 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoNet: Parameter-Efficient Learning with Label-Scarce Supervision for Lightweight Text Mining Model
Feb 05, 2026The lightweight semi-supervised learning (LSL) strategy provides an effective approach of conserving labeled samples and minimizing model inference costs. Prior research has effectively applied knowledge transfer learning and co-training regularization from large to small models in LSL. However, such training strategies are computationally intensive and prone to local optima, thereby increasing the difficulty of finding the optimal solution. This has prompted us to investigate the feasibility of integrating three low-cost scenarios for text mining tasks: limited labeled supervision, lightweight fine-tuning, and rapid-inference small models. We propose NanoNet, a novel framework for lightweight text mining that implements parameter-efficient learning with limited supervision. It employs online knowledge distillation to generate multiple small models and enhances their performance through mutual learning regularization. The entire process leverages parameter-efficient learning, reducing training costs and minimizing supervision requirements, ultimately yielding a lightweight model for downstream inference.
Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
Dec 29, 2025We propose LLM-PeerReview, an unsupervised LLM Ensemble method that selects the most ideal response from multiple LLM-generated candidates for each query, harnessing the collective wisdom of multiple models with diverse strengths. LLM-PeerReview is built on a novel, peer-review-inspired framework that offers a clear and interpretable mechanism, while remaining fully unsupervised for flexible adaptability and generalization. Specifically, it operates in three stages: For scoring, we use the emerging LLM-as-a-Judge technique to evaluate each response by reusing multiple LLMs at hand; For reasoning, we can apply a principled graphical model-based truth inference algorithm or a straightforward averaging strategy to aggregate multiple scores to produce a final score for each response; Finally, the highest-scoring response is selected as the best ensemble output. LLM-PeerReview is conceptually simple and empirically powerful. The two variants of the proposed approach obtain strong results across four datasets, including outperforming the recent advanced model Smoothie-Global by 6.9% and 7.3% points, respectively.
Privacy-Preserving Federated Embedding Learning for Localized Retrieval-Augmented Generation
Apr 27, 2025Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution for enhancing the accuracy and credibility of Large Language Models (LLMs), particularly in Question & Answer tasks. This is achieved by incorporating proprietary and private data from integrated databases. However, private RAG systems face significant challenges due to the scarcity of private domain data and critical data privacy issues. These obstacles impede the deployment of private RAG systems, as developing privacy-preserving RAG systems requires a delicate balance between data security and data availability. To address these challenges, we regard federated learning (FL) as a highly promising technology for privacy-preserving RAG services. We propose a novel framework called Federated Retrieval-Augmented Generation (FedE4RAG). This framework facilitates collaborative training of client-side RAG retrieval models. The parameters of these models are aggregated and distributed on a central-server, ensuring data privacy without direct sharing of raw data. In FedE4RAG, knowledge distillation is employed for communication between the server and client models. This technique improves the generalization of local RAG retrievers during the federated learning process. Additionally, we apply homomorphic encryption within federated learning to safeguard model parameters and mitigate concerns related to data leakage. Extensive experiments conducted on the real-world dataset have validated the effectiveness of FedE4RAG. The results demonstrate that our proposed framework can markedly enhance the performance of private RAG systems while maintaining robust data privacy protection.
