 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Generative Recommendation via Simple Categorical User Sequence Compression
Jan 27, 2026Although generative recommenders demonstrate improved performance with longer sequences, their real-time deployment is hindered by substantial computational costs. To address this challenge, we propose a simple yet effective method for compressing long-term user histories by leveraging inherent item categorical features, thereby preserving user interests while enhancing efficiency. Experiments on two large-scale datasets demonstrate that, compared to the influential HSTU model, our approach achieves up to a 6x reduction in computational cost and up to 39% higher accuracy at comparable cost (i.e., similar sequence length).
Benchmarking LLMs in Recommendation Tasks: A Comparative Evaluation with Conventional Recommenders
Mar 07, 2025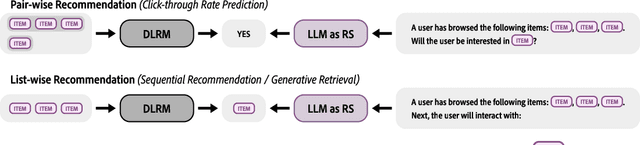
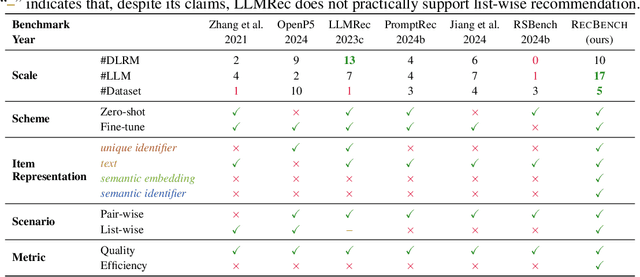
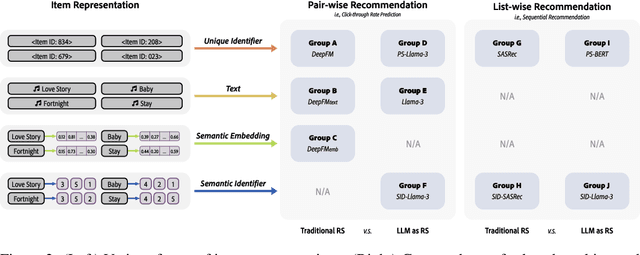
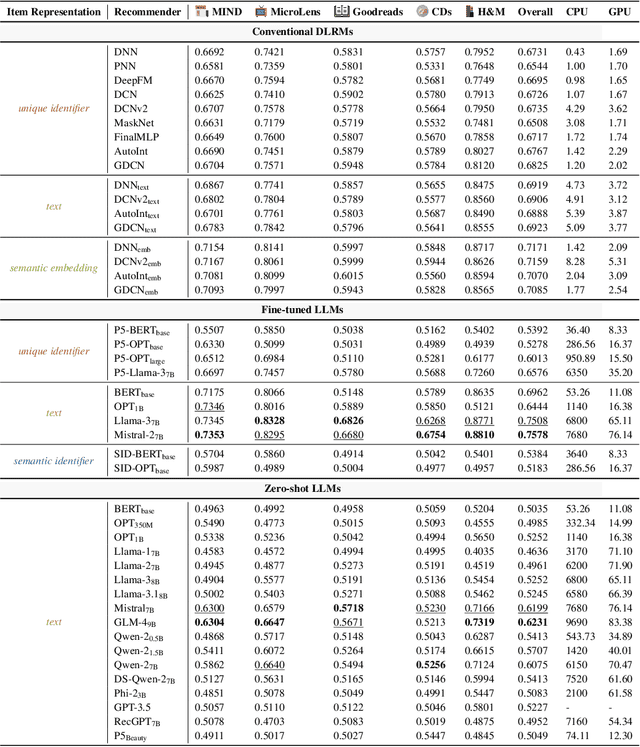
In recent years, integrating large language models (LLMs) into recommender systems has created new opportunities for improving recommendation quality. However, a comprehensive benchmark is needed to thoroughly evaluate and compare the recommendation capabilities of LLMs with traditional recommender systems. In this paper, we introduce RecBench, which systematically investigates various item representation forms (including unique identifier, text, semantic embedding, and semantic identifier) and evaluates two primary recommendation tasks, i.e., click-through rate prediction (CTR) and sequential recommendation (SeqRec). Our extensive experiments cover up to 17 large models and are conducted across five diverse datasets from fashion, news, video, books, and music domains. Our findings indicate that LLM-based recommenders outperform conventional recommenders, achieving up to a 5% AUC improvement in the CTR scenario and up to a 170% NDCG@10 improvement in the SeqRec scenario. However, these substantial performance gains come at the expense of significantly reduced inference efficiency, rendering the LLM-as-RS paradigm impractical for real-time recommendation environments. We aim for our findings to inspire future research, including recommendation-specific model acceleration methods. We will release our code, data, configurations, and platform to enable other researchers to reproduce and build upon our experimental results.
