 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSABlock: Semantic-Aware KV Cache Eviction with Adaptive Compression Block Size
Oct 26, 2025



The growing memory footprint of the Key-Value (KV) cache poses a severe scalability bottleneck for long-context Large Language Model (LLM) inference. While KV cache eviction has emerged as an effective solution by discarding less critical tokens, existing token-, block-, and sentence-level compression methods struggle to balance semantic coherence and memory efficiency. To this end, we introduce SABlock, a \underline{s}emantic-aware KV cache eviction framework with \underline{a}daptive \underline{block} sizes. Specifically, SABlock first performs semantic segmentation to align compression boundaries with linguistic structures, then applies segment-guided token scoring to refine token importance estimation. Finally, for each segment, a budget-driven search strategy adaptively determines the optimal block size that preserves semantic integrity while improving compression efficiency under a given cache budget. Extensive experiments on long-context benchmarks demonstrate that SABlock consistently outperforms state-of-the-art baselines under the same memory budgets. For instance, on Needle-in-a-Haystack (NIAH), SABlock achieves 99.9% retrieval accuracy with only 96 KV entries, nearly matching the performance of the full-cache baseline that retains up to 8K entries. Under a fixed cache budget of 1,024, SABlock further reduces peak memory usage by 46.28% and achieves up to 9.5x faster decoding on a 128K context length.
Mitigating Catastrophic Forgetting with Adaptive Transformer Block Expansion in Federated Fine-Tuning
Jun 06, 2025Federated fine-tuning (FedFT) of large language models (LLMs) has emerged as a promising solution for adapting models to distributed data environments while ensuring data privacy. Existing FedFT methods predominantly utilize parameter-efficient fine-tuning (PEFT) techniques to reduce communication and computation overhead. However, they often fail to adequately address the catastrophic forgetting, a critical challenge arising from continual adaptation in distributed environments. The traditional centralized fine-tuning methods, which are not designed for the heterogeneous and privacy-constrained nature of federated environments, struggle to mitigate this issue effectively. Moreover, the challenge is further exacerbated by significant variation in data distributions and device capabilities across clients, which leads to intensified forgetting and degraded model generalization. To tackle these issues, we propose FedBE, a novel FedFT framework that integrates an adaptive transformer block expansion mechanism with a dynamic trainable-block allocation strategy. Specifically, FedBE expands trainable blocks within the model architecture, structurally separating newly learned task-specific knowledge from the original pre-trained representations. Additionally, FedBE dynamically assigns these trainable blocks to clients based on their data distributions and computational capabilities. This enables the framework to better accommodate heterogeneous federated environments and enhances the generalization ability of the model.Extensive experiments show that compared with existing federated fine-tuning methods, FedBE achieves 12-74% higher accuracy retention on general tasks after fine-tuning and a model convergence acceleration ratio of 1.9-3.1x without degrading the accuracy of downstream tasks.
Efficient Federated Fine-Tuning of Large Language Models with Layer Dropout
Mar 13, 2025Fine-tuning plays a crucial role in enabling pre-trained LLMs to evolve from general language comprehension to task-specific expertise. To preserve user data privacy, federated fine-tuning is often employed and has emerged as the de facto paradigm. However, federated fine-tuning is prohibitively inefficient due to the tension between LLM complexity and the resource constraint of end devices, incurring unaffordable fine-tuning overhead. Existing literature primarily utilizes parameter-efficient fine-tuning techniques to mitigate communication costs, yet computational and memory burdens continue to pose significant challenges for developers. This work proposes DropPEFT, an innovative federated PEFT framework that employs a novel stochastic transformer layer dropout method, enabling devices to deactivate a considerable fraction of LLMs layers during training, thereby eliminating the associated computational load and memory footprint. In DropPEFT, a key challenge is the proper configuration of dropout ratios for layers, as overhead and training performance are highly sensitive to this setting. To address this challenge, we adaptively assign optimal dropout-ratio configurations to devices through an exploration-exploitation strategy, achieving efficient and effective fine-tuning. Extensive experiments show that DropPEFT can achieve a 1.3-6.3\times speedup in model convergence and a 40%-67% reduction in memory footprint compared to state-of-the-art methods.
