 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
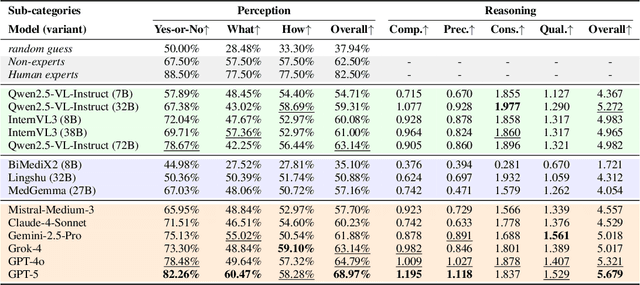
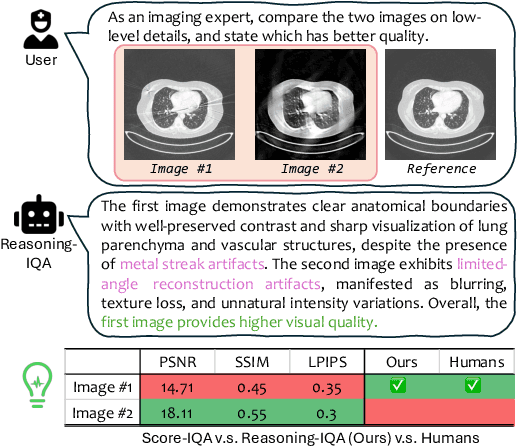

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
EventRR: Event Referential Reasoning for Referring Video Object Segmentation
Aug 10, 2025Referring Video Object Segmentation (RVOS) aims to segment out the object in a video referred by an expression. Current RVOS methods view referring expressions as unstructured sequences, neglecting their crucial semantic structure essential for referent reasoning. Besides, in contrast to image-referring expressions whose semantics focus only on object attributes and object-object relations, video-referring expressions also encompass event attributes and event-event temporal relations. This complexity challenges traditional structured reasoning image approaches. In this paper, we propose the Event Referential Reasoning (EventRR) framework. EventRR decouples RVOS into object summarization part and referent reasoning part. The summarization phase begins by summarizing each frame into a set of bottleneck tokens, which are then efficiently aggregated in the video-level summarization step to exchange the global cross-modal temporal context. For reasoning part, EventRR extracts semantic eventful structure of a video-referring expression into highly expressive Referential Event Graph (REG), which is a single-rooted directed acyclic graph. Guided by topological traversal of REG, we propose Temporal Concept-Role Reasoning (TCRR) to accumulate the referring score of each temporal query from REG leaf nodes to root node. Each reasoning step can be interpreted as a question-answer pair derived from the concept-role relations in REG. Extensive experiments across four widely recognized benchmark datasets, show that EventRR quantitatively and qualitatively outperforms state-of-the-art RVOS methods. Code is available at https://github.com/bio-mlhui/EventRR
S2-UniSeg: Fast Universal Agglomerative Pooling for Scalable Segment Anything without Supervision
Aug 09, 2025Recent self-supervised image segmentation models have achieved promising performance on semantic segmentation and class-agnostic instance segmentation. However, their pretraining schedule is multi-stage, requiring a time-consuming pseudo-masks generation process between each training epoch. This time-consuming offline process not only makes it difficult to scale with training dataset size, but also leads to sub-optimal solutions due to its discontinuous optimization routine. To solve these, we first present a novel pseudo-mask algorithm, Fast Universal Agglomerative Pooling (UniAP). Each layer of UniAP can identify groups of similar nodes in parallel, allowing to generate both semantic-level and instance-level and multi-granular pseudo-masks within ens of milliseconds for one image. Based on the fast UniAP, we propose the Scalable Self-Supervised Universal Segmentation (S2-UniSeg), which employs a student and a momentum teacher for continuous pretraining. A novel segmentation-oriented pretext task, Query-wise Self-Distillation (QuerySD), is proposed to pretrain S2-UniSeg to learn the local-to-global correspondences. Under the same setting, S2-UniSeg outperforms the SOTA UnSAM model, achieving notable improvements of AP+6.9 on COCO, AR+11.1 on UVO, PixelAcc+4.5 on COCOStuff-27, RQ+8.0 on Cityscapes. After scaling up to a larger 2M-image subset of SA-1B, S2-UniSeg further achieves performance gains on all four benchmarks. Our code and pretrained models are available at https://github.com/bio-mlhui/S2-UniSeg
Serp-Mamba: Advancing High-Resolution Retinal Vessel Segmentation with Selective State-Space Model
