 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAL: Scalable Multi-Task Robot Learning via LoRA Experts
Mar 10, 2026Deploying Vision-Language-Action (VLA) models in real-world robotics exposes a core multi-task learning challenge: reconciling task interference in multi-task robotic learning. When multiple tasks are jointly fine-tuned in a single stage, gradients from different tasks can conflict, causing negative transfer and reducing per-task performance. Yet maintaining a separate full checkpoint per task is often storage- and deployment-prohibitive. To address this dilemma, we present CORAL, a backbone- and embodiment-agnostic framework designed primarily to mitigate multi-task interference while remaining naturally extensible to a continuous stream of new tasks. CORAL freezes a single pre-trained VLA backbone and attaches one lightweight Low-Rank Adaptation (LoRA) expert per task; at runtime, a dynamic inference engine (the CORAL Manager) routes language instructions to the appropriate expert and swaps experts on the fly with zero inference overhead. This strict parameter isolation avoids complex gating networks and prevents parameter-level cross-task interference by construction; as an added capability, it also enables sequentially introducing new tasks without parameter overwriting caused by catastrophic forgetting. We validate CORAL on a real-world Galaxea R1 dual-arm mobile manipulator and three simulation benchmarks (LIBERO, WidowX, Google Robot), where CORAL overcomes fine-grained instructional ambiguity and substantially outperforms joint training, yielding a practical and scalable system for lifelong multi-task robot learning. Website: https://frontierrobo.github.io/CORAL
Accelerating Generative Recommendation via Simple Categorical User Sequence Compression
Jan 27, 2026Although generative recommenders demonstrate improved performance with longer sequences, their real-time deployment is hindered by substantial computational costs. To address this challenge, we propose a simple yet effective method for compressing long-term user histories by leveraging inherent item categorical features, thereby preserving user interests while enhancing efficiency. Experiments on two large-scale datasets demonstrate that, compared to the influential HSTU model, our approach achieves up to a 6x reduction in computational cost and up to 39% higher accuracy at comparable cost (i.e., similar sequence length).
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Feb 25, 2025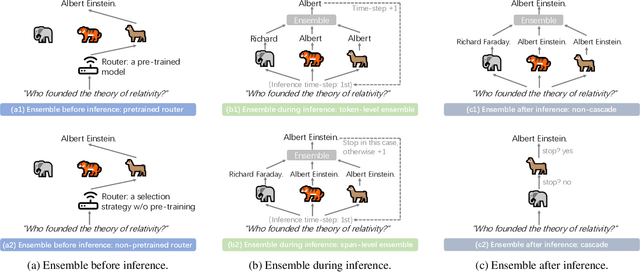
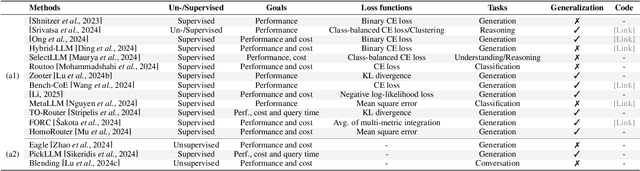
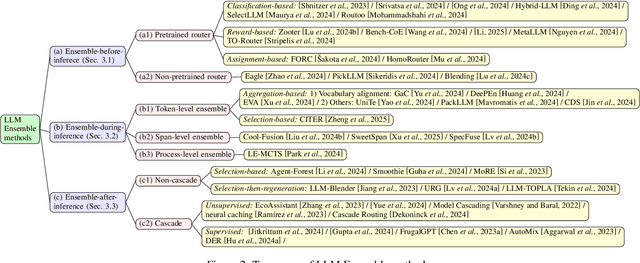
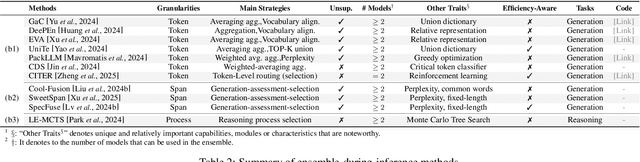
LLM Ensemble -- which involves the comprehensive use of multiple large language models (LLMs), each aimed at handling user queries during downstream inference, to benefit from their individual strengths -- has gained substantial attention recently. The widespread availability of LLMs, coupled with their varying strengths and out-of-the-box usability, has profoundly advanced the field of LLM Ensemble. This paper presents the first systematic review of recent developments in LLM Ensemble. First, we introduce our taxonomy of LLM Ensemble and discuss several related research problems. Then, we provide a more in-depth classification of the methods under the broad categories of "ensemble-before-inference, ensemble-during-inference, ensemble-after-inference", and review all relevant methods. Finally, we introduce related benchmarks and applications, summarize existing studies, and suggest several future research directions. A curated list of papers on LLM Ensemble is available at https://github.com/junchenzhi/Awesome-LLM-Ensemble.