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Feb 25, 2025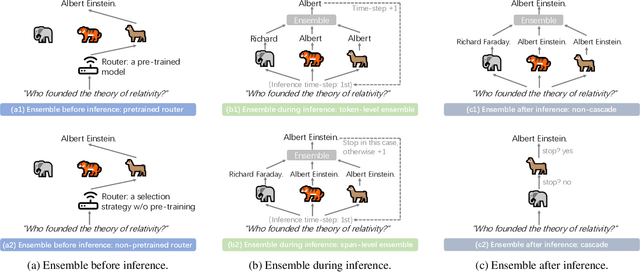
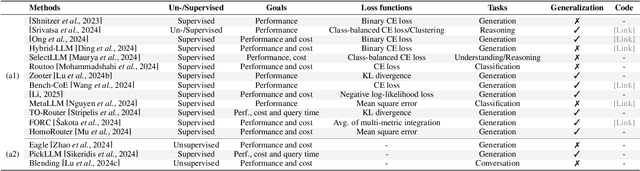
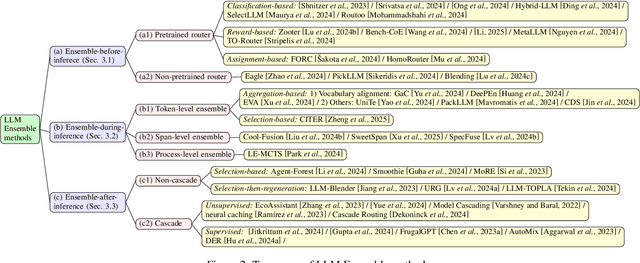
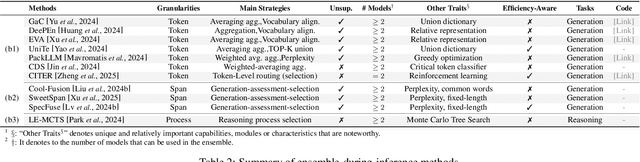
LLM Ensemble -- which involves the comprehensive use of multiple large language models (LLMs), each aimed at handling user queries during downstream inference, to benefit from their individual strengths -- has gained substantial attention recently. The widespread availability of LLMs, coupled with their varying strengths and out-of-the-box usability, has profoundly advanced the field of LLM Ensemble. This paper presents the first systematic review of recent developments in LLM Ensemble. First, we introduce our taxonomy of LLM Ensemble and discuss several related research problems. Then, we provide a more in-depth classification of the methods under the broad categories of "ensemble-before-inference, ensemble-during-inference, ensemble-after-inference", and review all relevant methods. Finally, we introduce related benchmarks and applications, summarize existing studies, and suggest several future research directions. A curated list of papers on LLM Ensemble is available at https://github.com/junchenzhi/Awesome-LLM-Ensemble.
XRAG: eXamining the Core -- Benchmarking Foundational Components in Advanced Retrieval-Augmented Generation
Dec 24, 2024Retrieval-augmented generation (RAG) synergizes the retrieval of pertinent data with the generative capabilities of Large Language Models (LLMs), ensuring that the generated output is not only contextually relevant but also accurate and current. We introduce XRAG, an open-source, modular codebase that facilitates exhaustive evaluation of the performance of foundational components of advanced RAG modules. These components are systematically categorized into four core phases: pre-retrieval, retrieval, post-retrieval, and generation. We systematically analyse them across reconfigured datasets, providing a comprehensive benchmark for their effectiveness. As the complexity of RAG systems continues to escalate, we underscore the critical need to identify potential failure points in RAG systems. We formulate a suite of experimental methodologies and diagnostic testing protocols to dissect the failure points inherent in RAG engineering. Subsequently, we proffer bespoke solutions aimed at bolstering the overall performance of these modules. Our work thoroughly evaluates the performance of advanced core components in RAG systems, providing insights into optimizations for prevalent failure points.
Lightweight Contenders: Navigating Semi-Supervised Text Mining through Peer Collaboration and Self Transcendence
Dec 01, 2024



The semi-supervised learning (SSL) strategy in lightweight models requires reducing annotated samples and facilitating cost-effective inference. However, the constraint on model parameters, imposed by the scarcity of training labels, limits the SSL performance. In this paper, we introduce PS-NET, a novel framework tailored for semi-supervised text mining with lightweight models. PS-NET incorporates online distillation to train lightweight student models by imitating the Teacher model. It also integrates an ensemble of student peers that collaboratively instruct each other. Additionally, PS-NET implements a constant adversarial perturbation schema to further self-augmentation by progressive generalizing. Our PS-NET, equipped with a 2-layer distilled BERT, exhibits notable performance enhancements over SOTA lightweight SSL frameworks of FLiText and DisCo in SSL text classification with extremely rare labelled data.