Sep 06, 2024



Ultra-Wide-Field Scanning Laser Ophthalmoscopy (UWF-SLO) images capture high-resolution views of the retina with typically 200 spanning degrees. Accurate segmentation of vessels in UWF-SLO images is essential for detecting and diagnosing fundus disease. Recent studies have revealed that the selective State Space Model (SSM) in Mamba performs well in modeling long-range dependencies, which is crucial for capturing the continuity of elongated vessel structures. Inspired by this, we propose the first Serpentine Mamba (Serp-Mamba) network to address this challenging task. Specifically, we recognize the intricate, varied, and delicate nature of the tubular structure of vessels. Furthermore, the high-resolution of UWF-SLO images exacerbates the imbalance between the vessel and background categories. Based on the above observations, we first devise a Serpentine Interwoven Adaptive (SIA) scan mechanism, which scans UWF-SLO images along curved vessel structures in a snake-like crawling manner. This approach, consistent with vascular texture transformations, ensures the effective and continuous capture of curved vascular structure features. Second, we propose an Ambiguity-Driven Dual Recalibration (ADDR) module to address the category imbalance problem intensified by high-resolution images. Our ADDR module delineates pixels by two learnable thresholds and refines ambiguous pixels through a dual-driven strategy, thereby accurately distinguishing vessels and background regions. Experiment results on three datasets demonstrate the superior performance of our Serp-Mamba on high-resolution vessel segmentation. We also conduct a series of ablation studies to verify the impact of our designs. Our code shall be released upon publication of this work.
Language-Driven Interactive Shadow Detection
Aug 16, 2024Traditional shadow detectors often identify all shadow regions of static images or video sequences. This work presents the Referring Video Shadow Detection (RVSD), which is an innovative task that rejuvenates the classic paradigm by facilitating the segmentation of particular shadows in videos based on descriptive natural language prompts. This novel RVSD not only achieves segmentation of arbitrary shadow areas of interest based on descriptions (flexibility) but also allows users to interact with visual content more directly and naturally by using natural language prompts (interactivity), paving the way for abundant applications ranging from advanced video editing to virtual reality experiences. To pioneer the RVSD research, we curated a well-annotated RVSD dataset, which encompasses 86 videos and a rich set of 15,011 paired textual descriptions with corresponding shadows. To the best of our knowledge, this dataset is the first one for addressing RVSD. Based on this dataset, we propose a Referring Shadow-Track Memory Network (RSM-Net) for addressing the RVSD task. In our RSM-Net, we devise a Twin-Track Synergistic Memory (TSM) to store intra-clip memory features and hierarchical inter-clip memory features, and then pass these memory features into a memory read module to refine features of the current video frame for referring shadow detection. We also develop a Mixed-Prior Shadow Attention (MSA) to utilize physical priors to obtain a coarse shadow map for learning more visual features by weighting it with the input video frame. Experimental results show that our RSM-Net achieves state-of-the-art performance for RVSD with a notable Overall IOU increase of 4.4\%. Our code and dataset are available at https://github.com/whq-xxh/RVSD.