A Robust Federated Learning Framework for Undependable Devices at Scale
Dec 28, 2024In a federated learning (FL) system, many devices, such as smartphones, are often undependable (e.g., frequently disconnected from WiFi) during training. Existing FL frameworks always assume a dependable environment and exclude undependable devices from training, leading to poor model performance and resource wastage. In this paper, we propose FLUDE to effectively deal with undependable environments. First, FLUDE assesses the dependability of devices based on the probability distribution of their historical behaviors (e.g., the likelihood of successfully completing training). Based on this assessment, FLUDE adaptively selects devices with high dependability for training. To mitigate resource wastage during the training phase, FLUDE maintains a model cache on each device, aiming to preserve the latest training state for later use in case local training on an undependable device is interrupted. Moreover, FLUDE proposes a staleness-aware strategy to judiciously distribute the global model to a subset of devices, thus significantly reducing resource wastage while maintaining model performance. We have implemented FLUDE on two physical platforms with 120 smartphones and NVIDIA Jetson devices. Extensive experimental results demonstrate that FLUDE can effectively improve model performance and resource efficiency of FL training in undependable environments.
Enhancing Federated Graph Learning via Adaptive Fusion of Structural and Node Characteristics
Dec 25, 2024



Federated Graph Learning (FGL) has demonstrated the advantage of training a global Graph Neural Network (GNN) model across distributed clients using their local graph data. Unlike Euclidean data (\eg, images), graph data is composed of nodes and edges, where the overall node-edge connections determine the topological structure, and individual nodes along with their neighbors capture local node features. However, existing studies tend to prioritize one aspect over the other, leading to an incomplete understanding of the data and the potential misidentification of key characteristics across varying graph scenarios. Additionally, the non-independent and identically distributed (non-IID) nature of graph data makes the extraction of these two data characteristics even more challenging. To address the above issues, we propose a novel FGL framework, named FedGCF, which aims to simultaneously extract and fuse structural properties and node features to effectively handle diverse graph scenarios. FedGCF first clusters clients by structural similarity, performing model aggregation within each cluster to form the shared structural model. Next, FedGCF selects the clients with common node features and aggregates their models to generate a common node model. This model is then propagated to all clients, allowing common node features to be shared. By combining these two models with a proper ratio, FedGCF can achieve a comprehensive understanding of the graph data and deliver better performance, even under non-IID distributions. Experimental results show that FedGCF improves accuracy by 4.94%-7.24% under different data distributions and reduces communication cost by 64.18%-81.25% to reach the same accuracy compared to baselines.
NetSafe: Exploring the Topological Safety of Multi-agent Networks
Oct 21, 2024
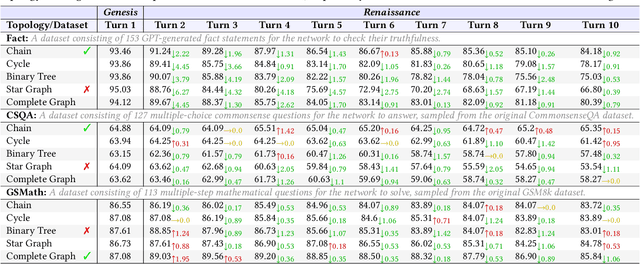
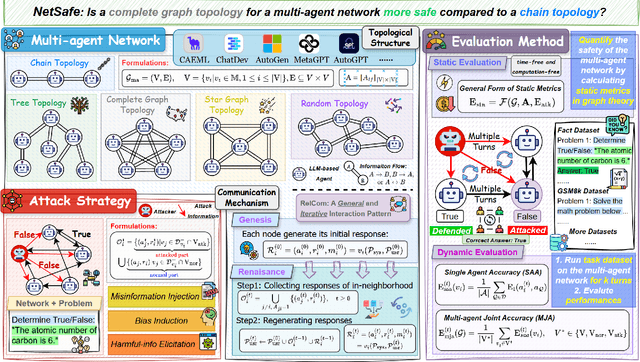
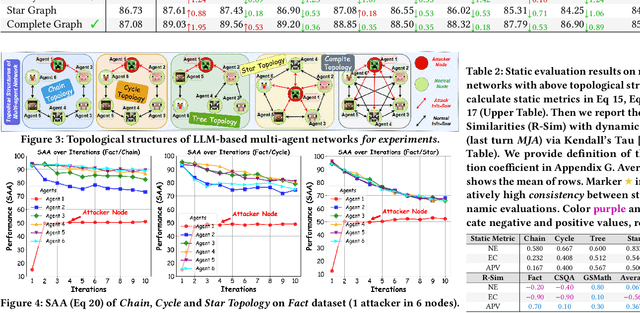
