 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Improve Educational Diagram Generation with In-Context Examples? Not if a Hallucination Spoils the Bunch
Jan 28, 2026Generative artificial intelligence (AI) has found a widespread use in computing education; at the same time, quality of generated materials raises concerns among educators and students. This study addresses this issue by introducing a novel method for diagram code generation with in-context examples based on the Rhetorical Structure Theory (RST), which aims to improve diagram generation by aligning models' output with user expectations. Our approach is evaluated by computer science educators, who assessed 150 diagrams generated with large language models (LLMs) for logical organization, connectivity, layout aesthetic, and AI hallucination. The assessment dataset is additionally investigated for its utility in automated diagram evaluation. The preliminary results suggest that our method decreases the rate of factual hallucination and improves diagram faithfulness to provided context; however, due to LLMs' stochasticity, the quality of the generated diagrams varies. Additionally, we present an in-depth analysis and discussion on the connection between AI hallucination and the quality of generated diagrams, which reveals that text contexts of higher complexity lead to higher rates of hallucination and LLMs often fail to detect mistakes in their output.
Exploring the Responses of Large Language Models to Beginner Programmers' Help Requests
Jun 09, 2023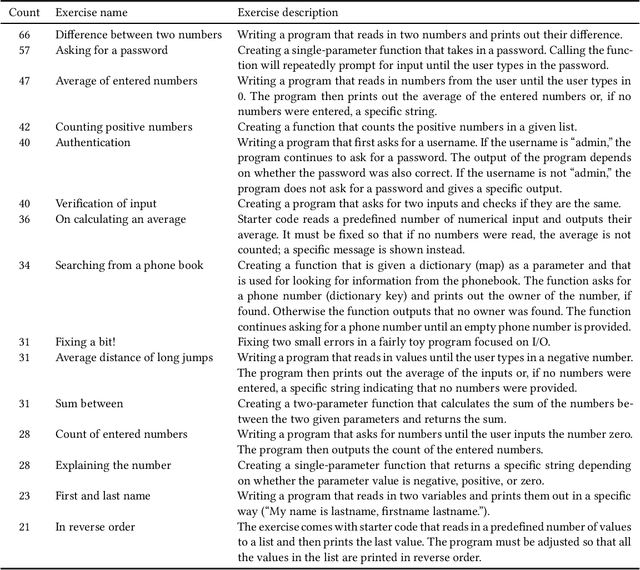



Background and Context: Over the past year, large language models (LLMs) have taken the world by storm. In computing education, like in other walks of life, many opportunities and threats have emerged as a consequence. Objectives: In this article, we explore such opportunities and threats in a specific area: responding to student programmers' help requests. More specifically, we assess how good LLMs are at identifying issues in problematic code that students request help on. Method: We collected a sample of help requests and code from an online programming course. We then prompted two different LLMs (OpenAI Codex and GPT-3.5) to identify and explain the issues in the students' code and assessed the LLM-generated answers both quantitatively and qualitatively. Findings: GPT-3.5 outperforms Codex in most respects. Both LLMs frequently find at least one actual issue in each student program (GPT-3.5 in 90% of the cases). Neither LLM excels at finding all the issues (GPT-3.5 finding them 57% of the time). False positives are common (40% chance for GPT-3.5). The advice that the LLMs provide on the issues is often sensible. The LLMs perform better on issues involving program logic rather than on output formatting. Model solutions are frequently provided even when the LLM is prompted not to. LLM responses to prompts in a non-English language are only slightly worse than responses to English prompts. Implications: Our results continue to highlight the utility of LLMs in programming education. At the same time, the results highlight the unreliability of LLMs: LLMs make some of the same mistakes that students do, perhaps especially when formatting output as required by automated assessment systems. Our study informs teachers interested in using LLMs as well as future efforts to customize LLMs for the needs of programming education.