Unlocking the Potential of Classic GNNs for Graph-level Tasks: Simple Architectures Meet Excellence
Feb 13, 2025Message-passing Graph Neural Networks (GNNs) are often criticized for their limited expressiveness, issues like over-smoothing and over-squashing, and challenges in capturing long-range dependencies, while Graph Transformers (GTs) are considered superior due to their global attention mechanisms. Literature frequently suggests that GTs outperform GNNs, particularly in graph-level tasks such as graph classification and regression. In this study, we explore the untapped potential of GNNs through an enhanced framework, GNN+, which integrates six widely used techniques: edge feature integration, normalization, dropout, residual connections, feed-forward networks, and positional encoding, to effectively tackle graph-level tasks. We conduct a systematic evaluation of three classic GNNs, namely GCN, GIN, and GatedGCN, enhanced by the GNN+ framework across 14 well-known graph-level datasets. Our results show that, contrary to the prevailing belief, classic GNNs excel in graph-level tasks, securing top three rankings across all datasets and achieving first place in eight, while also demonstrating greater efficiency than GTs. This highlights the potential of simple GNN architectures, challenging the belief that complex mechanisms in GTs are essential for superior graph-level performance.
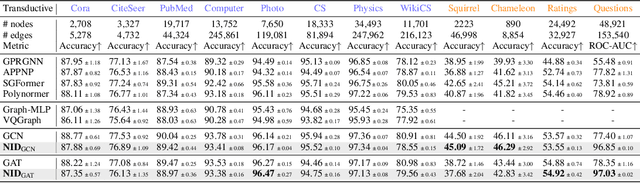
Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification
Jun 13, 2024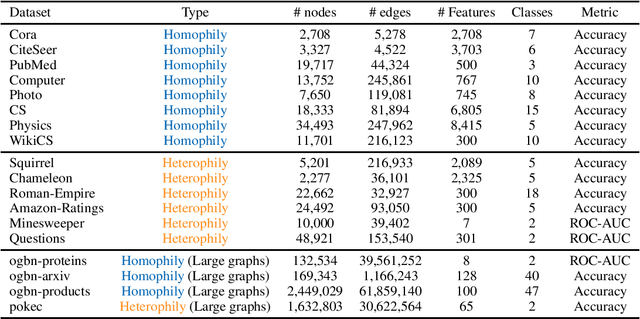
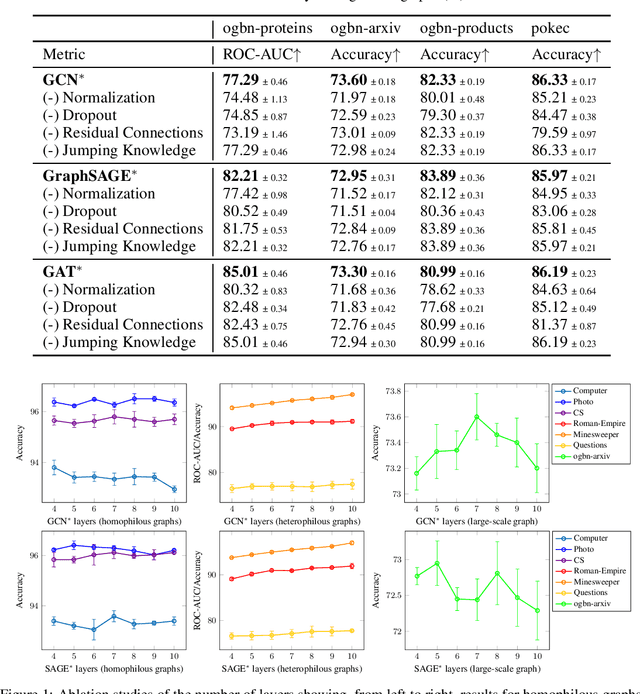
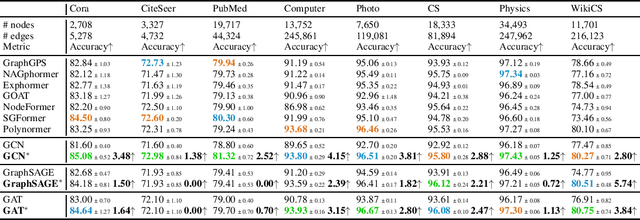
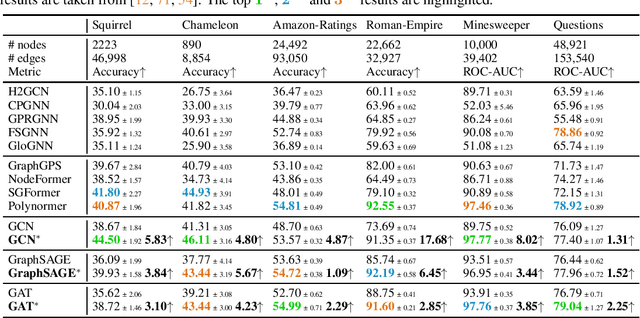
Graph Transformers (GTs) have recently emerged as popular alternatives to traditional message-passing Graph Neural Networks (GNNs), due to their theoretically superior expressiveness and impressive performance reported on standard node classification benchmarks, often significantly outperforming GNNs. In this paper, we conduct a thorough empirical analysis to reevaluate the performance of three classic GNN models (GCN, GAT, and GraphSAGE) against GTs. Our findings suggest that the previously reported superiority of GTs may have been overstated due to suboptimal hyperparameter configurations in GNNs. Remarkably, with slight hyperparameter tuning, these classic GNN models achieve state-of-the-art performance, matching or even exceeding that of recent GTs across 17 out of the 18 diverse datasets examined. Additionally, we conduct detailed ablation studies to investigate the influence of various GNN configurations, such as normalization, dropout, residual connections, network depth, and jumping knowledge mode, on node classification performance. Our study aims to promote a higher standard of empirical rigor in the field of graph machine learning, encouraging more accurate comparisons and evaluations of model capabilities.
