 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Balance Convenience and Nutrition in Meals With Long-Term Group Recommendations and Reasoning on Multimodal Recipes and its Implementation in BEACON
Dec 23, 2024



"A common decision made by people, whether healthy or with health conditions, is choosing meals like breakfast, lunch, and dinner, comprising combinations of foods for appetizer, main course, side dishes, desserts, and beverages. Often, this decision involves tradeoffs between nutritious choices (e.g., salt and sugar levels, nutrition content) and convenience (e.g., cost and accessibility, cuisine type, food source type). We present a data-driven solution for meal recommendations that considers customizable meal configurations and time horizons. This solution balances user preferences while accounting for food constituents and cooking processes. Our contributions include introducing goodness measures, a recipe conversion method from text to the recently introduced multimodal rich recipe representation (R3) format, learning methods using contextual bandits that show promising preliminary results, and the prototype, usage-inspired, BEACON system."
PixRO: Pixel-Distributed Rotational Odometry with Gaussian Belief Propagation
Jun 14, 2024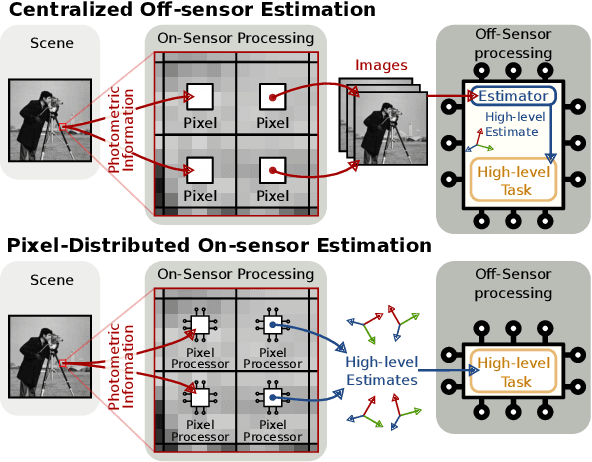
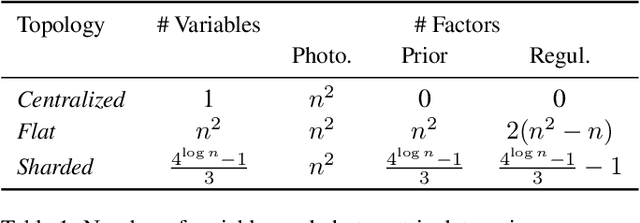
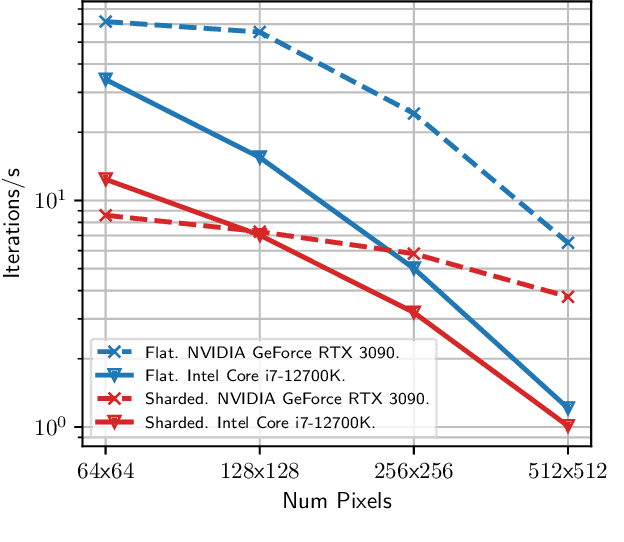
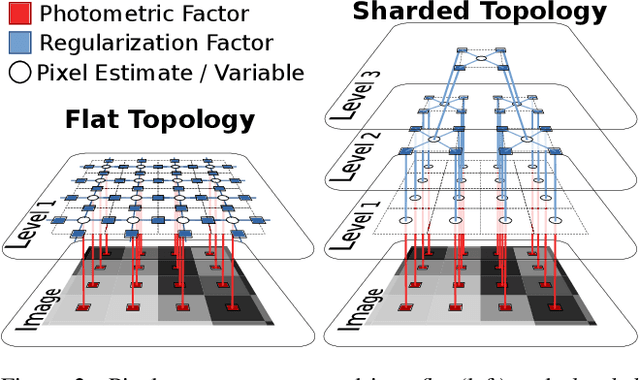
Visual sensors are not only becoming better at capturing high-quality images but also they have steadily increased their capabilities in processing data on their own on-chip. Yet the majority of VO pipelines rely on the transmission and processing of full images in a centralized unit (e.g. CPU or GPU), which often contain much redundant and low-quality information for the task. In this paper, we address the task of frame-to-frame rotational estimation but, instead of reasoning about relative motion between frames using the full images, distribute the estimation at pixel-level. In this paradigm, each pixel produces an estimate of the global motion by only relying on local information and local message-passing with neighbouring pixels. The resulting per-pixel estimates can then be communicated to downstream tasks, yielding higher-level, informative cues instead of the original raw pixel-readings. We evaluate the proposed approach on real public datasets, where we offer detailed insights about this novel technique and open-source our implementation for the future benefit of the community.
