselines based on Genetic Programming, with the addition of images in the input showing promising results for the most complex benchmarks.