Structure-aware Semantic Node Identifiers for Learning on Graphs
May 26, 2024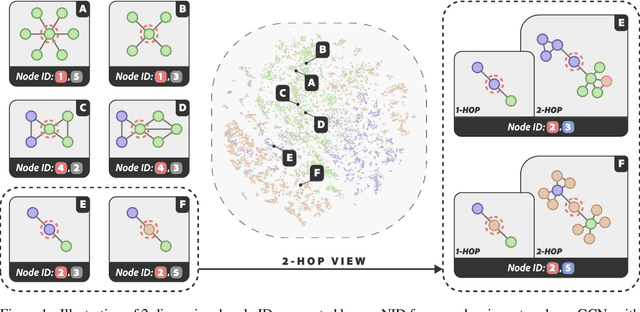
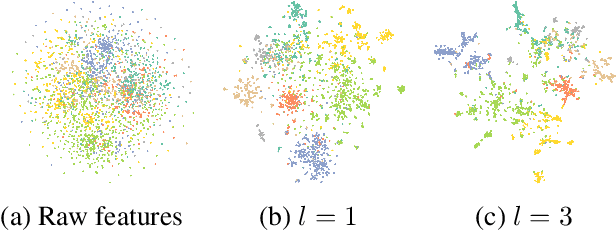

We present a novel graph tokenization framework that generates structure-aware, semantic node identifiers (IDs) in the form of a short sequence of discrete codes, serving as symbolic representations of nodes. We employs vector quantization to compress continuous node embeddings from multiple layers of a graph neural network (GNN), into compact, meaningful codes, under both self-supervised and supervised learning paradigms. The resulting node IDs capture a high-level abstraction of graph data, enhancing the efficiency and interpretability of GNNs. Through extensive experiments on 34 datasets, including node classification, graph classification, link prediction, and attributed graph clustering tasks, we demonstrate that our generated node IDs not only improve computational efficiency but also achieve competitive performance compared to current state-of-the-art methods.
Decoy Effect In Search Interaction: Understanding User Behavior and Measuring System Vulnerability
Mar 27, 2024This study examines the decoy effect's underexplored influence on user search interactions and methods for measuring information retrieval (IR) systems' vulnerability to this effect. It explores how decoy results alter users' interactions on search engine result pages, focusing on metrics like click-through likelihood, browsing time, and perceived document usefulness. By analyzing user interaction logs from multiple datasets, the study demonstrates that decoy results significantly affect users' behavior and perceptions. Furthermore, it investigates how different levels of task difficulty and user knowledge modify the decoy effect's impact, finding that easier tasks and lower knowledge levels lead to higher engagement with target documents. In terms of IR system evaluation, the study introduces the DEJA-VU metric to assess systems' susceptibility to the decoy effect, testing it on specific retrieval tasks. The results show differences in systems' effectiveness and vulnerability, contributing to our understanding of cognitive biases in search behavior and suggesting pathways for creating more balanced and bias-aware IR evaluations.