Large language models (LLMs) have empowered nodes within multi-agent networks with intelligence, showing growing applications in both academia and industry. However, how to prevent these networks from generating malicious information remains unexplored with previous research on single LLM's safety be challenging to transfer. In this paper, we focus on the safety of multi-agent networks from a topological perspective, investigating which topological properties contribute to safer networks. To this end, we propose a general framework, NetSafe along with an iterative RelCom interaction to unify existing diverse LLM-based agent frameworks, laying the foundation for generalized topological safety research. We identify several critical phenomena when multi-agent networks are exposed to attacks involving misinformation, bias, and harmful information, termed as Agent Hallucination and Aggregation Safety. Furthermore, we find that highly connected networks are more susceptible to the spread of adversarial attacks, with task performance in a Star Graph Topology decreasing by 29.7%. Besides, our proposed static metrics aligned more closely with real-world dynamic evaluations than traditional graph-theoretic metrics, indicating that networks with greater average distances from attackers exhibit enhanced safety. In conclusion, our work introduces a new topological perspective on the safety of LLM-based multi-agent networks and discovers several unreported phenomena, paving the way for future research to explore the safety of such networks.
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Jun 12, 2024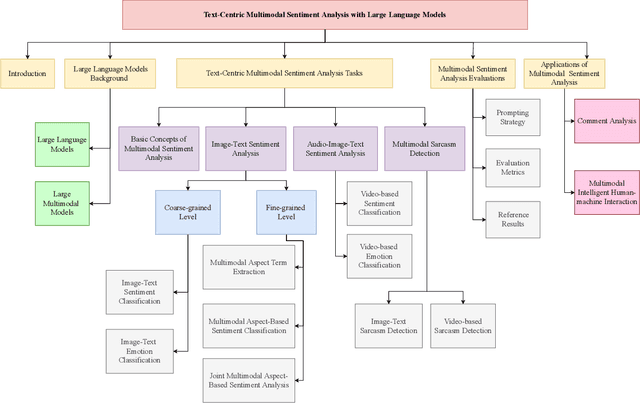
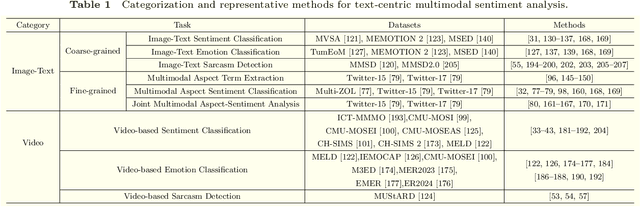
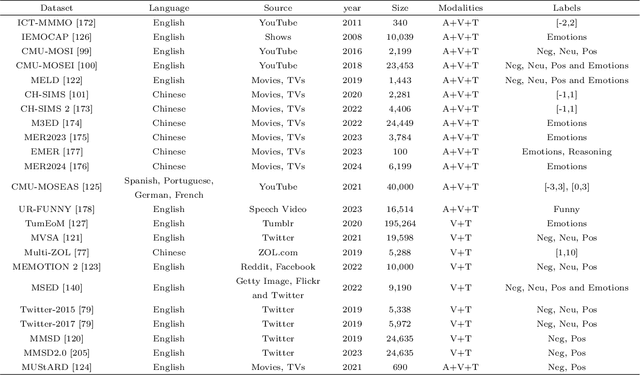

Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
All Nodes are created Not Equal: Node-Specific Layer Aggregation and Filtration for GNN
May 13, 2024The ever-designed Graph Neural Networks, though opening a promising path for the modeling of the graph-structure data, unfortunately introduce two daunting obstacles to their deployment on devices. (I) Most of existing GNNs are shallow, due mostly to the over-smoothing and gradient-vanish problem as they go deeper as convolutional architectures. (II) The vast majority of GNNs adhere to the homophily assumption, where the central node and its adjacent nodes share the same label. This assumption often poses challenges for many GNNs working with heterophilic graphs. Addressing the aforementioned issue has become a looming challenge in enhancing the robustness and scalability of GNN applications. In this paper, we take a comprehensive and systematic approach to overcoming the two aforementioned challenges for the first time. We propose a Node-Specific Layer Aggregation and Filtration architecture, termed NoSAF, a framework capable of filtering and processing information from each individual nodes. NoSAF introduces the concept of "All Nodes are Created Not Equal" into every layer of deep networks, aiming to provide a reliable information filter for each layer's nodes to sieve out information beneficial for the subsequent layer. By incorporating a dynamically updated codebank, NoSAF dynamically optimizes the optimal information outputted downwards at each layer. This effectively overcomes heterophilic issues and aids in deepening the network. To compensate for the information loss caused by the continuous filtering in NoSAF, we also propose NoSAF-D (Deep), which incorporates a compensation mechanism that replenishes information in every layer of the model, allowing NoSAF to perform meaningful computations even in very deep layers.