Community Detection and Classification Guarantees Using Embeddings Learned by Node2Vec
Oct 26, 2023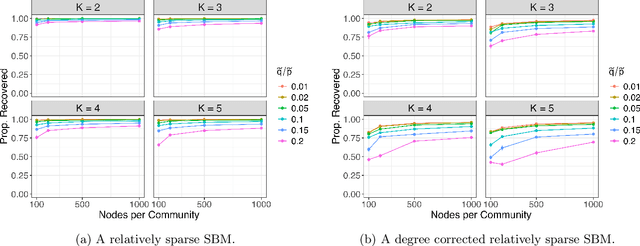
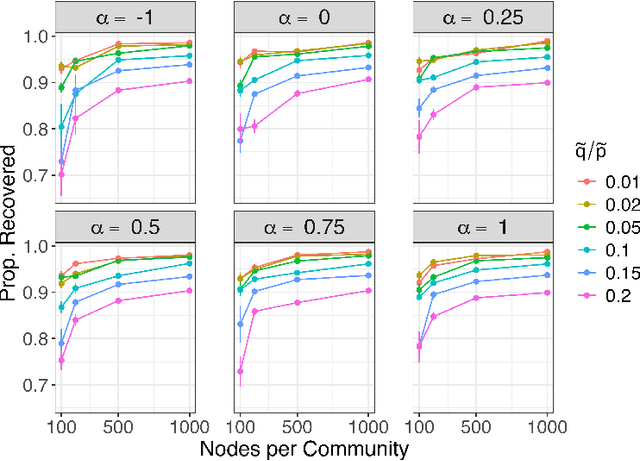
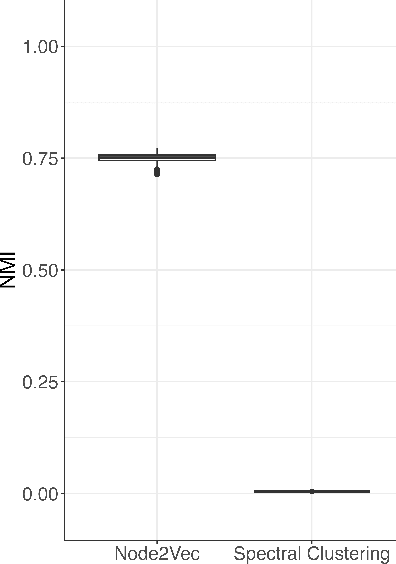
Embedding the nodes of a large network into an Euclidean space is a common objective in modern machine learning, with a variety of tools available. These embeddings can then be used as features for tasks such as community detection/node clustering or link prediction, where they achieve state of the art performance. With the exception of spectral clustering methods, there is little theoretical understanding for other commonly used approaches to learning embeddings. In this work we examine the theoretical properties of the embeddings learned by node2vec. Our main result shows that the use of k-means clustering on the embedding vectors produced by node2vec gives weakly consistent community recovery for the nodes in (degree corrected) stochastic block models. We also discuss the use of these embeddings for node and link prediction tasks. We demonstrate this result empirically, and examine how this relates to other embedding tools for network data.
