 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Real-World High-Precision Image Matting and Segmentation
Jan 17, 2026High-precision scene parsing tasks, including image matting and dichotomous segmentation, aim to accurately predict masks with extremely fine details (such as hair). Most existing methods focus on salient, single foreground objects. While interactive methods allow for target adjustment, their class-agnostic design restricts generalization across different categories. Furthermore, the scarcity of high-quality annotation has led to a reliance on inharmonious synthetic data, resulting in poor generalization to real-world scenarios. To this end, we propose a Foreground Consistent Learning model, dubbed as FCLM, to address the aforementioned issues. Specifically, we first introduce a Depth-Aware Distillation strategy where we transfer the depth-related knowledge for better foreground representation. Considering the data dilemma, we term the processing of synthetic data as domain adaptation problem where we propose a domain-invariant learning strategy to focus on foreground learning. To support interactive prediction, we contribute an Object-Oriented Decoder that can receive both visual and language prompts to predict the referring target. Experimental results show that our method quantitatively and qualitatively outperforms SOTA methods.
K-Stain: Keypoint-Driven Correspondence for H&E-to-IHC Virtual Staining
Nov 10, 2025Virtual staining offers a promising method for converting Hematoxylin and Eosin (H&E) images into Immunohistochemical (IHC) images, eliminating the need for costly chemical processes. However, existing methods often struggle to utilize spatial information effectively due to misalignment in tissue slices. To overcome this challenge, we leverage keypoints as robust indicators of spatial correspondence, enabling more precise alignment and integration of structural details in synthesized IHC images. We introduce K-Stain, a novel framework that employs keypoint-based spatial and semantic relationships to enhance synthesized IHC image fidelity. K-Stain comprises three main components: (1) a Hierarchical Spatial Keypoint Detector (HSKD) for identifying keypoints in stain images, (2) a Keypoint-aware Enhancement Generator (KEG) that integrates these keypoints during image generation, and (3) a Keypoint Guided Discriminator (KGD) that improves the discriminator's sensitivity to spatial details. Our approach leverages contextual information from adjacent slices, resulting in more accurate and visually consistent IHC images. Extensive experiments show that K-Stain outperforms state-of-the-art methods in quantitative metrics and visual quality.
HRVVS: A High-resolution Video Vasculature Segmentation Network via Hierarchical Autoregressive Residual Priors
Jul 30, 2025



The segmentation of the hepatic vasculature in surgical videos holds substantial clinical significance in the context of hepatectomy procedures. However, owing to the dearth of an appropriate dataset and the inherently complex task characteristics, few researches have been reported in this domain. To address this issue, we first introduce a high quality frame-by-frame annotated hepatic vasculature dataset containing 35 long hepatectomy videos and 11442 high-resolution frames. On this basis, we propose a novel high-resolution video vasculature segmentation network, dubbed as HRVVS. We innovatively embed a pretrained visual autoregressive modeling (VAR) model into different layers of the hierarchical encoder as prior information to reduce the information degradation generated during the downsampling process. In addition, we designed a dynamic memory decoder on a multi-view segmentation network to minimize the transmission of redundant information while preserving more details between frames. Extensive experiments on surgical video datasets demonstrate that our proposed HRVVS significantly outperforms the state-of-the-art methods. The source code and dataset will be publicly available at \href{https://github.com/scott-yjyang/xx}{https://github.com/scott-yjyang/HRVVS}.
