 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs to Discover Legal Factors
Oct 10, 2024



Factors are a foundational component of legal analysis and computational models of legal reasoning. These factor-based representations enable lawyers, judges, and AI and Law researchers to reason about legal cases. In this paper, we introduce a methodology that leverages large language models (LLMs) to discover lists of factors that effectively represent a legal domain. Our method takes as input raw court opinions and produces a set of factors and associated definitions. We demonstrate that a semi-automated approach, incorporating minimal human involvement, produces factor representations that can predict case outcomes with moderate success, if not yet as well as expert-defined factors can.
Question-Answering Approach to Evaluate Legal Summaries
Sep 26, 2023Traditional evaluation metrics like ROUGE compare lexical overlap between the reference and generated summaries without taking argumentative structure into account, which is important for legal summaries. In this paper, we propose a novel legal summarization evaluation framework that utilizes GPT-4 to generate a set of question-answer pairs that cover main points and information in the reference summary. GPT-4 is then used to generate answers based on the generated summary for the questions from the reference summary. Finally, GPT-4 grades the answers from the reference summary and the generated summary. We examined the correlation between GPT-4 grading with human grading. The results suggest that this question-answering approach with GPT-4 can be a useful tool for gauging the quality of the summary.
Argumentative Segmentation Enhancement for Legal Summarization
Jul 11, 2023We use the combination of argumentative zoning [1] and a legal argumentative scheme to create legal argumentative segments. Based on the argumentative segmentation, we propose a novel task of classifying argumentative segments of legal case decisions. GPT-3.5 is used to generate summaries based on argumentative segments. In terms of automatic evaluation metrics, our method generates higher quality argumentative summaries while leaving out less relevant context as compared to GPT-4 and non-GPT models.
Multi-granularity Argument Mining in Legal Texts
Oct 19, 2022
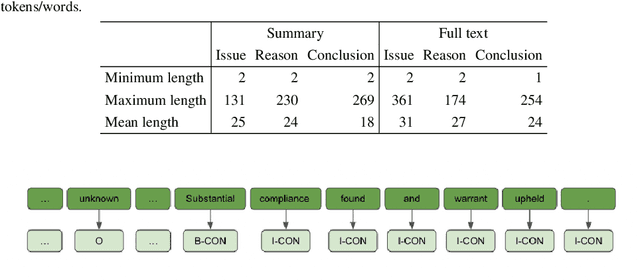
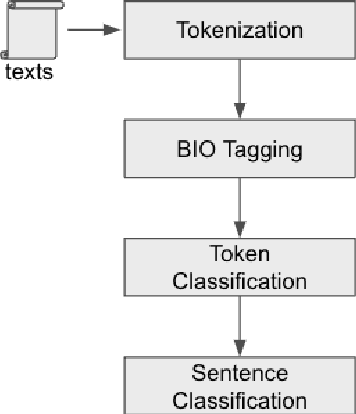
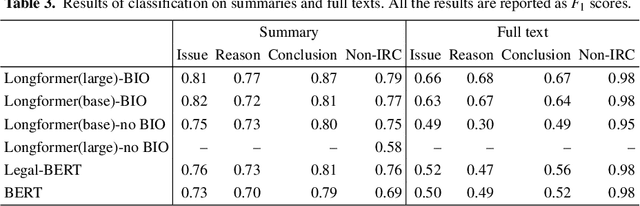
In this paper, we explore legal argument mining using multiple levels of granularity. Argument mining has usually been conceptualized as a sentence classification problem. In this work, we conceptualize argument mining as a token-level (i.e., word-level) classification problem. We use a Longformer model to classify the tokens. Results show that token-level text classification identifies certain legal argument elements more accurately than sentence-level text classification. Token-level classification also provides greater flexibility to analyze legal texts and to gain more insight into what the model focuses on when processing a large amount of input data.