Improving Self-supervised Molecular Representation Learning using Persistent Homology
Nov 29, 2023Self-supervised learning (SSL) has great potential for molecular representation learning given the complexity of molecular graphs, the large amounts of unlabelled data available, the considerable cost of obtaining labels experimentally, and the hence often only small training datasets. The importance of the topic is reflected in the variety of paradigms and architectures that have been investigated recently. Yet the differences in performance seem often minor and are barely understood to date. In this paper, we study SSL based on persistent homology (PH), a mathematical tool for modeling topological features of data that persist across multiple scales. It has several unique features which particularly suit SSL, naturally offering: different views of the data, stability in terms of distance preservation, and the opportunity to flexibly incorporate domain knowledge. We (1) investigate an autoencoder, which shows the general representational power of PH, and (2) propose a contrastive loss that complements existing approaches. We rigorously evaluate our approach for molecular property prediction and demonstrate its particular features in improving the embedding space: after SSL, the representations are better and offer considerably more predictive power than the baselines over different probing tasks; our loss increases baseline performance, sometimes largely; and we often obtain substantial improvements over very small datasets, a common scenario in practice.
Transformers for Capturing Multi-level Graph Structure using Hierarchical Distances
Aug 22, 2023Graph transformers need strong inductive biases to derive meaningful attention scores. Yet, current proposals rarely address methods capturing longer ranges, hierarchical structures, or community structures, as they appear in various graphs such as molecules, social networks, and citation networks. In this paper, we propose a hierarchy-distance structural encoding (HDSE), which models a hierarchical distance between the nodes in a graph focusing on its multi-level, hierarchical nature. In particular, this yields a framework which can be flexibly integrated with existing graph transformers, allowing for simultaneous application with other positional representations. Through extensive experiments on 12 real-world datasets, we demonstrate that our HDSE method successfully enhances various types of baseline transformers, achieving state-of-the-art empirical performances on 10 benchmark datasets.
Impact-Oriented Contextual Scholar Profiling using Self-Citation Graphs
Apr 24, 2023
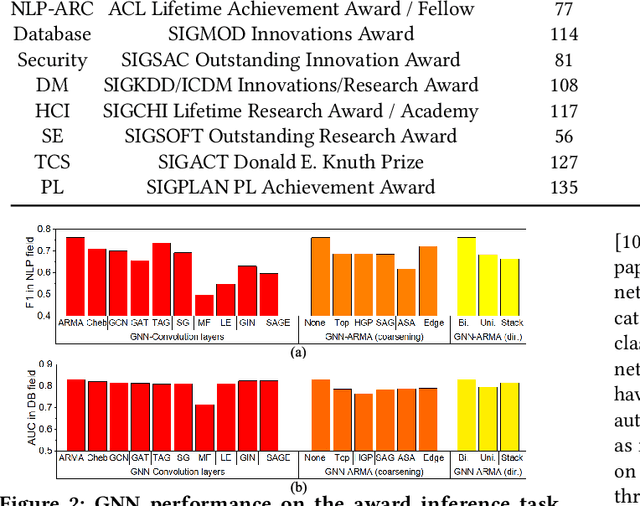
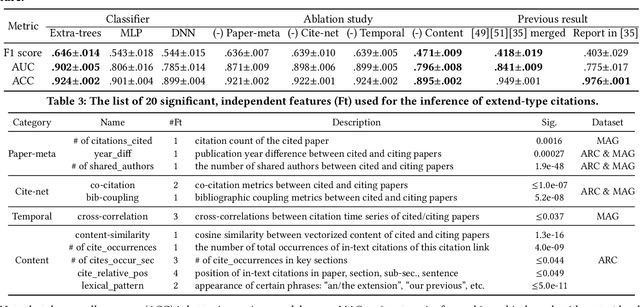
Quantitatively profiling a scholar's scientific impact is important to modern research society. Current practices with bibliometric indicators (e.g., h-index), lists, and networks perform well at scholar ranking, but do not provide structured context for scholar-centric, analytical tasks such as profile reasoning and understanding. This work presents GeneticFlow (GF), a suite of novel graph-based scholar profiles that fulfill three essential requirements: structured-context, scholar-centric, and evolution-rich. We propose a framework to compute GF over large-scale academic data sources with millions of scholars. The framework encompasses a new unsupervised advisor-advisee detection algorithm, a well-engineered citation type classifier using interpretable features, and a fine-tuned graph neural network (GNN) model. Evaluations are conducted on the real-world task of scientific award inference. Experiment outcomes show that the F1 score of best GF profile significantly outperforms alternative methods of impact indicators and bibliometric networks in all the 6 computer science fields considered. Moreover, the core GF profiles, with 63.6%-66.5% nodes and 12.5%-29.9% edges of the full profile, still significantly outrun existing methods in 5 out of 6 fields studied. Visualization of GF profiling result also reveals human explainable patterns for high-impact scholars.