 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISanitizer: Preventing Prompt Injection to Long-Context LLMs via Prompt Sanitization
Nov 13, 2025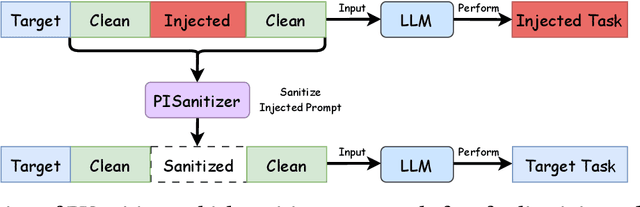
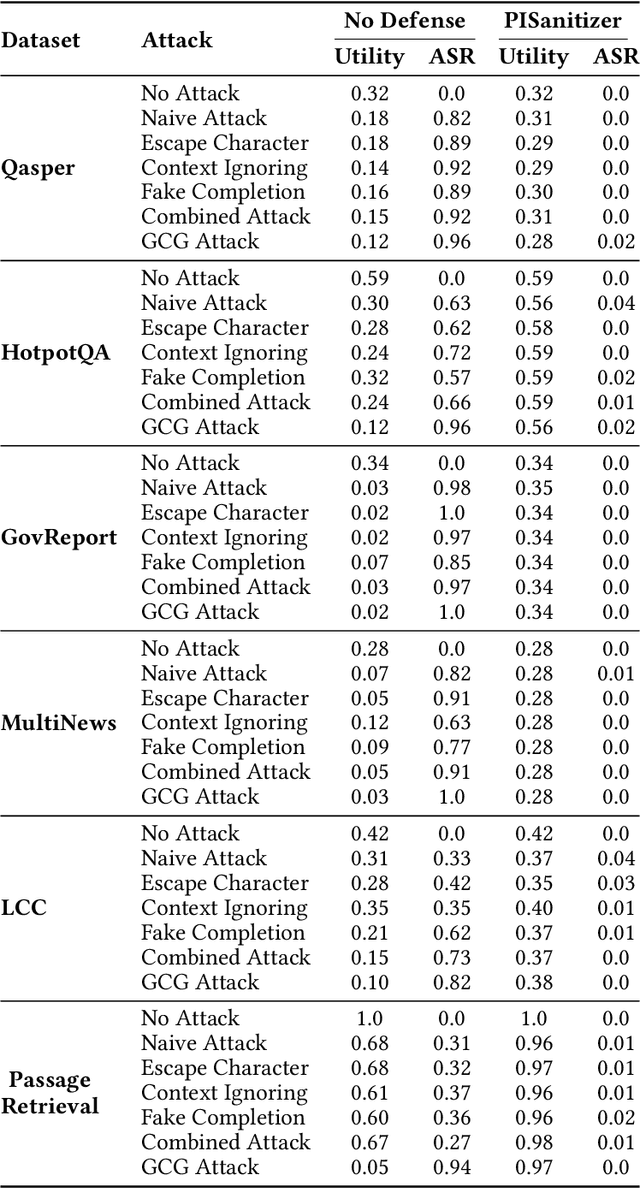
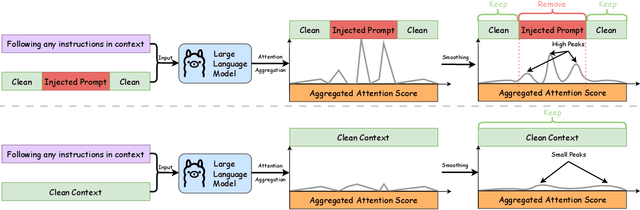

Long context LLMs are vulnerable to prompt injection, where an attacker can inject an instruction in a long context to induce an LLM to generate an attacker-desired output. Existing prompt injection defenses are designed for short contexts. When extended to long-context scenarios, they have limited effectiveness. The reason is that an injected instruction constitutes only a very small portion of a long context, making the defense very challenging. In this work, we propose PISanitizer, which first pinpoints and sanitizes potential injected tokens (if any) in a context before letting a backend LLM generate a response, thereby eliminating the influence of the injected instruction. To sanitize injected tokens, PISanitizer builds on two observations: (1) prompt injection attacks essentially craft an instruction that compels an LLM to follow it, and (2) LLMs intrinsically leverage the attention mechanism to focus on crucial input tokens for output generation. Guided by these two observations, we first intentionally let an LLM follow arbitrary instructions in a context and then sanitize tokens receiving high attention that drive the instruction-following behavior of the LLM. By design, PISanitizer presents a dilemma for an attacker: the more effectively an injected instruction compels an LLM to follow it, the more likely it is to be sanitized by PISanitizer. Our extensive evaluation shows that PISanitizer can successfully prevent prompt injection, maintain utility, outperform existing defenses, is efficient, and is robust to optimization-based and strong adaptive attacks. The code is available at https://github.com/sleeepeer/PISanitizer.
