 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVEN: A Multi-stage Agentic Annotation Pipeline for Video Reasoning Tasks
May 21, 2026Training Vision Language Models (VLMs) for video event reasoning requires high-quality structured annotations capturing not only what happened, but when, where, why, and with what consequence, at a scale manual labelling cannot support. We present MAVEN (Multi-stage Agentic Video Event aNnotation), a multi-stage agentic pipeline that turns raw videos into multi-task training data with Chain-of-Thought (CoT) reasoning traces, organized around a designated Event of Focus. At its core, MAVEN synthesizes a Multi-Scale Spatio-Temporal Event Description (MSTED) from three complementary caption levels; this explicit intermediate serves as the sole input to downstream Q&A generation across multiple task formats. Crucially, MAVEN supports agent-driven domain adaptation: given a new video dataset and target question examples, the agent redesigns all prompts top-down without manual re-engineering. A hierarchical refinement loop further classifies annotation errors against a taxonomy, traces root causes to the originating pipeline stage, and applies targeted edits that rewrite prompts or modify the pipeline structure itself, iteratively improving data quality. We apply MAVEN to label over 5,300 traffic videos and fine-tune Cosmos-Reason2-8B on the resulting data. On a private CCTV evaluation set, fine-tuning surpasses both Gemini 2.5 Pro and 3.1 Flash, including a $+38.8$-point gain in MCQ accuracy over zero-shot. On AccidentBench, CCTV-only training lifts Cosmos-Reason2 by $+10.7$ MCQ points and matches Gemini 2.5 Pro despite seeing no dashcam videos; adding agent-adapted dashcam annotations narrows the gap to Gemini 3.1 Flash, and RL post-training pushes overall performance past both Gemini baselines. Qualitative results on warehouse surveillance and public safety videos further show the agentic workflow readily adapts the pipeline to new domains.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
"Rebuilding" Statistics in the Age of AI: A Town Hall Discussion on Culture, Infrastructure, and Training
Jan 24, 2026This article presents the full, original record of the 2024 Joint Statistical Meetings (JSM) town hall, "Statistics in the Age of AI," which convened leading statisticians to discuss how the field is evolving in response to advances in artificial intelligence, foundation models, large-scale empirical modeling, and data-intensive infrastructures. The town hall was structured around open panel discussion and extensive audience Q&A, with the aim of eliciting candid, experience-driven perspectives rather than formal presentations or prepared statements. This document preserves the extended exchanges among panelists and audience members, with minimal editorial intervention, and organizes the conversation around five recurring questions concerning disciplinary culture and practices, data curation and "data work," engagement with modern empirical modeling, training for large-scale AI applications, and partnerships with key AI stakeholders. By providing an archival record of this discussion, the preprint aims to support transparency, community reflection, and ongoing dialogue about the evolving role of statistics in the data- and AI-centric future.
BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
Dec 12, 2025The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the standard attention mechanism. To address this challenge, we introduce BLASST, a drop-in sparse attention method that dynamically prunes the attention matrix without any pre-computation or proxy scores. Our method uses a fixed threshold and existing information from online softmax to identify negligible attention scores, skipping softmax computation, Value block loading, and the subsequent matrix multiplication. This fits seamlessly into existing FlashAttention kernel designs with negligible latency overhead. The approach is applicable to both prefill and decode stages across all attention variants (MHA, GQA, MQA, and MLA), providing a unified solution for accelerating long-context inference. We develop an automated calibration procedure that reveals a simple inverse relationship between optimal threshold and context length, enabling robust deployment across diverse scenarios. Maintaining high accuracy, we demonstrate a 1.62x speedup for prefill at 74.7% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs. Furthermore, we explore sparsity-aware training as a natural extension, showing that models can be trained to be inherently more robust to sparse attention patterns, pushing the accuracy-sparsity frontier even further.
Power Ensemble Aggregation for Improved Extreme Event AI Prediction
Nov 14, 2025This paper addresses the critical challenge of improving predictions of climate extreme events, specifically heat waves, using machine learning methods. Our work is framed as a classification problem in which we try to predict whether surface air temperature will exceed its q-th local quantile within a specified timeframe. Our key finding is that aggregating ensemble predictions using a power mean significantly enhances the classifier's performance. By making a machine-learning based weather forecasting model generative and applying this non-linear aggregation method, we achieve better accuracy in predicting extreme heat events than with the typical mean prediction from the same model. Our power aggregation method shows promise and adaptability, as its optimal performance varies with the quantile threshold chosen, demonstrating increased effectiveness for higher extremes prediction.
