 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegRap2025: A Benchmark of Gross Tumor Volume and Lymph Node Clinical Target Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Jan 28, 2026Accurate delineation of Gross Tumor Volume (GTV), Lymph Node Clinical Target Volume (LN CTV), and Organ-at-Risk (OAR) from Computed Tomography (CT) scans is essential for precise radiotherapy planning in Nasopharyngeal Carcinoma (NPC). Building upon SegRap2023, which focused on OAR and GTV segmentation using single-center paired non-contrast CT (ncCT) and contrast-enhanced CT (ceCT) scans, the SegRap2025 challenge aims to enhance the generalizability and robustness of segmentation models across imaging centers and modalities. SegRap2025 comprises two tasks: Task01 addresses GTV segmentation using paired CT from the SegRap2023 dataset, with an additional external testing set to evaluate cross-center generalization, and Task02 focuses on LN CTV segmentation using multi-center training data and an unseen external testing set, where each case contains paired CT scans or a single modality, emphasizing both cross-center and cross-modality robustness. This paper presents the challenge setup and provides a comprehensive analysis of the solutions submitted by ten participating teams. For GTV segmentation task, the top-performing models achieved average Dice Similarity Coefficient (DSC) of 74.61% and 56.79% on the internal and external testing cohorts, respectively. For LN CTV segmentation task, the highest average DSC values reached 60.24%, 60.50%, and 57.23% on paired CT, ceCT-only, and ncCT-only subsets, respectively. SegRap2025 establishes a large-scale multi-center, multi-modality benchmark for evaluating the generalization and robustness in radiotherapy target segmentation, providing valuable insights toward clinically applicable automated radiotherapy planning systems. The benchmark is available at: https://hilab-git.github.io/SegRap2025_Challenge.
Toward Real-World High-Precision Image Matting and Segmentation
Jan 17, 2026High-precision scene parsing tasks, including image matting and dichotomous segmentation, aim to accurately predict masks with extremely fine details (such as hair). Most existing methods focus on salient, single foreground objects. While interactive methods allow for target adjustment, their class-agnostic design restricts generalization across different categories. Furthermore, the scarcity of high-quality annotation has led to a reliance on inharmonious synthetic data, resulting in poor generalization to real-world scenarios. To this end, we propose a Foreground Consistent Learning model, dubbed as FCLM, to address the aforementioned issues. Specifically, we first introduce a Depth-Aware Distillation strategy where we transfer the depth-related knowledge for better foreground representation. Considering the data dilemma, we term the processing of synthetic data as domain adaptation problem where we propose a domain-invariant learning strategy to focus on foreground learning. To support interactive prediction, we contribute an Object-Oriented Decoder that can receive both visual and language prompts to predict the referring target. Experimental results show that our method quantitatively and qualitatively outperforms SOTA methods.
More than Segmentation: Benchmarking SAM 3 for Segmentation, 3D Perception, and Reconstruction in Robotic Surgery
Dec 10, 2025The recent SAM 3 and SAM 3D have introduced significant advancements over the predecessor, SAM 2, particularly with the integration of language-based segmentation and enhanced 3D perception capabilities. SAM 3 supports zero-shot segmentation across a wide range of prompts, including point, bounding box, and language-based prompts, allowing for more flexible and intuitive interactions with the model. In this empirical evaluation, we assess the performance of SAM 3 in robot-assisted surgery, benchmarking its zero-shot segmentation with point and bounding box prompts and exploring its effectiveness in dynamic video tracking, alongside its newly introduced language prompt segmentation. While language prompts show potential, their performance in the surgical domain is currently suboptimal, highlighting the need for further domain-specific training. Additionally, we investigate SAM 3D's depth reconstruction abilities, demonstrating its capacity to process surgical scene data and reconstruct 3D anatomical structures from 2D images. Through comprehensive testing on the MICCAI EndoVis 2017 and EndoVis 2018 benchmarks, SAM 3 shows clear improvements over SAM and SAM 2 in both image and video segmentation under spatial prompts, while the zero-shot evaluations of SAM 3D on SCARED, StereoMIS, and EndoNeRF indicate strong monocular depth estimation and realistic 3D instrument reconstruction, yet also reveal remaining limitations in complex, highly dynamic surgical scenes.