Variational Multi-Modal Hypergraph Attention Network for Multi-Modal Relation Extraction
Apr 18, 2024
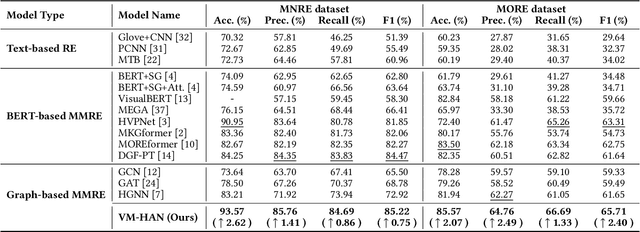
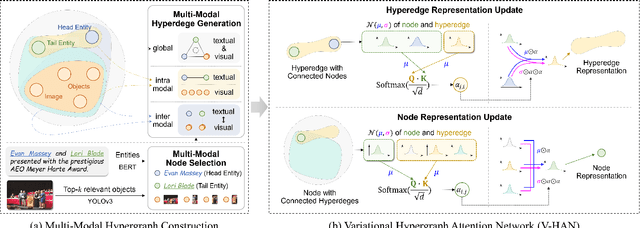
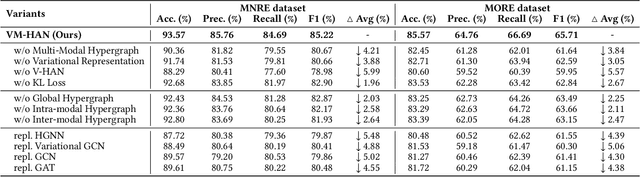
Multi-modal relation extraction (MMRE) is a challenging task that aims to identify relations between entities in text leveraging image information. Existing methods are limited by their neglect of the multiple entity pairs in one sentence sharing very similar contextual information (ie, the same text and image), resulting in increased difficulty in the MMRE task. To address this limitation, we propose the Variational Multi-Modal Hypergraph Attention Network (VM-HAN) for multi-modal relation extraction. Specifically, we first construct a multi-modal hypergraph for each sentence with the corresponding image, to establish different high-order intra-/inter-modal correlations for different entity pairs in each sentence. We further design the Variational Hypergraph Attention Networks (V-HAN) to obtain representational diversity among different entity pairs using Gaussian distribution and learn a better hypergraph structure via variational attention. VM-HAN achieves state-of-the-art performance on the multi-modal relation extraction task, outperforming existing methods in terms of accuracy and efficiency.
FedCQA: Answering Complex Queries on Multi-Source Knowledge Graphs via Federated Learning
Feb 26, 2024Complex logical query answering is a challenging task in knowledge graphs (KGs) that has been widely studied. The ability to perform complex logical reasoning is essential and supports various graph reasoning-based downstream tasks, such as search engines. Recent approaches are proposed to represent KG entities and logical queries into embedding vectors and find answers to logical queries from the KGs. However, existing proposed methods mainly focus on querying a single KG and cannot be applied to multiple graphs. In addition, directly sharing KGs with sensitive information may incur privacy risks, making it impractical to share and construct an aggregated KG for reasoning to retrieve query answers. Thus, it remains unknown how to answer queries on multi-source KGs. An entity can be involved in various knowledge graphs and reasoning on multiple KGs and answering complex queries on multi-source KGs is important in discovering knowledge cross graphs. Fortunately, federated learning is utilized in knowledge graphs to collaboratively learn representations with privacy preserved. Federated knowledge graph embeddings enrich the relations in knowledge graphs to improve the representation quality. However, these methods only focus on one-hop relations and cannot perform complex reasoning tasks. In this paper, we apply federated learning to complex query-answering tasks to reason over multi-source knowledge graphs while preserving privacy. We propose a Federated Complex Query Answering framework (FedCQA), to reason over multi-source KGs avoiding sensitive raw data transmission to protect privacy. We conduct extensive experiments on three real-world datasets and evaluate retrieval performance on various types of complex queries.
