 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeinversedMixup: Data Augmentation via Inverting Mixed Embeddings
Jan 29, 2026Mixup generates augmented samples by linearly interpolating inputs and labels with a controllable ratio. However, since it operates in the latent embedding level, the resulting samples are not human-interpretable. In contrast, LLM-based augmentation methods produce sentences via prompts at the token level, yielding readable outputs but offering limited control over the generation process. Inspired by recent advances in LLM inversion, which reconstructs natural language from embeddings and helps bridge the gap between latent embedding space and discrete token space, we propose inversedMixup, a unified framework that combines the controllability of Mixup with the interpretability of LLM-based generation. Specifically, inversedMixup adopts a three-stage training procedure to align the output embedding space of a task-specific model with the input embedding space of an LLM. Upon successful alignment, inversedMixup can reconstruct mixed embeddings with a controllable mixing ratio into human-interpretable augmented sentences, thereby improving the augmentation performance. Additionally, inversedMixup provides the first empirical evidence of the manifold intrusion phenomenon in text Mixup and introduces a simple yet effective strategy to mitigate it. Extensive experiments demonstrate the effectiveness and generalizability of our approach in both few-shot and fully supervised scenarios.
Improving Subgraph Matching by Combining Algorithms and Graph Neural Networks
Jul 27, 2025Homomorphism is a key mapping technique between graphs that preserves their structure. Given a graph and a pattern, the subgraph homomorphism problem involves finding a mapping from the pattern to the graph, ensuring that adjacent vertices in the pattern are mapped to adjacent vertices in the graph. Unlike subgraph isomorphism, which requires a one-to-one mapping, homomorphism allows multiple vertices in the pattern to map to the same vertex in the graph, making it more complex. We propose HFrame, the first graph neural network-based framework for subgraph homomorphism, which integrates traditional algorithms with machine learning techniques. We demonstrate that HFrame outperforms standard graph neural networks by being able to distinguish more graph pairs where the pattern is not homomorphic to the graph. Additionally, we provide a generalization error bound for HFrame. Through experiments on both real-world and synthetic graphs, we show that HFrame is up to 101.91 times faster than exact matching algorithms and achieves an average accuracy of 0.962.
Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Dec 17, 2024Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
DVN-SLAM: Dynamic Visual Neural SLAM Based on Local-Global Encoding
Mar 18, 2024Recent research on Simultaneous Localization and Mapping (SLAM) based on implicit representation has shown promising results in indoor environments. However, there are still some challenges: the limited scene representation capability of implicit encodings, the uncertainty in the rendering process from implicit representations, and the disruption of consistency by dynamic objects. To address these challenges, we propose a real-time dynamic visual SLAM system based on local-global fusion neural implicit representation, named DVN-SLAM. To improve the scene representation capability, we introduce a local-global fusion neural implicit representation that enables the construction of an implicit map while considering both global structure and local details. To tackle uncertainties arising from the rendering process, we design an information concentration loss for optimization, aiming to concentrate scene information on object surfaces. The proposed DVN-SLAM achieves competitive performance in localization and mapping across multiple datasets. More importantly, DVN-SLAM demonstrates robustness in dynamic scenes, a trait that sets it apart from other NeRF-based methods.
DisCo: Distilled Student Models Co-training for Semi-supervised Text Mining
May 20, 2023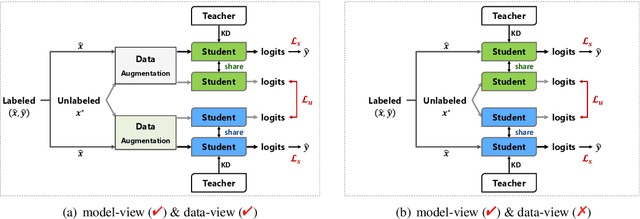


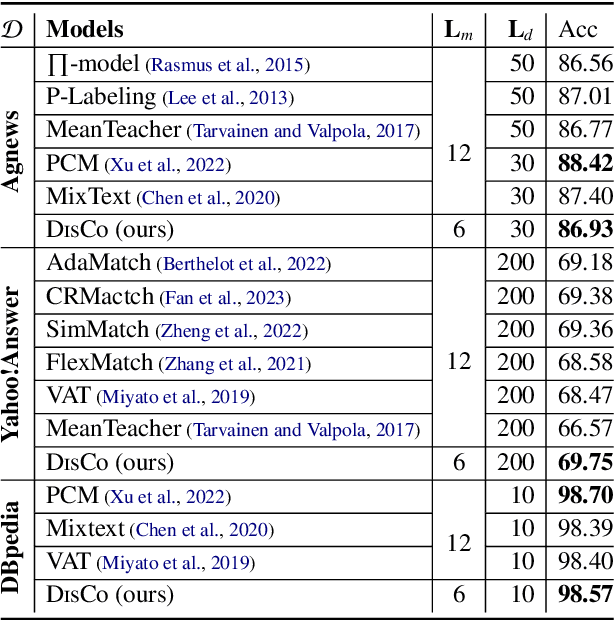
Many text mining models are constructed by fine-tuning a large deep pre-trained language model (PLM) in downstream tasks. However, a significant challenge is maintaining performance when we use a lightweight model with limited labeled samples. We present DisCo, a semi-supervised learning (SSL) framework for fine-tuning a cohort of small student models generated from a large PLM using knowledge distillation. Our key insight is to share complementary knowledge among distilled student cohorts to promote their SSL effectiveness. DisCo employs a novel co-training technique to optimize multiple small student models by promoting knowledge sharing among students under diversified views: model views produced by different distillation strategies and data views produced by various input augmentations. We evaluate DisCo on both semi-supervised text classification and extractive summarization tasks. Experimental results show that DisCo can produce student models that are 7.6 times smaller and 4.8 times faster in inference than the baseline PLMs while maintaining comparable performance. We also show that DisCo-generated student models outperform the similar-sized models elaborately tuned in distinct tasks.