Toward Medical Deepfake Detection: A Comprehensive Dataset and Novel Method
Sep 19, 2025The rapid advancement of generative AI in medical imaging has introduced both significant opportunities and serious challenges, especially the risk that fake medical images could undermine healthcare systems. These synthetic images pose serious risks, such as diagnostic deception, financial fraud, and misinformation. However, research on medical forensics to counter these threats remains limited, and there is a critical lack of comprehensive datasets specifically tailored for this field. Additionally, existing media forensic methods, which are primarily designed for natural or facial images, are inadequate for capturing the distinct characteristics and subtle artifacts of AI-generated medical images. To tackle these challenges, we introduce \textbf{MedForensics}, a large-scale medical forensics dataset encompassing six medical modalities and twelve state-of-the-art medical generative models. We also propose \textbf{DSKI}, a novel \textbf{D}ual-\textbf{S}tage \textbf{K}nowledge \textbf{I}nfusing detector that constructs a vision-language feature space tailored for the detection of AI-generated medical images. DSKI comprises two core components: 1) a cross-domain fine-trace adapter (CDFA) for extracting subtle forgery clues from both spatial and noise domains during training, and 2) a medical forensic retrieval module (MFRM) that boosts detection accuracy through few-shot retrieval during testing. Experimental results demonstrate that DSKI significantly outperforms both existing methods and human experts, achieving superior accuracy across multiple medical modalities.
S2-UniSeg: Fast Universal Agglomerative Pooling for Scalable Segment Anything without Supervision
Aug 09, 2025Recent self-supervised image segmentation models have achieved promising performance on semantic segmentation and class-agnostic instance segmentation. However, their pretraining schedule is multi-stage, requiring a time-consuming pseudo-masks generation process between each training epoch. This time-consuming offline process not only makes it difficult to scale with training dataset size, but also leads to sub-optimal solutions due to its discontinuous optimization routine. To solve these, we first present a novel pseudo-mask algorithm, Fast Universal Agglomerative Pooling (UniAP). Each layer of UniAP can identify groups of similar nodes in parallel, allowing to generate both semantic-level and instance-level and multi-granular pseudo-masks within ens of milliseconds for one image. Based on the fast UniAP, we propose the Scalable Self-Supervised Universal Segmentation (S2-UniSeg), which employs a student and a momentum teacher for continuous pretraining. A novel segmentation-oriented pretext task, Query-wise Self-Distillation (QuerySD), is proposed to pretrain S2-UniSeg to learn the local-to-global correspondences. Under the same setting, S2-UniSeg outperforms the SOTA UnSAM model, achieving notable improvements of AP+6.9 on COCO, AR+11.1 on UVO, PixelAcc+4.5 on COCOStuff-27, RQ+8.0 on Cityscapes. After scaling up to a larger 2M-image subset of SA-1B, S2-UniSeg further achieves performance gains on all four benchmarks. Our code and pretrained models are available at https://github.com/bio-mlhui/S2-UniSeg
Surgery-R1: Advancing Surgical-VQLA with Reasoning Multimodal Large Language Model via Reinforcement Learning
Jun 24, 2025In recent years, significant progress has been made in the field of surgical scene understanding, particularly in the task of Visual Question Localized-Answering in robotic surgery (Surgical-VQLA). However, existing Surgical-VQLA models lack deep reasoning capabilities and interpretability in surgical scenes, which limits their reliability and potential for development in clinical applications. To address this issue, inspired by the development of Reasoning Multimodal Large Language Models (MLLMs), we first build the Surgery-R1-54k dataset, including paired data for Visual-QA, Grounding-QA, and Chain-of-Thought (CoT). Then, we propose the first Reasoning MLLM for Surgical-VQLA (Surgery-R1). In our Surgery-R1, we design a two-stage fine-tuning mechanism to enable the basic MLLM with complex reasoning abilities by utilizing supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). Furthermore, for an efficient and high-quality rule-based reward system in our RFT, we design a Multimodal Coherence reward mechanism to mitigate positional illusions that may arise in surgical scenarios. Experiment results demonstrate that Surgery-R1 outperforms other existing state-of-the-art (SOTA) models in the Surgical-VQLA task and widely-used MLLMs, while also validating its reasoning capabilities and the effectiveness of our approach. The code and dataset will be organized in https://github.com/FiFi-HAO467/Surgery-R1.
Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Dec 17, 2024Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
Automated 3D Physical Simulation of Open-world Scene with Gaussian Splatting
Nov 19, 2024
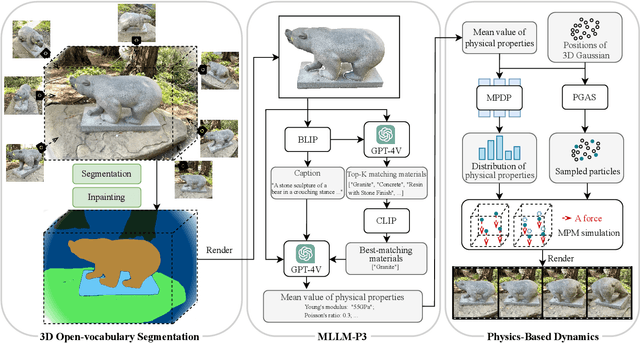
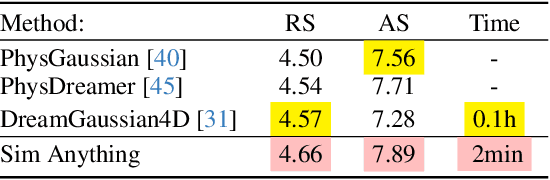
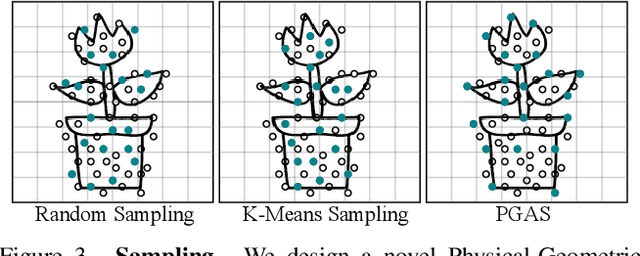
Recent advancements in 3D generation models have opened new possibilities for simulating dynamic 3D object movements and customizing behaviors, yet creating this content remains challenging. Current methods often require manual assignment of precise physical properties for simulations or rely on video generation models to predict them, which is computationally intensive. In this paper, we rethink the usage of multi-modal large language model (MLLM) in physics-based simulation, and present Sim Anything, a physics-based approach that endows static 3D objects with interactive dynamics. We begin with detailed scene reconstruction and object-level 3D open-vocabulary segmentation, progressing to multi-view image in-painting. Inspired by human visual reasoning, we propose MLLM-based Physical Property Perception (MLLM-P3) to predict mean physical properties of objects in a zero-shot manner. Based on the mean values and the object's geometry, the Material Property Distribution Prediction model (MPDP) model then estimates the full distribution, reformulating the problem as probability distribution estimation to reduce computational costs. Finally, we simulate objects in an open-world scene with particles sampled via the Physical-Geometric Adaptive Sampling (PGAS) strategy, efficiently capturing complex deformations and significantly reducing computational costs. Extensive experiments and user studies demonstrate our Sim Anything achieves more realistic motion than state-of-the-art methods within 2 minutes on a single GPU.
Non-Invasive to Invasive: Enhancing FFA Synthesis from CFP with a Benchmark Dataset and a Novel Network
Oct 19, 2024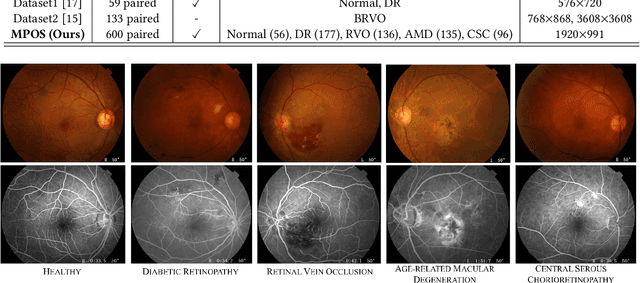
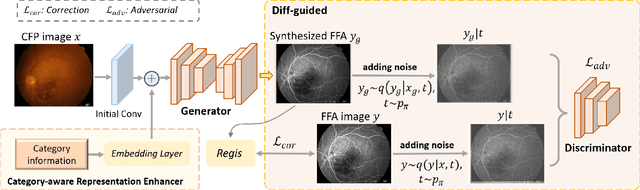
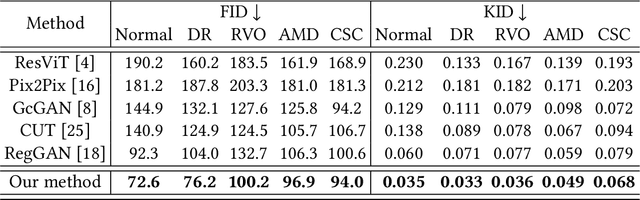
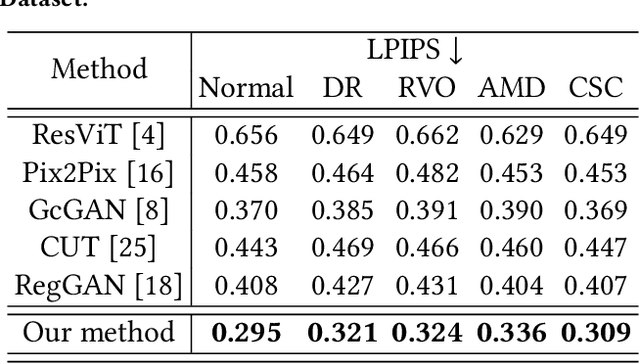
Fundus imaging is a pivotal tool in ophthalmology, and different imaging modalities are characterized by their specific advantages. For example, Fundus Fluorescein Angiography (FFA) uniquely provides detailed insights into retinal vascular dynamics and pathology, surpassing Color Fundus Photographs (CFP) in detecting microvascular abnormalities and perfusion status. However, the conventional invasive FFA involves discomfort and risks due to fluorescein dye injection, and it is meaningful but challenging to synthesize FFA images from non-invasive CFP. Previous studies primarily focused on FFA synthesis in a single disease category. In this work, we explore FFA synthesis in multiple diseases by devising a Diffusion-guided generative adversarial network, which introduces an adaptive and dynamic diffusion