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Jun 12, 2024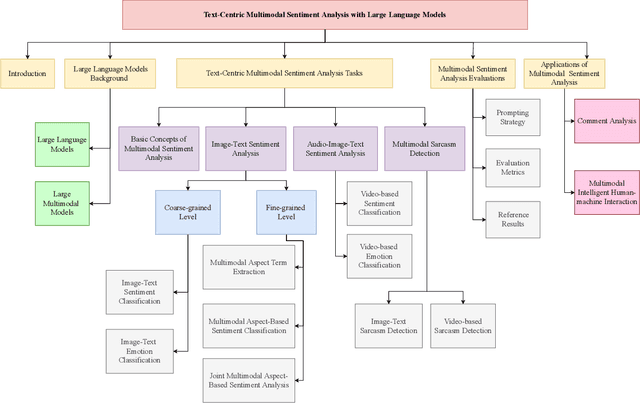
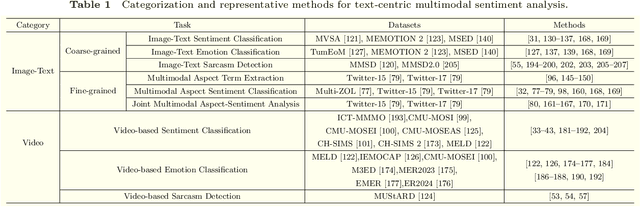
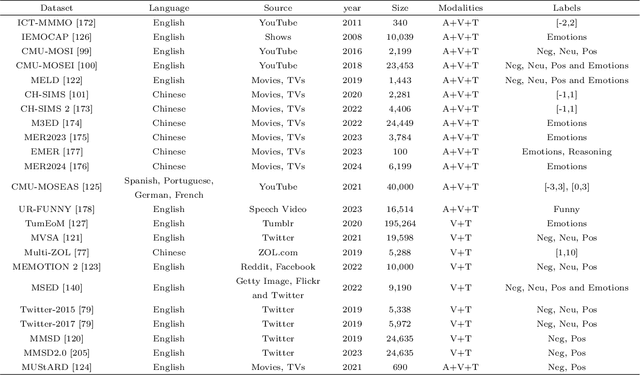

Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
An Early Evaluation of GPT-4V(ision)
Oct 25, 2023



In this paper, we evaluate different abilities of GPT-4V including visual understanding, language understanding, visual puzzle solving, and understanding of other modalities such as depth, thermal, video, and audio. To estimate GPT-4V's performance, we manually construct 656 test instances and carefully evaluate the results of GPT-4V. The highlights of our findings are as follows: (1) GPT-4V exhibits impressive performance on English visual-centric benchmarks but fails to recognize simple Chinese texts in the images; (2) GPT-4V shows inconsistent refusal behavior when answering questions related to sensitive traits such as gender, race, and age; (3) GPT-4V obtains worse results than GPT-4 (API) on language understanding tasks including general language understanding benchmarks and visual commonsense knowledge evaluation benchmarks; (4) Few-shot prompting can improve GPT-4V's performance on both visual understanding and language understanding; (5) GPT-4V struggles to find the nuances between two similar images and solve the easy math picture puzzles; (6) GPT-4V shows non-trivial performance on the tasks of similar modalities to image, such as video and thermal. Our experimental results reveal the ability and limitations of GPT-4V and we hope our paper can provide some insights into the application and research of GPT-4V.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Wasserstein Distributional Learning
Sep 12, 2022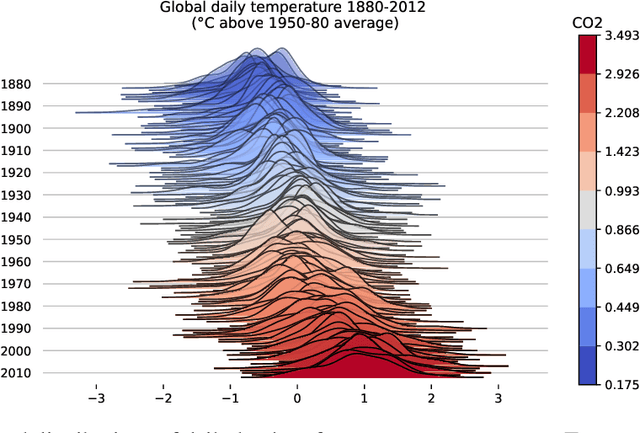

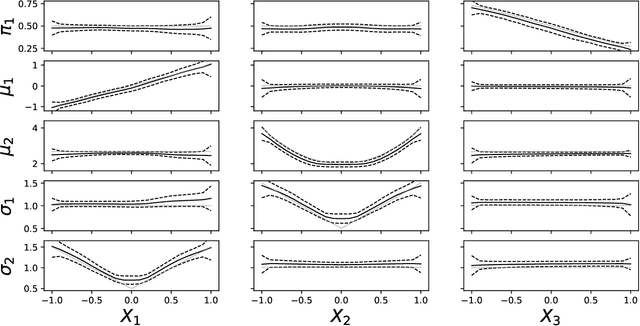
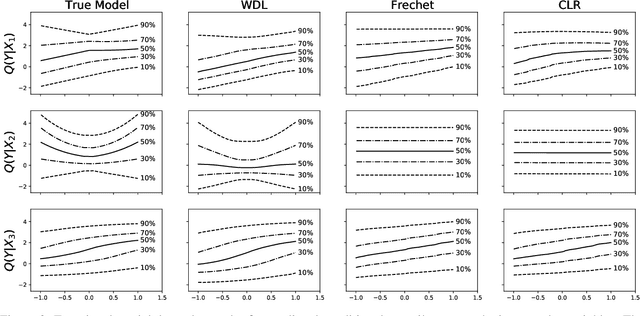
Learning conditional densities and identifying factors that influence the entire distribution are vital tasks in data-driven applications. Conventional approaches work mostly with summary statistics, and are hence inadequate for a comprehensive investigation. Recently, there have been developments on functional regression methods to model density curves as functional outcomes. A major challenge for developing such models lies in the inherent constraint of non-negativity and unit integral