Timeline and Boundary Guided Diffusion Network for Video Shadow Detection
Aug 21, 2024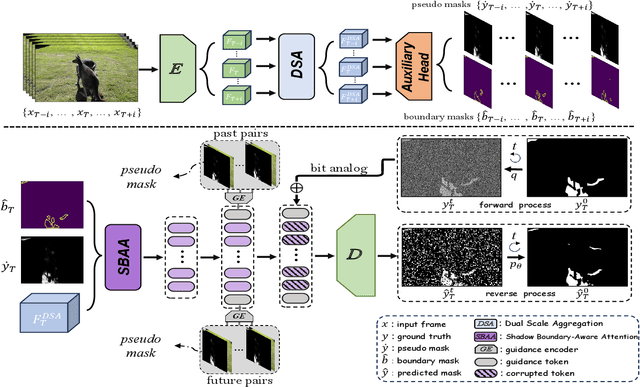



Video Shadow Detection (VSD) aims to detect the shadow masks with frame sequence. Existing works suffer from inefficient temporal learning. Moreover, few works address the VSD problem by considering the characteristic (i.e., boundary) of shadow. Motivated by this, we propose a Timeline and Boundary Guided Diffusion (TBGDiff) network for VSD where we take account of the past-future temporal guidance and boundary information jointly. In detail, we design a Dual Scale Aggregation (DSA) module for better temporal understanding by rethinking the affinity of the long-term and short-term frames for the clipped video. Next, we introduce Shadow Boundary Aware Attention (SBAA) to utilize the edge contexts for capturing the characteristics of shadows. Moreover, we are the first to introduce the Diffusion model for VSD in which we explore a Space-Time Encoded Embedding (STEE) to inject the temporal guidance for Diffusion to conduct shadow detection. Benefiting from these designs, our model can not only capture the temporal information but also the shadow property. Extensive experiments show that the performance of our approach overtakes the state-of-the-art methods, verifying the effectiveness of our components. We release the codes, weights, and results at \url{https://github.com/haipengzhou856/TBGDiff}.
Language-Driven Interactive Shadow Detection
Aug 16, 2024Traditional shadow detectors often identify all shadow regions of static images or video sequences. This work presents the Referring Video Shadow Detection (RVSD), which is an innovative task that rejuvenates the classic paradigm by facilitating the segmentation of particular shadows in videos based on descriptive natural language prompts. This novel RVSD not only achieves segmentation of arbitrary shadow areas of interest based on descriptions (flexibility) but also allows users to interact with visual content more directly and naturally by using natural language prompts (interactivity), paving the way for abundant applications ranging from advanced video editing to virtual reality experiences. To pioneer the RVSD research, we curated a well-annotated RVSD dataset, which encompasses 86 videos and a rich set of 15,011 paired textual descriptions with corresponding shadows. To the best of our knowledge, this dataset is the first one for addressing RVSD. Based on this dataset, we propose a Referring Shadow-Track Memory Network (RSM-Net) for addressing the RVSD task. In our RSM-Net, we devise a Twin-Track Synergistic Memory (TSM) to store intra-clip memory features and hierarchical inter-clip memory features, and then pass these memory features into a memory read module to refine features of the current video frame for referring shadow detection. We also develop a Mixed-Prior Shadow Attention (MSA) to utilize physical priors to obtain a coarse shadow map for learning more visual features by weighting it with the input video frame. Experimental results show that our RSM-Net achieves state-of-the-art performance for RVSD with a notable Overall IOU increase of 4.4\%. Our code and dataset are available at https://github.com/whq-xxh/RVSD.
Distribution Aligned Diffusion and Prototype-guided network for Unsupervised Domain Adaptive Segmentation
Mar 28, 2023The Diffusion Probabilistic Model (DPM) has emerged as a highly effective generative model in the field of computer vision. Its intermediate latent vectors offer rich semantic information, making it an attractive option for various downstream tasks such as segmentation and detection. In order to explore its potential further, we have taken a step forward and considered a more complex scenario in the medical image domain, specifically, under an unsupervised adaptation condition. To this end, we propose a Diffusion-based and Prototype-guided network (DP-Net) for unsupervised domain adaptive segmentation. Concretely, our DP-Net consists of two stages: 1) Distribution Aligned Diffusion (DADiff), which involves training a domain discriminator to minimize the difference between the intermediate features generated by the DPM, thereby aligning the inter-domain distribution; and 2) Prototype-guided Consistency Learning (PCL), which utilizes feature centroids as prototypes and applies a prototype-guided loss to ensure that the segmentor learns consistent content from both source and target domains. Our approach is evaluated on fundus datasets through a series of experiments, which demonstrate that the performance of the proposed method is reliable and outperforms state-of-the-art methods. Our work presents a promising direction for using DPM in complex medical image scenarios, opening up new possibilities for further research in medical imaging.