Asymptotics of $\ell_2$ Regularized Network Embeddings
Jan 05, 2022
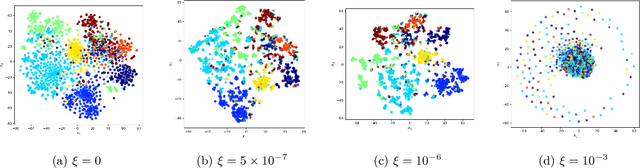
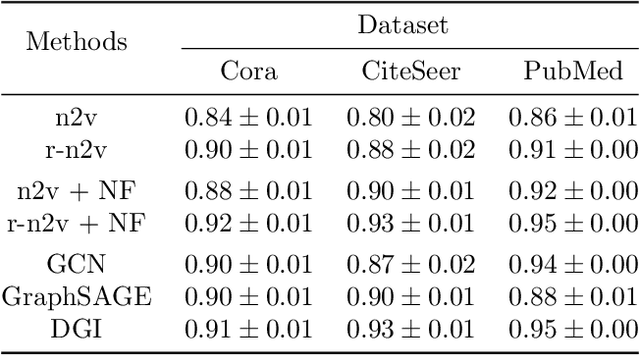
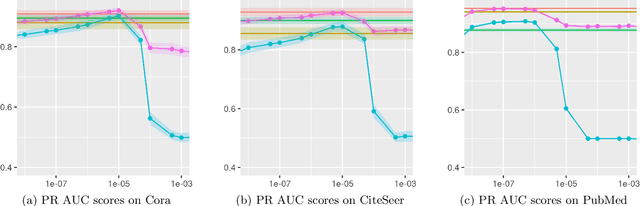
A common approach to solving tasks, such as node classification or link prediction, on a large network begins by learning a Euclidean embedding of the nodes of the network, from which regular machine learning methods can be applied. For unsupervised random walk methods such as DeepWalk and node2vec, adding a $\ell_2$ penalty on the embedding vectors to the loss leads to improved downstream task performance. In this paper we study the effects of this regularization and prove that, under exchangeability assumptions on the graph, it asymptotically leads to learning a nuclear-norm-type penalized graphon. In particular, the exact form of the penalty depends on the choice of subsampling method used within stochastic gradient descent to learn the embeddings. We also illustrate empirically that concatenating node covariates to $\ell_2$ regularized node2vec embeddings leads to comparable, if not superior, performance to methods which incorporate node covariates and the network structure in a non-linear manner.
Asymptotics of Network Embeddings Learned via Subsampling
Jul 06, 2021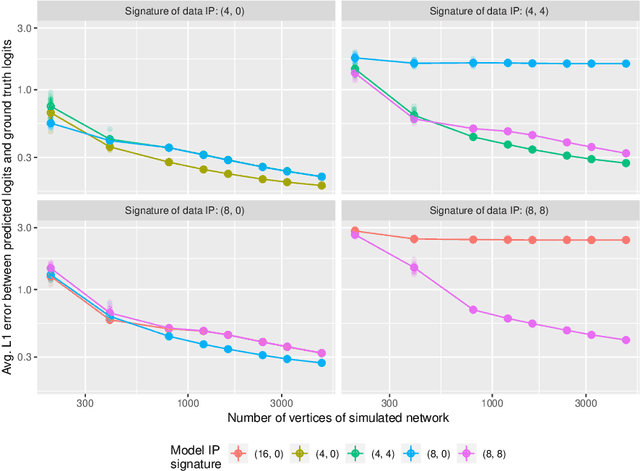
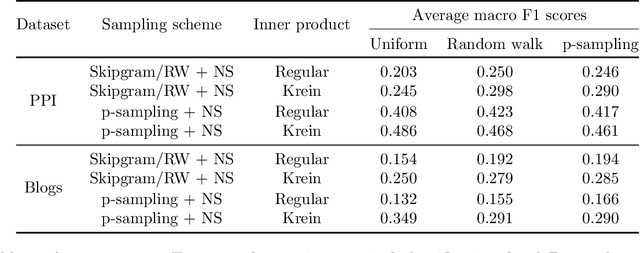
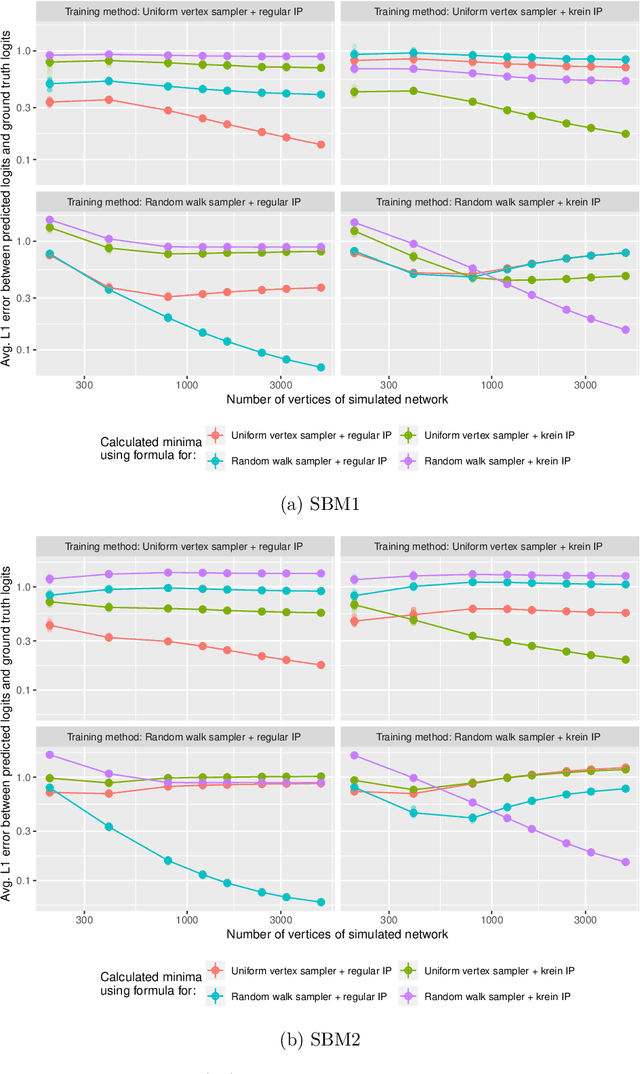
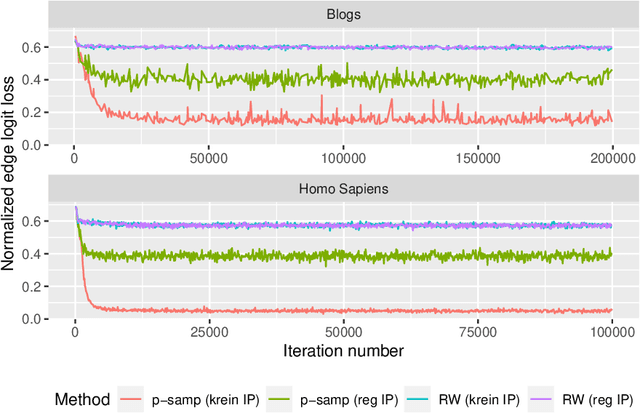
Network data are ubiquitous in modern machine learning, with tasks of interest including node classification, node clustering and link prediction. A frequent approach begins by learning an Euclidean embedding of the network, to which algorithms developed for vector-valued data are applied. For large networks, embeddings are learned using stochastic gradient methods where the sub-sampling scheme can be freely chosen. Despite the strong empirical performance of such methods, they are not well understood theoretically. Our work