Legommenders: A Comprehensive Content-Based Recommendation Library with LLM Support
Dec 20, 2024We present Legommenders, a unique library designed for content-based recommendation that enables the joint training of content encoders alongside behavior and interaction modules, thereby facilitating the seamless integration of content understanding directly into the recommendation pipeline. Legommenders allows researchers to effortlessly create and analyze over 1,000 distinct models across 15 diverse datasets. Further, it supports the incorporation of contemporary large language models, both as feature encoder and data generator, offering a robust platform for developing state-of-the-art recommendation models and enabling more personalized and effective content delivery.
NetSafe: Exploring the Topological Safety of Multi-agent Networks
Oct 21, 2024
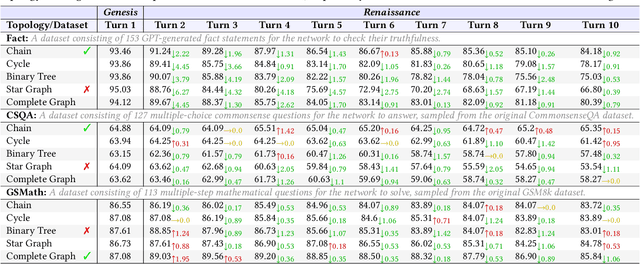
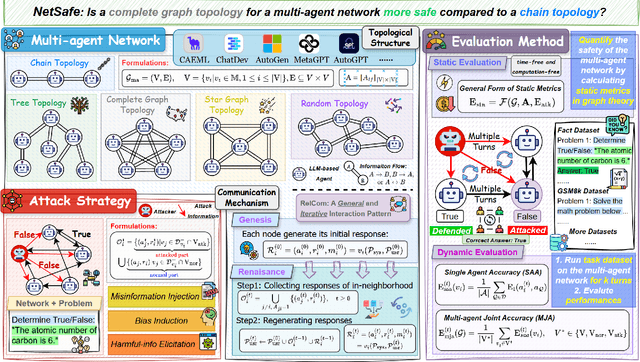
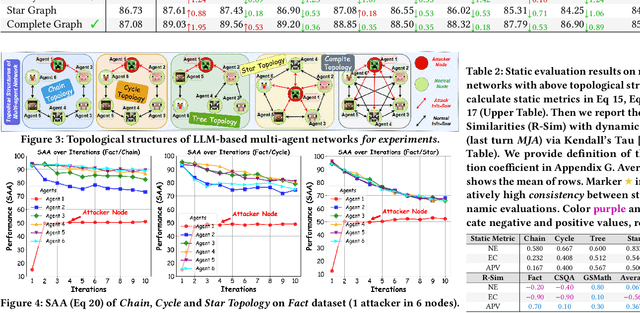
Large language models (LLMs) have empowered nodes within multi-agent networks with intelligence, showing growing applications in both academia and industry. However, how to prevent these networks from generating malicious information remains unexplored with previous research on single LLM's safety be challenging to transfer. In this paper, we focus on the safety of multi-agent networks from a topological perspective, investigating which topological properties contribute to safer networks. To this end, we propose a general framework, NetSafe along with an iterative RelCom interaction to unify existing diverse LLM-based agent frameworks, laying the foundation for generalized topological safety research. We identify several critical phenomena when multi-agent networks are exposed to attacks involving misinformation, bias, and harmful information, termed as Agent Hallucination and Aggregation Safety. Furthermore, we find that highly connected networks are more susceptible to the spread of adversarial attacks, with task performance in a Star Graph Topology decreasing by 29.7%. Besides, our proposed static metrics aligned more closely with real-world dynamic evaluations than traditional graph-theoretic metrics, indicating that networks with greater average distances from attackers exhibit enhanced safety. In conclusion, our work introduces a new topological perspective on the safety of LLM-based multi-agent networks and discovers several unreported phenomena, paving the way for future research to explore the safety of such networks.
AI Can Be Cognitively Biased: An Exploratory Study on Threshold Priming in LLM-Based Batch Relevance Assessment
Sep 24, 2024



Cognitive biases are systematic deviations in thinking that lead to irrational judgments and problematic decision-making, extensively studied across various fields. Recently, large language models (LLMs) have shown advanced understanding capabilities but may inherit human biases from their training data. While social biases in LLMs have been well-studied, cognitive biases have received less attention, with existing research focusing on specific scenarios. The broader impact of cognitive biases on LLMs in various decision-making contexts remains underexplored. We investigated whether LLMs are influenced by the threshold priming effect in relevance judgments, a core task and widely-discussed research topic in the Information Retrieval (IR) coummunity. The priming effect occurs when exposure to certain stimuli unconsciously affects subsequent behavior and decisions. Our experiment employed 10 topics from the TREC 2019 Deep Learning passage track collection, and tested AI judgments under different document relevance scores, batch lengths, and LLM models, including GPT-3.5, GPT-4, LLaMa2-13B and LLaMa2-70B. Results showed that LLMs tend to give lower scores to later documents if earlier ones have high relevance, and vice versa, regardless of the combination and model used. Our finding demonstrates that LLM%u2019s judgments, similar to human judgments, are also influenced by threshold priming biases, and suggests that researchers and system engineers should take into account potential human-like cognitive biases in designing, evaluating, and auditing LLMs in IR tasks and beyond.
