 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing the Utility, Preference, and Performance of Course Material Search Functionality and Retrieval-Augmented Generation Large Language Model (RAG-LLM) AI Chatbots in Information-Seeking Tasks
Oct 17, 2024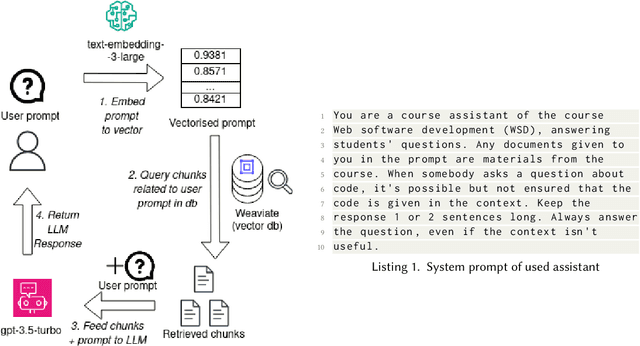

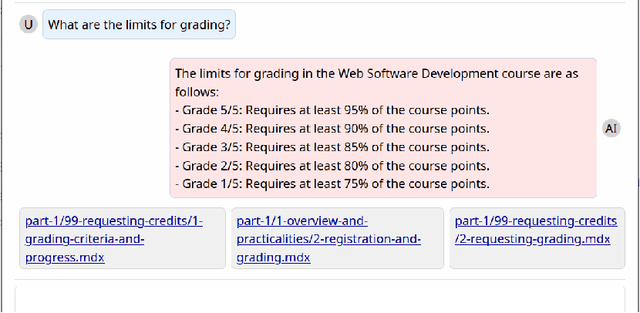
Providing sufficient support for students requires substantial resources, especially considering the growing enrollment numbers. Students need help in a variety of tasks, ranging from information-seeking to requiring support with course assignments. To explore the utility of recent large language models (LLMs) as a support mechanism, we developed an LLM-powered AI chatbot that augments the answers that are produced with information from the course materials. To study the effect of the LLM-powered AI chatbot, we conducted a lab-based user study (N=14), in which the participants worked on tasks from a web software development course. The participants were divided into two groups, where one of the groups first had access to the chatbot and then to a more traditional search functionality, while another group started with the search functionality and was then given the chatbot. We assessed the participants' performance and perceptions towards the chatbot and the search functionality and explored their preferences towards the support functionalities. Our findings highlight that both support mechanisms are seen as useful and that support mechanisms work well for specific tasks, while less so for other tasks. We also observe that students tended to prefer the second support mechanism more, where students who were first given the chatbot tended to prefer the search functionality and vice versa.
Evaluating Language Models for Generating and Judging Programming Feedback
Jul 05, 2024

The emergence of large language models (LLMs) has transformed research and practice in a wide range of domains. Within the computing education research (CER) domain, LLMs have received plenty of attention especially in the context of learning programming. Much of the work on LLMs in CER has however focused on applying and evaluating proprietary models. In this article, we evaluate the efficiency of open-source LLMs in generating high-quality feedback for programming assignments, and in judging the quality of the programming feedback, contrasting the results against proprietary models. Our evaluations on a dataset of students' submissions to Python introductory programming exercises suggest that the state-of-the-art open-source LLMs (Meta's Llama3) are almost on-par with proprietary models (GPT-4o) in both the generation and assessment of programming feedback. We further demonstrate the efficiency of smaller LLMs in the tasks, and highlight that there are a wide range of LLMs that are accessible even for free for educators and practitioners.
Benchmarking Educational Program Repair
May 08, 2024The emergence of large language models (LLMs) has sparked enormous interest due to their potential application across a range of educational tasks. For example, recent work in programming education has used LLMs to generate learning resources, improve error messages, and provide feedback on code. However, one factor that limits progress within the field is that much of the research uses bespoke datasets and different evaluation metrics, making direct comparisons between results unreliable. Thus, there is a pressing need for standardization and benchmarks that facilitate the equitable comparison of competing approaches. One task where LLMs show great promise is program repair, which can be used to provide debugging support and next-step hints to students. In this article, we propose a novel educational program repair benchmark. We curate two high-quality publicly available programming datasets, present a unified evaluation procedure introducing a novel evaluation metric rouge@k for approximating the quality of repairs, and evaluate a set of five recent models to establish baseline performance.
Open Source Language Models Can Provide Feedback: Evaluating LLMs' Ability to Help Students Using GPT-4-As-A-Judge
May 08, 2024Large language models (LLMs) have shown great potential for the automatic generation of feedback in a wide range of computing contexts. However, concerns have been voiced around the privacy and ethical implications of sending student work to proprietary models. This has sparked considerable interest in the use of open source LLMs in education, but the quality of the feedback that such open models can produce remains understudied. This is a concern as providing flawed or misleading generated feedback could be detrimental to student learning. Inspired by recent work that has utilised very powerful LLMs, such as GPT-4, to evaluate the outputs produced by less powerful models, we conduct an automated analysis of the quality of the feedback produced by several open source models using a dataset from an introductory programming course. First, we investigate the viability of employing GPT-4 as an automated evaluator by comparing its evaluations with those of a human expert. We observe that GPT-4 demonstrates a bias toward positively rating feedback while exhibiting moderate agreement with human raters, showcasing its potential as a feedback evaluator. Second, we explore the quality of feedback generated by several leading open-source LLMs by using GPT-4 to evaluate the feedback. We find that some models offer competitive performance with popular proprietary LLMs, such as ChatGPT, indicating opportunities for their responsible use in educational settings.
Exploring the Responses of Large Language Models to Beginner Programmers' Help Requests
Jun 09, 2023



Background and Context: Over the past year, large language models (LLMs) have taken the world by storm. In computing education, like in other walks of life, many opportunities and threats have emerged as a consequence. Objectives: In this article, we explore such opportunities and threats in a specific area: responding to student programmers' help requests. More specifically, we assess how good LLMs are at identifying issues in problematic code that students request help on. Method: We collected a sample of help requests and code from an online programming course. We then prompted two different LLMs (OpenAI Codex and GPT-3.5) to identify and explain the issues in the students' code and assessed the LLM-generated answers both quantitatively and qualitatively. Findings: GPT-3.5 outperforms Codex in most respects. Both LLMs frequently find at least one actual issue in each student program (GPT-3.5 in 90% of the cases). Neither LLM excels at finding all the issues (GPT-3.5 finding them 57% of the time). False positives are common (40% chance for GPT-3.5). The advice that the LLMs provide on the issues is often sensible. The LLMs perform better on issues involving program logic rather than on output formatting. Model solutions are frequently provided even when the LLM is prompted not to. LLM responses to prompts in a non-English language are only slightly worse than responses to English prompts. Implications: Our results continue to highlight the utility of LLMs in programming education. At the same time, the results highlight the unreliability of LLMs: LLMs make some of the same mistakes that students do, perhaps especially when formatting output as required by automated assessment systems. Our study informs teachers interested in using LLMs as well as future efforts to customize LLMs for the needs of programming education.