CaT-GNN: Enhancing Credit Card Fraud Detection via Causal Temporal Graph Neural Networks
Feb 22, 2024



Credit card fraud poses a significant threat to the economy. While Graph Neural Network (GNN)-based fraud detection methods perform well, they often overlook the causal effect of a node's local structure on predictions. This paper introduces a novel method for credit card fraud detection, the \textbf{\underline{Ca}}usal \textbf{\underline{T}}emporal \textbf{\underline{G}}raph \textbf{\underline{N}}eural \textbf{N}etwork (CaT-GNN), which leverages causal invariant learning to reveal inherent correlations within transaction data. By decomposing the problem into discovery and intervention phases, CaT-GNN identifies causal nodes within the transaction graph and applies a causal mixup strategy to enhance the model's robustness and interpretability. CaT-GNN consists of two key components: Causal-Inspector and Causal-Intervener. The Causal-Inspector utilizes attention weights in the temporal attention mechanism to identify causal and environment nodes without introducing additional parameters. Subsequently, the Causal-Intervener performs a causal mixup enhancement on environment nodes based on the set of nodes. Evaluated on three datasets, including a private financial dataset and two public datasets, CaT-GNN demonstrates superior performance over existing state-of-the-art methods. Our findings highlight the potential of integrating causal reasoning with graph neural networks to improve fraud detection capabilities in financial transactions.
Both Matter: Enhancing the Emotional Intelligence of Large Language Models without Compromising the General Intelligence
Feb 15, 2024
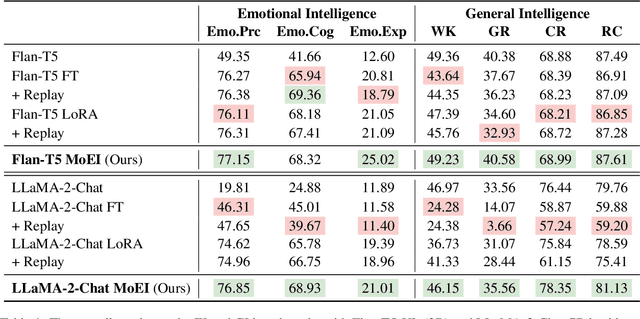


Emotional Intelligence (EI), consisting of emotion perception, emotion cognition and emotion expression, plays the critical roles in improving user interaction experience for the current large language model (LLM) based conversational general AI assistants. Previous works mainly focus on raising the emotion perception ability of them via naive fine-tuning on EI-related classification or regression tasks. However, this leads to the incomplete enhancement of EI and catastrophic forgetting of the general intelligence (GI). To this end, we first introduce \textsc{EiBench}, a large-scale collection of EI-related tasks in the text-to-text formation with task instructions that covers all three aspects of EI, which lays a solid foundation for the comprehensive EI enhancement of LLMs. Then a novel \underline{\textbf{Mo}}dular \underline{\textbf{E}}motional \underline{\textbf{I}}ntelligence enhancement method (\textbf{MoEI}), consisting of Modular Parameter Expansion and intra-inter modulation, is proposed to comprehensively enhance the EI of LLMs without compromise their GI. Extensive experiments on two representative LLM-based assistants, Flan-T5 and LLaMA-2-Chat, demonstrate the effectiveness of MoEI to improving EI while maintain GI.