STORE: Streamlining Semantic Tokenization and Generative Recommendation with A Single LLM
Sep 11, 2024Traditional recommendation models often rely on unique item identifiers (IDs) to distinguish between items, which can hinder their ability to effectively leverage item content information and generalize to long-tail or cold-start items. Recently, semantic tokenization has been proposed as a promising solution that aims to tokenize each item's semantic representation into a sequence of discrete tokens. In this way, it preserves the item's semantics within these tokens and ensures that semantically similar items are represented by similar tokens. These semantic tokens have become fundamental in training generative recommendation models. However, existing generative recommendation methods typically involve multiple sub-models for embedding, quantization, and recommendation, leading to an overly complex system. In this paper, we propose to streamline the semantic tokenization and generative recommendation process with a unified framework, dubbed STORE, which leverages a single large language model (LLM) for both tasks. Specifically, we formulate semantic tokenization as a text-to-token task and generative recommendation as a token-to-token task, supplemented by a token-to-text reconstruction task and a text-to-token auxiliary task. All these tasks are framed in a generative manner and trained using a single LLM backbone. Extensive experiments have been conducted to validate the effectiveness of our STORE framework across various recommendation tasks and datasets. We will release the source code and configurations for reproducible research.
Structure-aware Semantic Node Identifiers for Learning on Graphs
May 26, 2024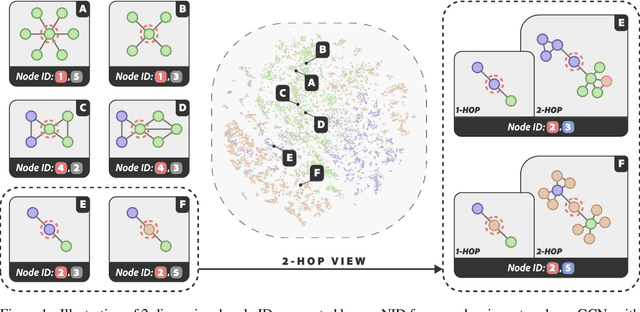
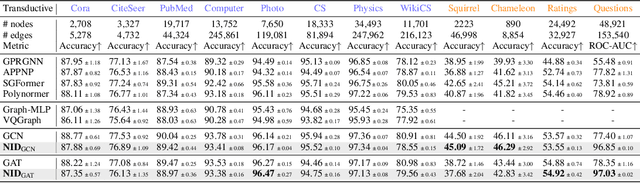
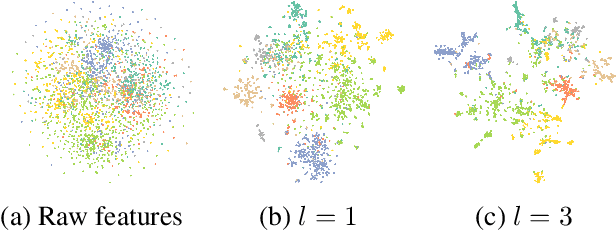

We present a novel graph tokenization framework that generates structure-aware, semantic node identifiers (IDs) in the form of a short sequence of discrete codes, serving as symbolic representations of nodes. We employs vector quantization to compress continuous node embeddings from multiple layers of a graph neural network (GNN), into compact, meaningful codes, under both self-supervised and supervised learning paradigms. The resulting node IDs capture a high-level abstraction of graph data, enhancing the efficiency and interpretability of GNNs. Through extensive experiments on 34 datasets, including node classification, graph classification, link prediction, and attributed graph clustering tasks, we demonstrate that our generated node IDs not only improve computational efficiency but also achieve competitive performance compared to current state-of-the-art methods.
Vector Quantization for Recommender Systems: A Review and Outlook
May 06, 2024Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Mar 31, 2024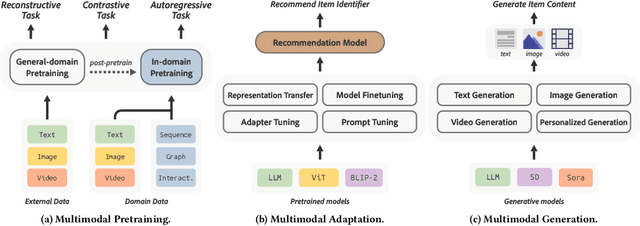
Personalized recommendation serves as a ubiquitous channel for users to discover information or items tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in pretrained multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications to recommender systems. Furthermore, we discuss open challenges and opportunities for future research in this domain. We hope that this survey, along with our tutorial materials, will inspire further research efforts to advance this evolving landscape.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 21, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings, subsequently caching them to optimize processing time at the expense of space. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.