encapsulates representation methods using a subsampling approach, such as node2vec, into a single unifying framework. We prove, under the assumption that the graph is exchangeable, that the distribution of the learned embedding vectors asymptotically decouples. Moreover, we characterize the asymptotic distribution and provided rates of convergence, in terms of the latent parameters, which includes the choice of loss function and the embedding dimension. This provides a theoretical foundation to understand what the embedding vectors represent and how well these methods perform on downstream tasks. Notably, we observe that typically used loss functions may lead to shortcomings, such as a lack of Fisher consistency.
Next Waves in Veridical Network Embedding
Jul 10, 2020
Embedding nodes of a large network into a metric (e.g., Euclidean) space has become an area of active research in statistical machine learning, which has found applications in natural and social sciences. Generally, a representation of a network object is learned in a Euclidean geometry and is then used for subsequent tasks regarding the nodes and/or edges of the network, such as community detection, node classification and link prediction. Network embedding algorithms have been proposed in multiple disciplines, often with domain-specific notations and details. In addition, different measures and tools have been adopted to evaluate and compare the methods proposed under different settings, often dependent of the downstream tasks. As a result, it is challenging to study these algorithms in the literature systematically. Motivated by the recently proposed Veridical Data Science (VDS) framework, we propose a framework for network embedding algorithms and discuss how the principles of predictability, computability and stability apply in this context. The utilization of this framework in network embedding holds the potential to motivate and point to new directions for future research.