forward process into the discriminator and adds a category-aware representation enhancer. Moreover, to facilitate this research, we collect the first multi-disease CFP and FFA paired dataset, named the Multi-disease Paired Ocular Synthesis (MPOS) dataset, with four different fundus diseases. Experimental results show that our FFA synthesis network can generate better FFA images compared to state-of-the-art methods. Furthermore, we introduce a paired-modal diagnostic network to validate the effectiveness of synthetic FFA images in the diagnosis of multiple fundus diseases, and the results show that our synthesized FFA images with the real CFP images have higher diagnosis accuracy than that of the compared FFA synthesizing methods. Our research bridges the gap between non-invasive imaging and FFA, thereby offering promising prospects to enhance ophthalmic diagnosis and patient care, with a focus on reducing harm to patients through non-invasive procedures. Our dataset and code will be released to support further research in this field (https://github.com/whq-xxh/FFA-Synthesis).
Serp-Mamba: Advancing High-Resolution Retinal Vessel Segmentation with Selective State-Space Model
Sep 06, 2024



Ultra-Wide-Field Scanning Laser Ophthalmoscopy (UWF-SLO) images capture high-resolution views of the retina with typically 200 spanning degrees. Accurate segmentation of vessels in UWF-SLO images is essential for detecting and diagnosing fundus disease. Recent studies have revealed that the selective State Space Model (SSM) in Mamba performs well in modeling long-range dependencies, which is crucial for capturing the continuity of elongated vessel structures. Inspired by this, we propose the first Serpentine Mamba (Serp-Mamba) network to address this challenging task. Specifically, we recognize the intricate, varied, and delicate nature of the tubular structure of vessels. Furthermore, the high-resolution of UWF-SLO images exacerbates the imbalance between the vessel and background categories. Based on the above observations, we first devise a Serpentine Interwoven Adaptive (SIA) scan mechanism, which scans UWF-SLO images along curved vessel structures in a snake-like crawling manner. This approach, consistent with vascular texture transformations, ensures the effective and continuous capture of curved vascular structure features. Second, we propose an Ambiguity-Driven Dual Recalibration (ADDR) module to address the category imbalance problem intensified by high-resolution images. Our ADDR module delineates pixels by two learnable thresholds and refines ambiguous pixels through a dual-driven strategy, thereby accurately distinguishing vessels and background regions. Experiment results on three datasets demonstrate the superior performance of our Serp-Mamba on high-resolution vessel segmentation. We also conduct a series of ablation studies to verify the impact of our designs. Our code shall be released upon publication of this work.