 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCo: Distilled Student Models Co-training for Semi-supervised Text Mining
May 20, 2023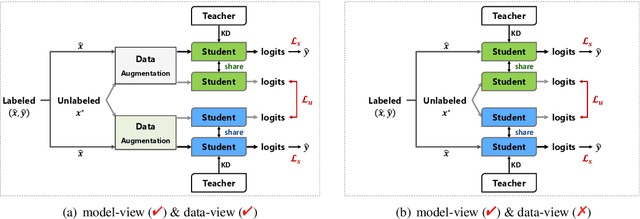


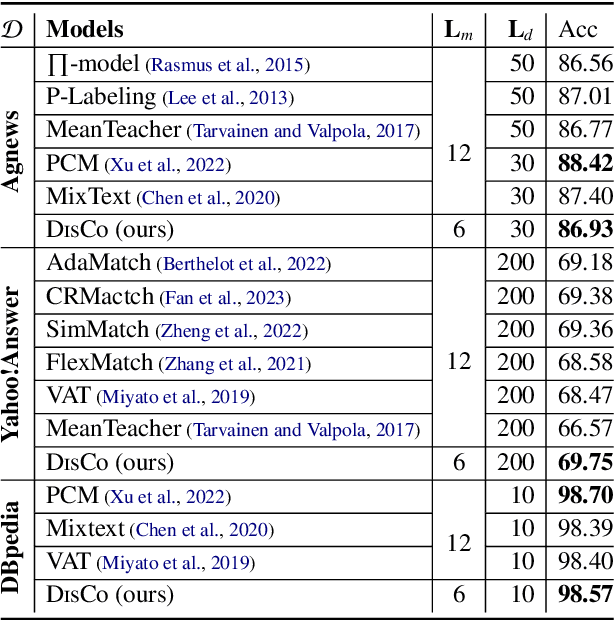
Many text mining models are constructed by fine-tuning a large deep pre-trained language model (PLM) in downstream tasks. However, a significant challenge is maintaining performance when we use a lightweight model with limited labeled samples. We present DisCo, a semi-supervised learning (SSL) framework for fine-tuning a cohort of small student models generated from a large PLM using knowledge distillation. Our key insight is to share complementary knowledge among distilled student cohorts to promote their SSL effectiveness. DisCo employs a novel co-training technique to optimize multiple small student models by promoting knowledge sharing among students under diversified views: model views produced by different distillation strategies and data views produced by various input augmentations. We evaluate DisCo on both semi-supervised text classification and extractive summarization tasks. Experimental results show that DisCo can produce student models that are 7.6 times smaller and 4.8 times faster in inference than the baseline PLMs while maintaining comparable performance. We also show that DisCo-generated student models outperform the similar-sized models elaborately tuned in distinct tasks.