 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Distributional Learning
Sep 12, 2022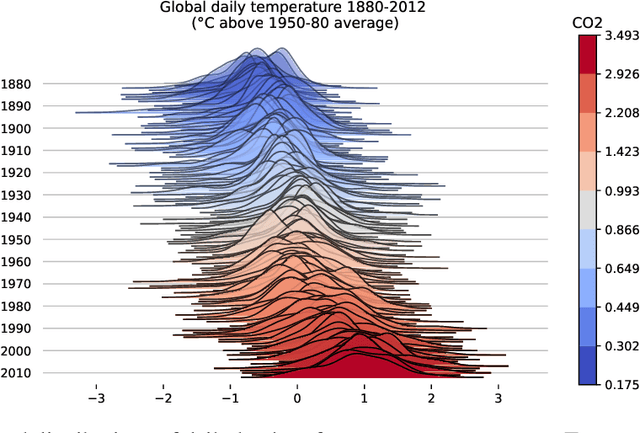

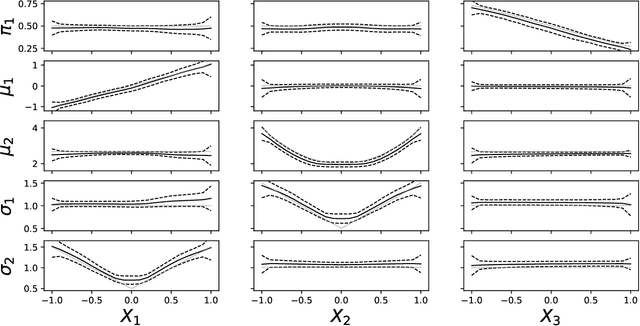
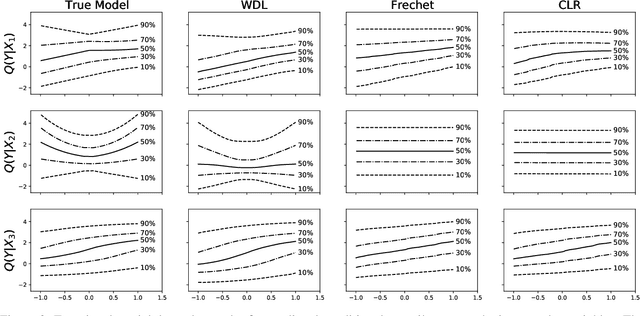
Learning conditional densities and identifying factors that influence the entire distribution are vital tasks in data-driven applications. Conventional approaches work mostly with summary statistics, and are hence inadequate for a comprehensive investigation. Recently, there have been developments on functional regression methods to model density curves as functional outcomes. A major challenge for developing such models lies in the inherent constraint of non-negativity and unit integral for the functional space of density outcomes. To overcome this fundamental issue, we propose Wasserstein Distributional Learning (WDL), a flexible density-on-scalar regression modeling framework that starts with the Wasserstein distance $W_2$ as a proper metric for the space of density outcomes. We then introduce a heterogeneous and flexible class of Semi-parametric Conditional Gaussian Mixture Models (SCGMM) as the model class $\mathfrak{F} \otimes \mathcal{T}$. The resulting metric space $(\mathfrak{F} \otimes \mathcal{T}, W_2)$ satisfies the required constraints and offers a dense and closed functional subspace. For fitting the proposed model, we further develop an efficient algorithm based on Majorization-Minimization optimization with boosted trees. Compared with methods in the previous literature, WDL better characterizes and uncovers the nonlinear dependence of the conditional densities, and their derived summary statistics. We demonstrate the effectiveness of the WDL framework through simulations and real-world applications.
