 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoScientist: Towards Multi-Agent Evolving AI Scientists for End-to-End Scientific Discovery
Mar 09, 2026The increasing adoption of Large Language Models (LLMs) has enabled AI scientists to perform complex end-to-end scientific discovery tasks requiring coordination of specialized roles, including idea generation and experimental execution. However, most state-of-the-art AI scientist systems rely on static, hand-designed pipelines and fail to adapt based on accumulated interaction histories. As a result, these systems overlook promising research directions, repeat failed experiments, and pursue infeasible ideas. To address this, we introduce EvoScientist, an evolving multi-agent AI scientist framework that continuously improves research strategies through persistent memory and self-evolution. EvoScientist comprises three specialized agents: a Researcher Agent (RA) for scientific idea generation, an Engineer Agent (EA) for experiment implementation and execution, and an Evolution Manager Agent (EMA) that distills insights from prior interactions into reusable knowledge. EvoScientist contains two persistent memory modules: (i) an ideation memory, which summarizes feasible research directions from top-ranked ideas while recording previously unsuccessful directions; and (ii) an experimentation memory, which captures effective data processing and model training strategies derived from code search trajectories and best-performing implementations. These modules enable the RA and EA to retrieve relevant prior strategies, improving idea quality and code execution success rates over time. Experiments show that EvoScientist outperforms 7 open-source and commercial state-of-the-art systems in scientific idea generation, achieving higher novelty, feasibility, relevance, and clarity via automatic and human evaluation. EvoScientist also substantially improves code execution success rates through multi-agent evolution, demonstrating persistent memory's effectiveness for end-to-end scientific discovery.
XRAG: eXamining the Core -- Benchmarking Foundational Components in Advanced Retrieval-Augmented Generation
Dec 24, 2024Retrieval-augmented generation (RAG) synergizes the retrieval of pertinent data with the generative capabilities of Large Language Models (LLMs), ensuring that the generated output is not only contextually relevant but also accurate and current. We introduce XRAG, an open-source, modular codebase that facilitates exhaustive evaluation of the performance of foundational components of advanced RAG modules. These components are systematically categorized into four core phases: pre-retrieval, retrieval, post-retrieval, and generation. We systematically analyse them across reconfigured datasets, providing a comprehensive benchmark for their effectiveness. As the complexity of RAG systems continues to escalate, we underscore the critical need to identify potential failure points in RAG systems. We formulate a suite of experimental methodologies and diagnostic testing protocols to dissect the failure points inherent in RAG engineering. Subsequently, we proffer bespoke solutions aimed at bolstering the overall performance of these modules. Our work thoroughly evaluates the performance of advanced core components in RAG systems, providing insights into optimizations for prevalent failure points.
Towards Explainable Conversational Recommender Systems
May 27, 2023Explanations in conventional recommender systems have demonstrated benefits in helping the user understand the rationality of the recommendations and improving the system's efficiency, transparency, and trustworthiness. In the conversational environment, multiple contextualized explanations need to be generated, which poses further challenges for explanations. To better measure explainability in conversational recommender systems (CRS), we propose ten evaluation perspectives based on concepts from conventional recommender systems together with the characteristics of CRS. We assess five existing CRS benchmark datasets using these metrics and observe the necessity of improving the explanation quality of CRS. To achieve this, we conduct manual and automatic approaches to extend these dialogues and construct a new CRS dataset, namely Explainable Recommendation Dialogues (E-ReDial). It includes 756 dialogues with over 2,000 high-quality rewritten explanations. We compare two baseline approaches to perform explanation generation based on E-ReDial. Experimental results suggest that models trained on E-ReDial can significantly improve explainability while introducing knowledge into the models can further improve the performance. GPT-3 in the in-context learning setting can generate more realistic and diverse movie descriptions. In contrast, T5 training on E-ReDial can better generate clear reasons for recommendations based on user preferences. E-ReDial is available at https://github.com/Superbooming/E-ReDial.
Metaphorical User Simulators for Evaluating Task-oriented Dialogue Systems
Apr 06, 2022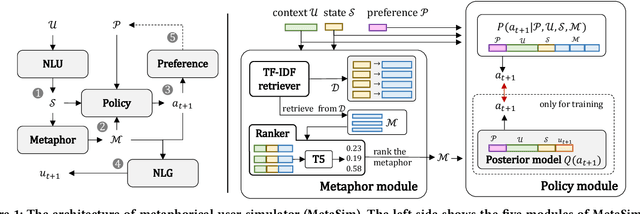
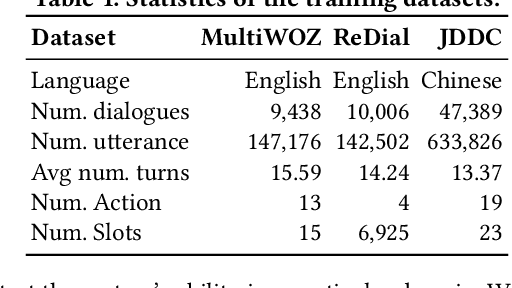

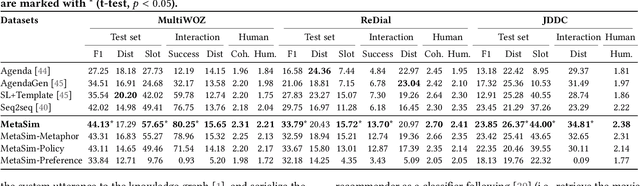
Task-oriented dialogue systems (TDSs) are assessed mainly in an offline setting or through human evaluation. The evaluation is often limited to single-turn or very time-intensive. As an alternative, user simulators that mimic user behavior allow us to consider a broad set of user goals to generate human-like conversations for simulated evaluation. Employing existing user simulators to evaluate TDSs is challenging as user simulators are primarily designed to optimize dialogue policies for TDSs and have limited evaluation capability. Moreover, the evaluation of user simulators is an open challenge. In this work, we proposes a metaphorical user simulator for endto-end TDS evaluation. We also propose a tester-based evaluation framework to generate variants, i.e., dialogue systems with different capabilities. Our user simulator constructs a metaphorical user model that assists the simulator in reasoning by referring to prior knowledge when encountering new items. We estimate the quality of simulators by checking the simulated interactions between simulators and variants. Our experiments are conducted using three TDS datasets. The metaphorical user simulator demonstrates better consistency with manual evaluation than Agenda-based simulator and Seq2seq model on three datasets; our tester framework demonstrates efficiency, and our approach demonstrates better generalization and scalability.