Neural Object Descriptors for Multi-View Shape Reconstruction
Apr 09, 2020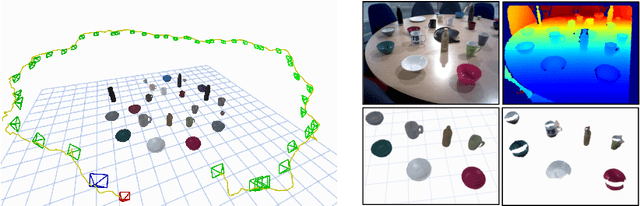
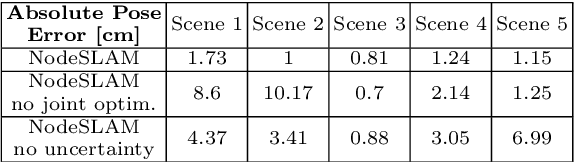
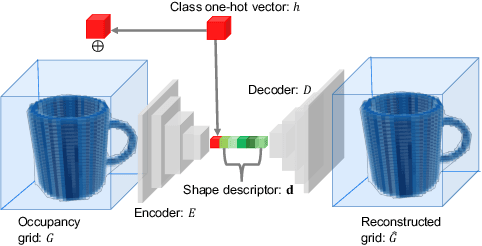
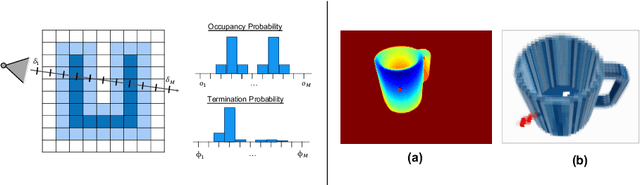
The choice of scene representation is crucial in both the shape inference algorithms it requires and the smart applications it enables. We present efficient and optimisable multi-class learned object descriptors together with a novel probabilistic and differential rendering engine, for principled full object shape inference from one or more RGB-D images. Our framework allows for accurate and robust 3D object reconstruction which enables multiple applications including robot grasping and placing, augmented reality, and the first object-level SLAM system capable of optimising object poses and shapes jointly with camera trajectory.
Comparing View-Based and Map-Based Semantic Labelling in Real-Time SLAM
Feb 24, 2020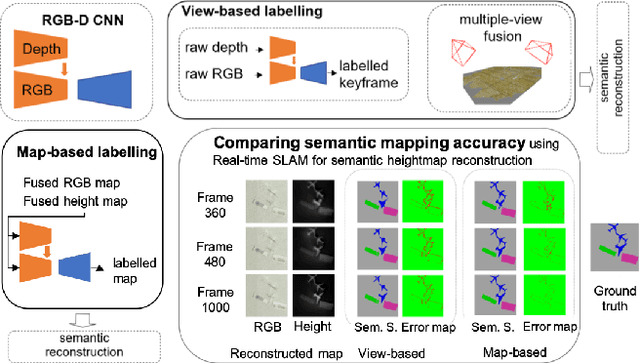
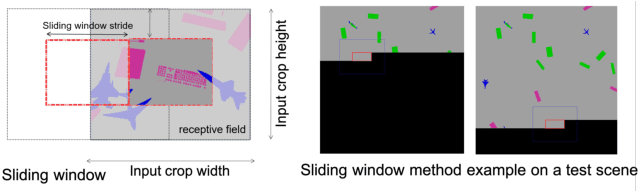
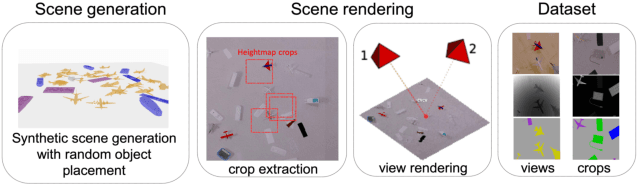
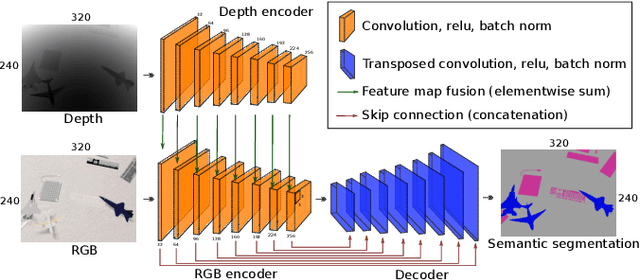
Generally capable Spatial AI systems must build persistent scene representations where geometric models are combined with meaningful semantic labels. The many approaches to labelling scenes can be divided into two clear groups: view-based which estimate labels from the input view-wise data and then incrementally fuse them into the scene model as it is built; and map-based which label the generated scene model. However, there has so far been no attempt to quantitatively compare view-based and map-based labelling. Here, we present an experimental framework and comparison which uses real-time height map fusion as an accessible platform for a fair comparison, opening up the route to further systematic research in this area.