Weakly Supervised Learning Creates a Fusion of Modeling Cultures
Jun 02, 2021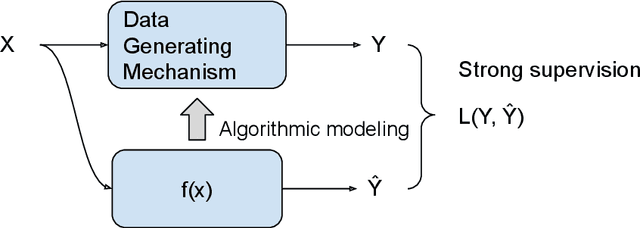
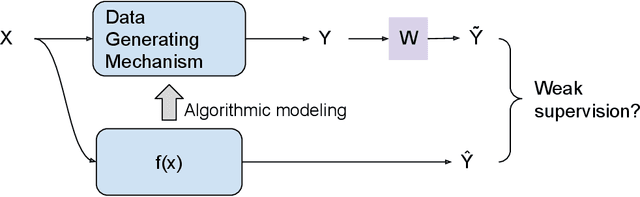
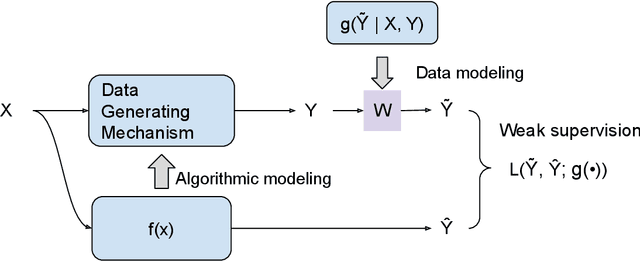
The past two decades have witnessed the great success of the algorithmic modeling framework advocated by Breiman et al. (2001). Nevertheless, the excellent prediction performance of these black-box models rely heavily on the availability of strong supervision, i.e. a large set of accurate and exact ground-truth labels. In practice, strong supervision can be unavailable or expensive, which calls for modeling techniques under weak supervision. In this comment, we summarize the key concepts in weakly supervised learning and discuss some recent developments in the field. Using algorithmic modeling alone under a weak supervision might lead to unstable and misleading results. A promising direction would be integrating the data modeling culture into such a framework.
Artificial Perceptual Learning: Image Categorization with Weak Supervision
Jun 02, 2021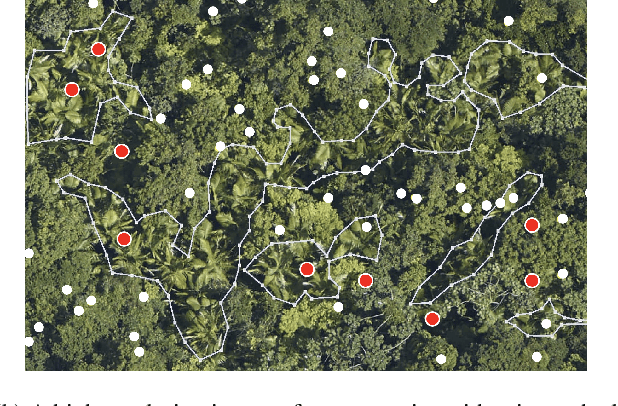
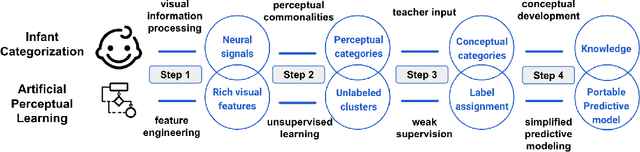

Machine learning has achieved much success on supervised learning tasks with large sets of well-annotated training samples. However, in many practical situations, such strong and high-quality supervision provided by training data is unavailable due to the expensive and labor-intensive labeling process. Automatically identifying and recognizing object categories in a large volume of unlabeled images with weak supervision remains an important, yet unsolved challenge in computer vision. In this paper, we propose a novel machine learning framework, artificial perceptual learning (APL), to tackle the problem of weakly supervised image categorization. The proposed APL framework is constructed using state-of-the-art machine learning algorithms as building blocks to mimic the cognitive development process known as infant categorization. We develop and illustrate the proposed framework by implementing a wide-field fine-grain ecological survey of tree species over an 8,000-hectare area of the El Yunque rainforest in Puerto Rico. It is based on unlabeled high-resolution aerial images of the tree canopy. Misplaced ground-based labels were available for less than 1% of these images, which serve as the only weak supervision for this learning framework. We validate the proposed framework using a small set of images with high quality human annotations and show that the proposed framework attains human-level cognitive economy.