The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination
Oct 27, 2025Enhancing the reasoning capabilities of Large Language Models (LLMs) is a key strategy for building Agents that "think then act." However, recent observations, like OpenAI's o3, suggest a paradox: stronger reasoning often coincides with increased hallucination, yet no prior work has systematically examined whether reasoning enhancement itself causes tool hallucination. To address this gap, we pose the central question: Does strengthening reasoning increase tool hallucination? To answer this, we introduce SimpleToolHalluBench, a diagnostic benchmark measuring tool hallucination in two failure modes: (i) no tool available, and (ii) only distractor tools available. Through controlled experiments, we establish three key findings. First, we demonstrate a causal relationship: progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains. Second, this effect transcends overfitting - training on non-tool tasks (e.g., mathematics) still amplifies subsequent tool hallucination. Third, the effect is method-agnostic, appearing when reasoning is instilled via supervised fine-tuning and when it is merely elicited at inference by switching from direct answers to step-by-step thinking. We also evaluate mitigation strategies including Prompt Engineering and Direct Preference Optimization (DPO), revealing a fundamental reliability-capability trade-off: reducing hallucination consistently degrades utility. Mechanistically, Reasoning RL disproportionately collapses tool-reliability-related representations, and hallucinations surface as amplified divergences concentrated in late-layer residual streams. These findings reveal that current reasoning enhancement methods inherently amplify tool hallucination, highlighting the need for new training objectives that jointly optimize for capability and reliability.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
NetSafe: Exploring the Topological Safety of Multi-agent Networks
Oct 21, 2024
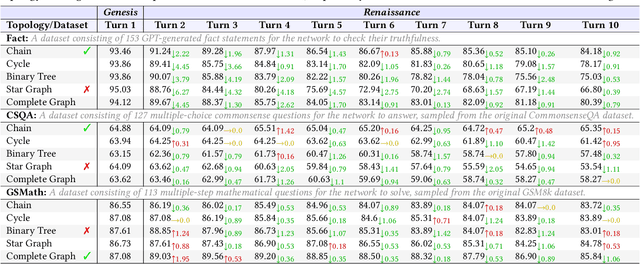
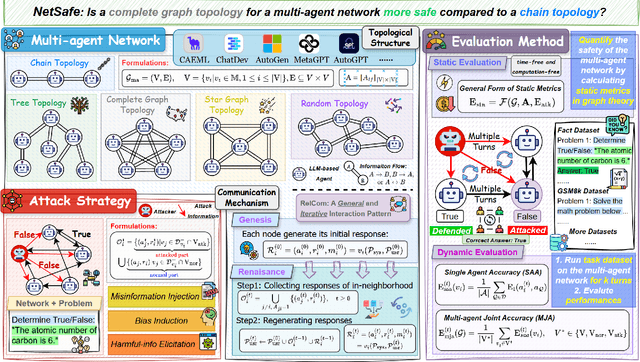
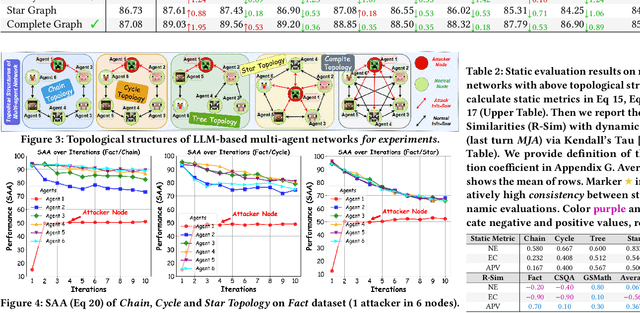
Large language models (LLMs) have empowered nodes within multi-agent networks with intelligence, showing growing applications in both academia and industry. However, how to prevent these networks from generating malicious information remains unexplored with previous research on single LLM's safety be challenging to transfer. In this paper, we focus on the safety of multi-agent networks from a topological perspective, investigating which topological properties contribute to safer networks. To this end, we propose a general framework, NetSafe along with an iterative RelCom interaction to unify existing diverse LLM-based agent frameworks, laying the foundation for generalized topological safety research. We identify several critical phenomena when multi-agent networks are exposed to attacks involving misinformation, bias, and harmful information, termed as Agent Hallucination and Aggregation Safety. Furthermore, we find that highly connected networks are more susceptible to the spread of adversarial attacks, with task performance in a Star Graph Topology decreasing by 29.7%. Besides, our proposed static metrics aligned more closely with real-world dynamic evaluations than traditional graph-theoretic metrics, indicating that networks with greater average distances from attackers exhibit enhanced safety. In conclusion, our work introduces a new topological perspective on the safety of LLM-based multi-agent networks and discovers several unreported phenomena, paving the way for future research to explore the safety of such networks.
Unleash The Power of Pre-Trained Language Models for Irregularly Sampled Time Series
Aug 12, 2024
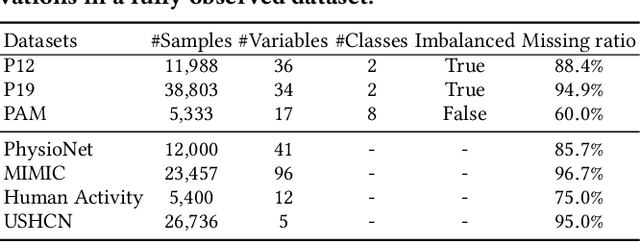


Pre-trained Language Models (PLMs), such as ChatGPT, have significantly advanced the field of natural language processing. This progress has inspired a series of innovative studies that explore the adaptation of PLMs to time series analysis, intending to create a unified foundation model that addresses various time series analytical tasks. However, these efforts predominantly focus on Regularly Sampled Time Series (RSTS), neglecting the unique challenges posed by Irregularly Sampled Time Series (ISTS), which are characterized by non-uniform sampling intervals and prevalent missing data. To bridge this gap, this work explores the potential of PLMs for ISTS analysis. We begin by investigating the effect of various methods for representing ISTS, aiming to maximize the efficacy of PLMs in this under-explored area. Furthermore, we present a unified PLM-based framework, ISTS-PLM, which integrates time-aware and variable-aware PLMs tailored for comprehensive intra and inter-time series modeling and includes a learnable input embedding layer and a task-specific output layer to tackle diverse ISTS analytical tasks. Extensive experiments on a comprehensive benchmark demonstrate that the ISTS-PLM, utilizing a simple yet effective series-based representation for ISTS, consistently achieves state-of-the-art performance across various analytical tasks, such as classification, interpolation, and extrapolation, as well as few-shot and zero-shot learning scenarios, spanning scientific domains like healthcare and biomechanics.