RainMamba: Enhanced Locality Learning with State Space Models for Video Deraining
Jul 31, 2024



The outdoor vision systems are frequently contaminated by rain streaks and raindrops, which significantly degenerate the performance of visual tasks and multimedia applications. The nature of videos exhibits redundant temporal cues for rain removal with higher stability. Traditional video deraining methods heavily rely on optical flow estimation and kernel-based manners, which have a limited receptive field. Yet, transformer architectures, while enabling long-term dependencies, bring about a significant increase in computational complexity. Recently, the linear-complexity operator of the state space models (SSMs) has contrarily facilitated efficient long-term temporal modeling, which is crucial for rain streaks and raindrops removal in videos. Unexpectedly, its uni-dimensional sequential process on videos destroys the local correlations across the spatio-temporal dimension by distancing adjacent pixels. To address this, we present an improved SSMs-based video deraining network (RainMamba) with a novel Hilbert scanning mechanism to better capture sequence-level local information. We also introduce a difference-guided dynamic contrastive locality learning strategy to enhance the patch-level self-similarity learning ability of the proposed network. Extensive experiments on four synthesized video deraining datasets and real-world rainy videos demonstrate the superiority of our network in the removal of rain streaks and raindrops.
LGRNet: Local-Global Reciprocal Network for Uterine Fibroid Segmentation in Ultrasound Videos
Jul 08, 2024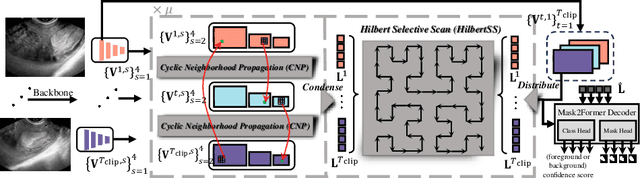
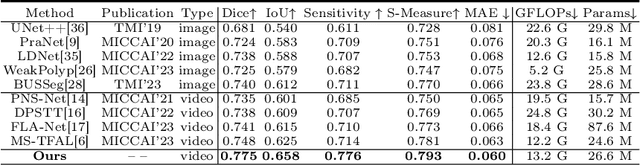
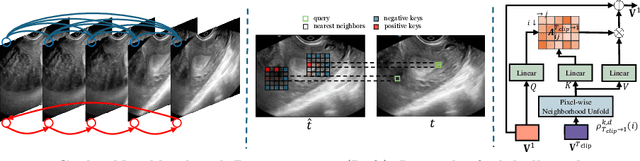

Regular screening and early discovery of uterine fibroid are crucial for preventing potential malignant transformations and ensuring timely, life-saving interventions. To this end, we collect and annotate the first ultrasound video dataset with 100 videos for uterine fibroid segmentation (UFUV). We also present Local-Global Reciprocal Network (LGRNet) to efficiently and effectively propagate the long-term temporal context which is crucial to help distinguish between uninformative noisy surrounding tissues and target lesion regions. Specifically, the Cyclic Neighborhood Propagation (CNP) is introduced to propagate the inter-frame local temporal context in a cyclic manner. Moreover, to aggregate global temporal context, we first condense each frame into a set of frame bottleneck queries and devise Hilbert Selective Scan (HilbertSS) to both efficiently path connect each frame and preserve the locality bias. A distribute layer is then utilized to disseminate back the global context for reciprocal refinement. Extensive experiments on UFUV and three public Video Polyp Segmentation (VPS) datasets demonstrate consistent improvements compared to state-of-the-art segmentation methods, indicating the effectiveness and versatility of LGRNet. Code, checkpoints, and dataset are available at https://github.com/bio-mlhui/LGRNet
Question-Answering Approach to Evaluate Legal Summaries
Sep 26, 2023Traditional evaluation metrics like ROUGE compare lexical overlap between the reference and generated summaries without taking argumentative structure into account, which is important for legal summaries. In this paper, we propose a novel legal summarization evaluation framework that utilizes GPT-4 to generate a set of question-answer pairs that cover main points and information in the reference summary. GPT-4 is then used to generate answers based on the generated summary for the questions from the reference summary. Finally, GPT-4 grades the answers from the reference summary and the generated summary. We examined the correlation between GPT-4 grading with human grading. The results suggest that this question-answering approach with GPT-4 can be a useful tool for gauging the quality of the summary.