for the functional space of density outcomes. To overcome this fundamental issue, we propose Wasserstein Distributional Learning (WDL), a flexible density-on-scalar regression modeling framework that starts with the Wasserstein distance $W_2$ as a proper metric for the space of density outcomes. We then introduce a heterogeneous and flexible class of Semi-parametric Conditional Gaussian Mixture Models (SCGMM) as the model class $\mathfrak{F} \otimes \mathcal{T}$. The resulting metric space $(\mathfrak{F} \otimes \mathcal{T}, W_2)$ satisfies the required constraints and offers a dense and closed functional subspace. For fitting the proposed model, we further develop an efficient algorithm based on Majorization-Minimization optimization with boosted trees. Compared with methods in the previous literature, WDL better characterizes and uncovers the nonlinear dependence of the conditional densities, and their derived summary statistics. We demonstrate the effectiveness of the WDL framework through simulations and real-world applications.
Toward a Taxonomy of Trust for Probabilistic Machine Learning
Dec 05, 2021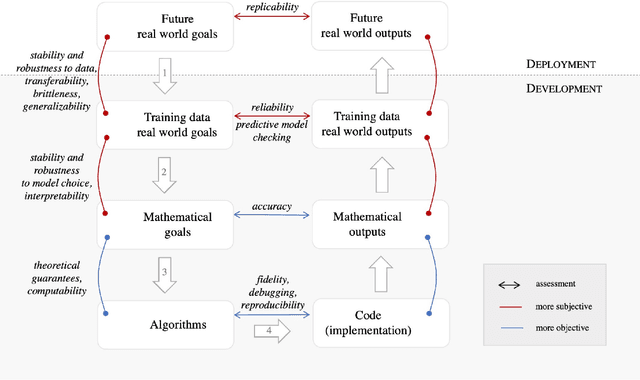
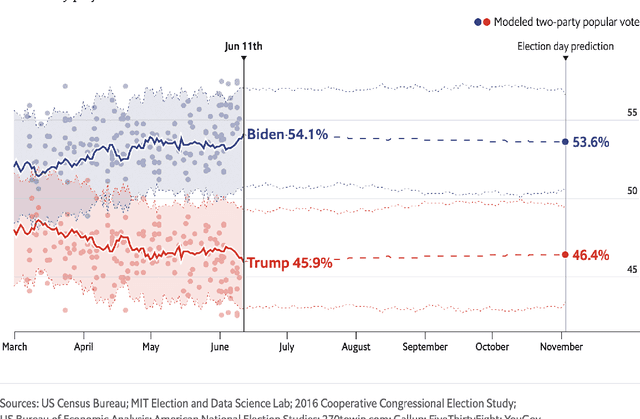
Probabilistic machine learning increasingly informs critical decisions in medicine, economics, politics, and beyond. We need evidence to support that the resulting decisions are well-founded. To aid development of trust in these decisions, we develop a taxonomy delineating where trust in an analysis can break down: (1) in the translation of real-world goals to goals on a particular set of available training data, (2) in the translation of abstract goals on the training data to a concrete mathematical problem, (3) in the use of an algorithm to solve the stated mathematical problem, and (4) in the use of a particular code implementation of the chosen algorithm. We detail how trust can fail at each step and illustrate our taxonomy with two case studies: an analysis of the efficacy of microcredit and The Economist's predictions of the 2020 US presidential election. Finally, we describe a wide variety of methods that can be used to increase trust at each step of our taxonomy. The use of our taxonomy highlights steps where existing research work on trust tends to concentrate and also steps where establishing trust is particularly challenging.