Event-based Vision: A Survey
Apr 17, 2019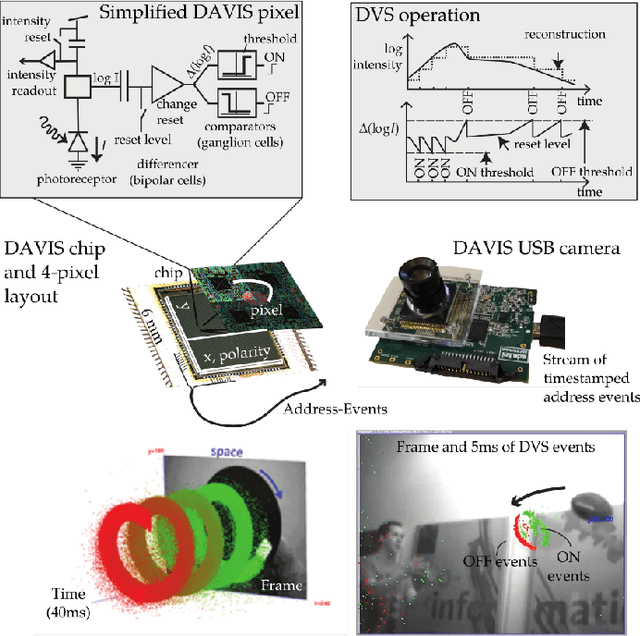
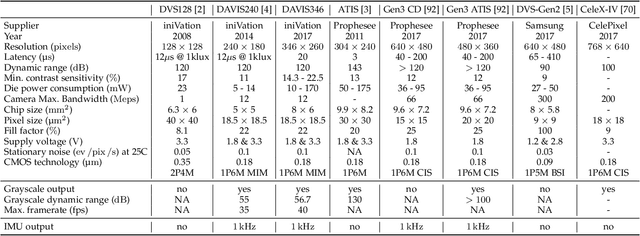
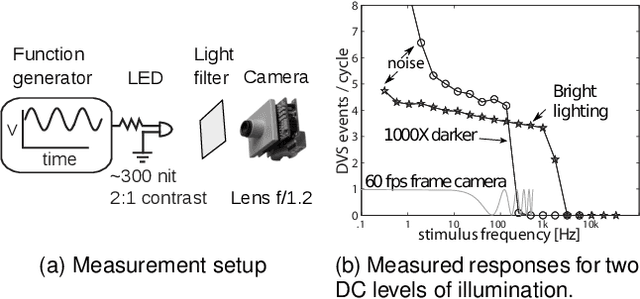
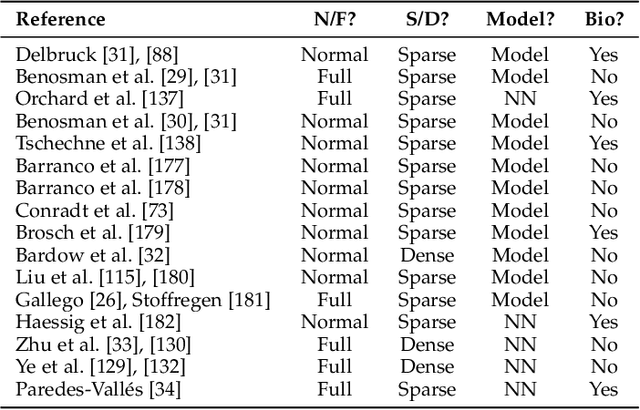
Event cameras are bio-inspired sensors that work radically different from traditional cameras. Instead of capturing images at a fixed rate, they measure per-pixel brightness changes asynchronously. This results in a stream of events, which encode the time, location and sign of the brightness changes. Event cameras posses outstanding properties compared to traditional cameras: very high dynamic range (140 dB vs. 60 dB), high temporal resolution (in the order of microseconds), low power consumption, and do not suffer from motion blur. Hence, event cameras have a large potential for robotics and computer vision in challenging scenarios for traditional cameras, such as high speed and high dynamic range. However, novel methods are required to process the unconventional output of these sensors in order to unlock their potential. This paper provides a comprehensive overview of the emerging field of event-based vision, with a focus on the applications and the algorithms developed to unlock the outstanding properties of event cameras. We present event cameras from their working principle, the actual sensors that are available and the tasks that they have been used for, from low-level vision (feature detection and tracking, optic flow, etc.) to high-level vision (reconstruction, segmentation, recognition). We also discuss the techniques developed to process events, including learning-based techniques, as well as specialized processors for