Bipartite Graph Pre-training for Unsupervised Extractive Summarization with Graph Convolutional Auto-Encoders
Oct 29, 2023Pre-trained sentence representations are crucial for identifying significant sentences in unsupervised document extractive summarization. However, the traditional two-step paradigm of pre-training and sentence-ranking, creates a gap due to differing optimization objectives. To address this issue, we argue that utilizing pre-trained embeddings derived from a process specifically designed to optimize cohensive and distinctive sentence representations helps rank significant sentences. To do so, we propose a novel graph pre-training auto-encoder to obtain sentence embeddings by explicitly modelling intra-sentential distinctive features and inter-sentential cohesive features through sentence-word bipartite graphs. These pre-trained sentence representations are then utilized in a graph-based ranking algorithm for unsupervised summarization. Our method produces predominant performance for unsupervised summarization frameworks by providing summary-worthy sentence representations. It surpasses heavy BERT- or RoBERTa-based sentence representations in downstream tasks.
Neural-Hidden-CRF: A Robust Weakly-Supervised Sequence Labeler
Sep 28, 2023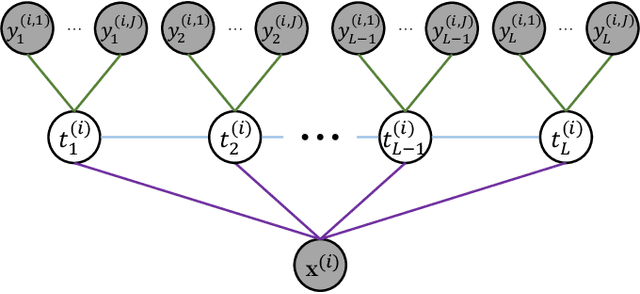

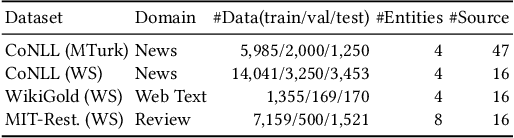
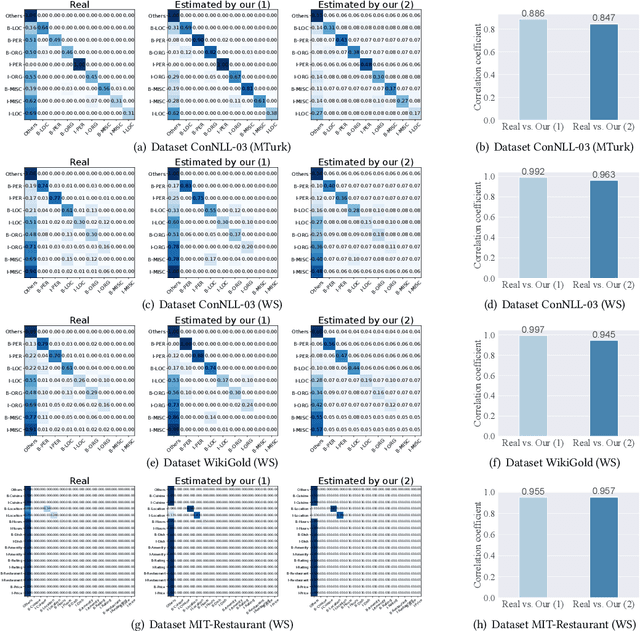
We propose a neuralized undirected graphical model called Neural-Hidden-CRF to solve the weakly-supervised sequence labeling problem. Under the umbrella of probabilistic undirected graph theory, the proposed Neural-Hidden-CRF embedded with a hidden CRF layer models the variables of word sequence, latent ground truth sequence, and weak label sequence with the global perspective that undirected graphical models particularly enjoy. In Neural-Hidden-CRF, we can capitalize on the powerful language model BERT or other deep models to provide rich contextual semantic knowledge to the latent ground truth sequence, and use the hidden CRF layer to capture the internal label dependencies. Neural-Hidden-CRF is conceptually simple and empirically powerful. It obtains new state-of-the-art results on one crowdsourcing benchmark and three weak-supervision benchmarks, including outperforming the recent advanced model CHMM by 2.80 F1 points and 2.23 F1 points in average generalization and inference performance, respectively.