 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Symbolic Regression: Leveraging Language Models for Function Discovery
Paper and Code



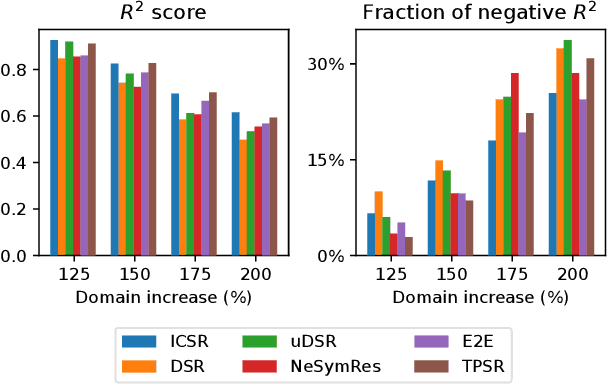
Symbolic Regression (SR) is a task which aims to extract the mathematical expression underlying a set of empirical observations. Transformer-based methods trained on SR datasets detain the current state-of-the-art in this task, while the application of Large Language Models (LLMs) to SR remains unexplored. This work investigates the integration of pre-trained LLMs into the SR pipeline, utilizing an approach that iteratively refines a functional form based on the prediction error it achieves on the observation set, until it reaches convergence. Our method leverages LLMs to propose an initial set of possible functions based on the observations, exploiting their strong pre-training prior. These functions are then iteratively refined by the model itself and by an external optimizer for their coefficients. The process is repeated until the results are satisfactory. We then analyze Vision-Language Models in this context, exploring the inclusion of plots as visual inputs to aid the optimization process. Our findings reveal that LLMs are able to successfully recover good symbolic equations that fit the given data, outperforming SR baselines based on Genetic Programming, with the addition of images in the input showing promising results for the most complex benchmarks.