these novel sensors, such as spiking neural networks. Additionally, we highlight the challenges that remain to be tackled and the opportunities that lie ahead in the search for a more efficient, bio-inspired way for machines to perceive and interact with the world.
MID-Fusion: Octree-based Object-Level Multi-Instance Dynamic SLAM
Mar 21, 2019
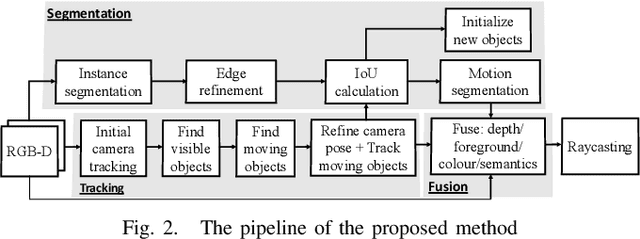
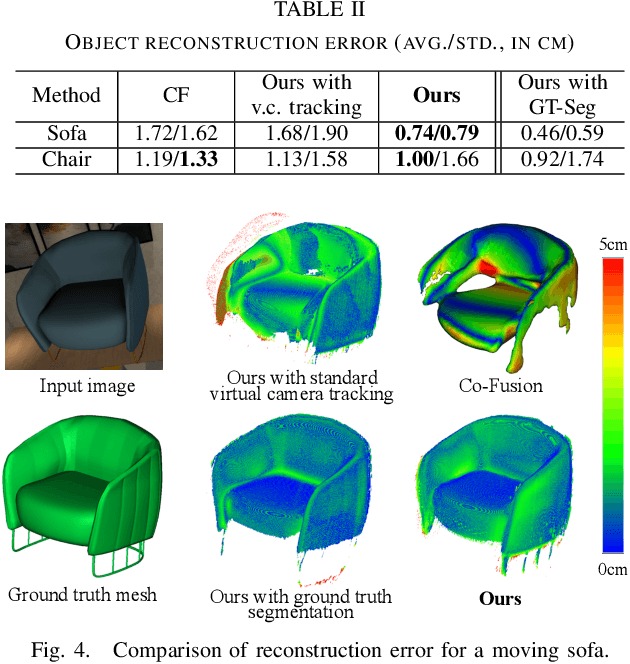

We propose a new multi-instance dynamic RGB-D SLAM system using an object-level octree-based volumetric representation. It can provide robust camera tracking in dynamic environments and at the same time, continuously estimate geometric, semantic, and motion properties for arbitrary objects in the scene. For each incoming frame, we perform instance segmentation to detect objects and refine mask boundaries using geometric and motion information. Meanwhile, we estimate the pose of each existing moving object using an object-oriented tracking method and robustly track the camera pose against the static scene. Based on the estimated camera pose and object poses, we associate segmented masks with existing models and incrementally fuse corresponding colour, depth, semantic, and foreground object probabilities into each object model. In contrast to existing approaches, our system is the first system to generate an object-level dynamic volumetric map from a single RGB-D camera, which can be used directly for robotic tasks. Our method can run at 2-3 Hz on a CPU, excluding the instance segmentation part. We demonstrate its effectiveness by quantitatively and qualitatively testing it on both synthetic and real-world sequences.